General discussion
-
CreatorTopic
-
June 29, 2005 at 6:09 am #2181278
Naren Cool Geek – Tips on .NET and Java development.
Lockedby narendrn · about 18 years, 9 months ago
blog root
This conversation is currently closed to new comments. -
CreatorTopic
All Comments
-
AuthorReplies
-
-
June 29, 2005 at 8:08 am #3177349
C# delegates Vs Java Listeners
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
When I was first introduced to delegates, I found it quite confusing compared to the Java Listener concept. As we know, Java Listeneres use the classic Command design pattern to implement call-backs (implement a standard interface and the method e.g. OnMouseClick())But after understanding delegates, I have realised that delegates are a bit more flexible than Java Listeners. By using a delegate, U are free to use any method of any object- just the signature of the method should match.
They allow easy binding of event handlers and other callback mechanisms, without the use of a separate class implementing a specific listener interface (which is the Java approach for callbacks).
Basically, instead passing a callback function via an object of known interface that both communicating parties agree on, delegates only need the two parties to use the same function signatureAn interesting article regarding this can be found at:
http://blog.monstuff.com/archives/000037.html#more -
June 29, 2005 at 8:08 am #3177350
What’s the difference between the ‘out’ and the ‘ref’ parameters in .NET?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A variable passed as an out argument need not be initialized. However, the out parameter must be assigned a value before the method returns.An argument passed to a ref parameter must first be initialized. Compare this to an ‘out ‘ parameter, whose argument does not have to be explicitly initialized before being passed to an out parameter.
Now the big question is why did Microsoft go thru the pain of having both ‘ref’ and ‘out’ ?
The answer is in the snippet below:
The two parameter passing modes addressed by out and ref are subtly different, however they are both very common. The subtle difference between these modes leads to some very common programming errors.
These include:
not assigning a value to an out parameter in all control flow paths
not assigning a value to variable which is used as a ref parameterBecause the C# language assigns different definite assignment rules to these different parameter passing modes, these common coding errors are caught by the compiler as being incorrect C# code.
The crux of the decision to include both ref and out parameter passing modes was that allowing the compiler to detect these common coding errors was worth the additional complexity of having both ref and out parameter passing modes in the language. -
June 29, 2005 at 8:08 am #3177346
Asynchronous programming in .NET
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The .NET API makes asynchronous programming a breeze….
U can make a async call to any method and what amazed me was the simplicity !!!We just have to make use of the magic of delegates…
Define a delegate with the same signature as the method you want to call; the common language runtime automatically defines BeginInvoke and EndInvoke methods for this delegate, with the appropriate signatures.
The BeginInvoke method is used to initiate the asynchronous call. It has the same parameters as the method you want to execute asynchronously, plus two additional parameters that will be described later. BeginInvoke returns immediately and does not wait for the asynchronous call to complete. BeginInvoke returns an IasyncResult, which can be used to monitor the progress of the call.
The EndInvoke method is used to retrieve the results of the asynchronous call. It can be called any time after BeginInvoke; if the asynchronous call has not completed, EndInvoke will block until it completes. The parameters of EndInvoke include the out and ref parameters (ByRef and ByRef in Visual Basic) of the method you want to execute asynchronously, plus the IAsyncResult returned by BeginInvoke. So after making a Async call, we have the following options:
- Do something and then block till the call completes.
- Poll continously to see it call is complete
- Assign a call-back delegate (AsyncCallBack)
I found this feature of .NET really really cool…especially in my threading applications.
-
June 29, 2005 at 8:08 am #3177347
What is a race condition? How is it different from a dead-lock?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A race condition is a situation in which two or more threads or processes are reading or writing some shared data, and the final result depends on the timing of how the threads are scheduled. Race conditions can lead to unpredictable results and subtle program bugsIn Java, the Object class provides a collection of methods ? wait, notify, and notifyAll ? to help threads wait for a condition and notify other threads when that condition changes.
-
June 29, 2005 at 8:08 am #3177348
XSD.exe — A cool tool in .NET SDK
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
While working on XML-driven applications I often used to dislike writing DTD or Schema files..The syntax was cryptic and difficult to remember.In the .NET SDK, there is a cool tool called XSD.exe that can take a sample XML file and automatically generate a schema-definition file for it.
The following command generates an XML schema from myFile.xml and saves it to the specified
directory.xsd myFile.xml /outputdir:myOutputDir
-
June 29, 2005 at 8:08 am #3177342
Why wait() and notify() should be inside a synchronized block?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I always wondered why does the Java language mandate that wait() should be kept inside a synchronized block. (Especially bcoz wait() releases the lock of the object immediately)This is required by the language, and ensures that wait and notify are properly serialized. In practical terms, this eliminates race conditions that could cause the “suspended” thread to miss a notify and remain suspended indefinitely.
-
June 29, 2005 at 8:08 am #3177343
Simple way to wait in a program or stop a program from exiting.
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
We often require a main thread of a application to keep waiting (and not end).
For Console applications, we can just block with a Console.Read() method.
For other applications, we tend to write a infinite loop like — while(true){}
But the above statement keeps on wasting a lot of computational cycles.A much cleaner and cool approach would be :–
java.lang.Object sync = new java.lang.Object();
synchronized (sync) { sync.wait(); } -
June 29, 2005 at 8:08 am #3177344
Tutorials for networking concepts
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Here are a couple of sites which have the best “audio-visual” tutorials (I have seen) on TCP/IP networking concepts. A must see.. -
June 29, 2005 at 8:08 am #3177345
What is a MAC address?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I often was confused as to why a MAC address is required for a network node when we have a IP address. The MAC address is actually a hardware address that is assigned by the manufacturer and is gauranteed to be unique.Basically the MAC address is used in the Data-link layer and the IP address is used in the Network layer. For e.g. Ethernet uses MAC address to find other hosts.
The ARP protocol does the mapping btw the MAC address and the IP address. -
June 29, 2005 at 8:08 am #3177337
Themes in pluggable Look & Feel Swing
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In addition to the pluggable look and feel UI Managers that Swing provides, each PLAF can also have various themes associated with it. These themes allow U to change some common properties such as ‘font size’, ‘background color of a component’ etc.The abstract javax.swing.plaf.metal.MetalTheme class offers about fifty settings that let you customize the fonts and colors of the Swing components. By creating different subclasses, you can swap many of the properties at once when you change the look and feel.
MetalTheme theme = new MyCustomTheme();
MetalLookAndFeel.setCurrentTheme(theme);
UIManager.setLookAndFeel(new MetalLookAndFeel());For an example of theme usage, try out the Metalworks demonstration that comes with the Java 2 SDK distribution. Simply change the current directory to the demo/jfc/Metalworks directory, and run the demonstration with the following command:
java -jar Metalworks.jar
-
June 29, 2005 at 8:08 am #3177338
File sharing btw a Java and a non-Java application
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Prior to JDK 1.4, it was not easy to share a file between multiple processes (Java or non Java). IT involved the use of native code. But in JDK 1.4 NIO (non blocking IO) was introduced with the concept of channels and file-locks.The FileLock class, which is part of the java.nio.channels package, represents a file lock. You can use a file lock to restrict access to a file from multiple processes. In addition, you have the option of restricting access to an entire file or just a small region of it. A file lock is either shared or exclusive. A shared lock supports read access from multiple processes, while an exclusive lock is typically used for writing. Because a lock is at the file level, you should not use it to restrict access to a file from multiple threads in a single process. If you use a file lock in multiple threads, none of the threads would be restricted from accessing the file. Only external processes are restricted.
-
June 29, 2005 at 8:08 am #3177339
Circular project dependency in Java and .NET
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In one of my .NET projects, we landed up in a situation where there was a circular compilation dependency between 2 projects. It would tough to compile both the projects…so we resorted to first commenting out some code in the second project and then compiling and getting a “dummy” dll which we can use furthur for compilation.But VS.NET can automatically take care of such circular dependencies…The trick is very simple. Just add both the projects to a common solution. And in the ‘Add Reference’ option, do not add the DLL directly, but add the ‘Project’ as a reference. (3rd Tab in Add Reference window)
The VS.NET environment automatically takes care of circular dependencies.Similarly in Java, the javacc compiler automatically takes care of circular dependencies. 🙂
-
June 29, 2005 at 8:08 am #3177340
Diff btw ‘terminal’ and ‘console’ in Solaris/Linux ?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A terminal is just a window that people type commands in. A console can be used as aterminal also, but is connected to the system console which is where the kernel andsyslog will output information to. -
June 29, 2005 at 8:08 am #3177341
Shortcut to reach etc\hosts on a windows machine
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Just type ‘drivers’ on a command prompt or in the ‘Run’ option. 🙂I found this damn handy bcoz I often used to forget the full path where I can put DNS entries.
-
June 29, 2005 at 8:08 am #3177335
“Tera Term” terminal client
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In one of my projects, I often had to log on (telnet) to a server and execute a number of steps..
I desparately wanted some tool which would automate this for me…i.e. pass commands to the server thru telnet, wait for output etc.“Tera Term” is a cool utility that allows U to write scripts using a simple language..(It took me just 5 mins to get the basic commands) The scripts have a *.ttl extension.
Cool handy tool…A must have 🙂
-
June 29, 2005 at 8:08 am #3177336
How to display all TCP/UDP connections on Ur machine?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Windows comes with a cool utility known as ‘netstat’ that can be used to find out all the current TCP or UDP connections on Ur PC.
Also U can find out the port used on Ur PC for a service.
e.g. if U telnet to some machine U know that U are using port ’23’ on that machine, but what is the port on Ur machine?Just type ‘netstat -n’ on the command prompt.
-
June 30, 2005 at 12:07 am #3187886
Transfer of technical blog
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I used to maintain my technical blog at http://naren.tblog.com
But I found the “Blogger” site by google so user-friendly and cool that I am transferring my technical blogs to here. -
June 30, 2005 at 12:07 am #3187887
DateTime class in .NET (localization)
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In ASP.NET, web.config contains a tag.
<globalization culture=”en-GB” requestencoding=”utf-8″ responseencoding=”utf-8″>
When the culture is “en-US” and we print a DateTime object, we get it in the format “mm/dd/yyyy” whereas if U change the culture to “en-GB” then the date.toString() would return a string in the format “dd/mm/yyyy”.So our code cannot assume the date, month to be in a specific format for parsing. Very very imp tip for localisation !!!!
-
June 30, 2005 at 12:07 am #3187888
Difference between java ‘null’ and C sharp ‘null’
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In java, when you try to print a null reference, what do U get?For e.g. Object obj = null;System.out.println(obj);
What gets printed is “null”.
So basically a null reference when converted to a string results in “null”.
But in Csharp, the same code will print a empty stringObject obj = null;
Console.WriteLine(obj);Very imp difference for java developers learning C#
Another important difference is while Type-Casting or Boxing/UnBoxing as it is known in C#.Java does not allow us to cast a reference type to a primitive type.So the following code in Java would throw an compilation error:
boolean b = (boolean)getSomeObject();
Assume getSomeObject() method has the signature:
public object getSomeObject()But in C#, it is possible to type-cast an reference type to an primitive. So the following code would not give a compilation error.
bool b = (bool)getSomeObject();
But at runtime, if getSomeObject() returns a ‘null’ , then we would get a ‘NullReferenceException’
A ‘null’ can be type-casted to any object reference type, but not to a primitive type So in C#, we need to be very careful about this fact -
June 30, 2005 at 12:07 am #3187889
Indexers in .NET
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
How can we write a customCollection object which behaves the same way as a ASP.NET session object or Application object, i.e. retrieve the values using indexes.For e.g. we can retrieve a object from Session as :
object obj = Session[“key”]; //to retrieve
Session[“key”] = obj; //add or set a value in Session.Writing our own Collection object which behaves in a similar manner is very simple, using Indexes in C #See code below:
class MyCollection
{
private Hashtable hashTable = new Hashtable();
public object this [object index]
{
get{return hashTable[index];} set{hashTable[index] = value;}
}
}Now we can use MyCollection object as shown below:
MyCollection myCollection = new MyCollection();
myCollection[“Naren”] = “Swetha”;
Console.WriteLine(“value >> ” + myCollection[“Naren”]);That’s it….
-
June 30, 2005 at 12:07 am #3187890
A simple recursive function to get all files in all sub-dirs of a folder
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The below code is in .NET C#
public ArrayList GetAllFiles(string directory)
{
ArrayList totalFilesList = new ArrayList(10);
string[] files = Directory.GetFiles(directory);//add all files in that current folder.totalFilesList.AddRange(files);//Check if the current directory has sub-directories
string[] subDirs = Directory.GetDirectories(directory);//if yes, then call recursive functions..
if(subDirs.Length > 0)
{//now look for all files in current folder’s sub-dir’s.
foreach(string subDir in subDirs)
{
ArrayList tempArrayList = GetAllFiles(subDir);
totalFilesList.AddRange(tempArrayList);
}
}
return totalFilesList;
} -
June 30, 2005 at 12:07 am #3187881
How to join one row in a table with many related rows in the other table
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Suppose I have a table as below:
Table Project
{
ProjectID int
Manager int (secondary key)
Architect int (secondary key)
Client int (secondary key)
}Table Contact
{
ContactID int (primary key)
Name string
}Now I want to show the Project table with names of Manager and Architect and the client.
A “join” or a “union” will not work…The solution is very simple:select Project.ProjectID, a.FirstName as Manager, b.firstname as Architect, c.FirstName as Client from Project,
Contact a,
Contact b,
Contact c
where a.contact_id = project.manager and
b.contact_id = project.architect and
c.contact_id = project.client -
June 30, 2005 at 12:07 am #3187882
Visual Studio locking dlls above 64kb
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Visual Studio .NET has a very stupid problem…If Ur dotnet assembly size is above 64kb then Intellisense locks the dll and so the build fails.Solutions for the problem are given at:
http://support.microsoft.com/kb/313512/EN-US/ -
June 30, 2005 at 12:07 am #3187883
Awt, Swing and SWT
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
AWT: The idea was to wrap the native GUI widgets of the various operating systems with a platform-independent Java API called Abstract Window Toolkit (AWT). Only common widgets such as text field, text area, check box, radio button, list, and push button were supported by AWT. The graphics and imaging features were also very limited. That was, at best, enough for building simple applets.
SWING: is one of the most complex GUI frameworks ever developed. It has a complete set of GUI components ranging from buttons and text fields to tables, trees, and styled text editors. These components do not rely on the native widgets of the operating system; instead, Swing components are painted using graphic primitives such as lines, rectangles, and text. The painting is delegated to a look and feel (L&F) plug-in that can imitate the native L&F. Swing also has a platform-independent L&F called “Metal.” JBuilder, uses Swing, and its speed is quite good.
Standard Widget Toolkit (SWT) is the GUI toolkit developed by IBM for its Eclipse IDE. SWT can be used outside of the Eclipse environment and offers direct access to the native GUI features of the operating system. Therefore, SWT-based Java applications have native GUIs and can be integrated with other native applications and components. SWT delegates to native widgets for common components (such as labels, lists, tables, and so on) as AWT does, while emulating in Java more sophisticated components (for example, toolbars are emulated when running on Motif) similarly to Swing’s strategy.SWT has been designed to be as inexpensive as possible. This means (among the other things) that it is native-oriented. Anyway, it differs from AWT in a number of details. SWT provides different Java implementations for each platform, and each of these implementations calls natively (through the Java Native Interface, JNI) the underlying native implementation. The old AWT is different in that all platform-dependent details are hidden in C (native) code and the Java implementation is the same for all the platforms.
-
June 30, 2005 at 12:07 am #3187884
Cool Cool Java Collections
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
With JDK 1.2, Sun introducted the Java Collection Framework, a cool API for data-structures in Java. At the base of the heirarchy were collection interfaces like:
List: A collection that is ordered and whose members can be accessed by index. A list can also contain duplicates and null values.
Set: A collection that is not ordered and hence there are no methods that allow to access members thru a index. Also a Set does not allow duplicates and atmost one null value.Though I personally feel that the JDK Collection framework is quite comprehensive and should suffice most development needs, it is good to know about some other alternatives:
1) Jakarta Commons Collections – An open source initiative that contains some extra cool collections like MultiMap etc.
2) JGL (Java Generic Library) – A port of the C++ STL (Standard tag library) to the Java language. Thought I was first impressed by this package, I think this API would appleal more to those from the C++ background. Also the latest version is no longer free, I believe. -
June 30, 2005 at 12:07 am #3187885
What does ‘foo’ and ‘bar’ mean? Does anyone know the history.
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Since college days, we have been seeing the words ‘foo’ and ‘bar’ in a hell lot of programs…So what do these variable names mean ?…The following links provide some really amusing information:
http://www.catb.org/~esr/jargon/html/F/foo.html -
June 30, 2005 at 12:07 am #3187875
How does VMWare work?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently a few guys in my team were using a tool known as VMWare for simulating different operating systems on a single machine. Here’s some info on how this is done:VMWare hosts each guest operating system in a separate, secure virtual machine. Each virtual machine (VM) has its own virtual CPU, memory, disk, etc. and all of the virtual hardware is mapped to your computer’s real hardware. Each virtual machine also comes complete with its own BIOS that can be edited the same way you’d edit the real BIOS on the computer that VMWare is running on. This lets you customize your virtual machines and control all of the usual stuff that you can control via your PC’s actual BIOS.
http://www.extremetech.com/article2/0,1558,1628461,00.asp
http://www.vmware.com -
June 30, 2005 at 12:07 am #3187876
Microsoft has a Linux Lab !!!
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I should have not been totally suprised by this news, as it is natural for a company to have some “competitive systems” where they can benchmark their products with the other products.But it looks like MS is trying to play a different ball game. It “says” (believe it or not) that it wants to bridge the gap between the opensource community and MS. It’s hard to say what MS strategy really is, but the truth is, today open-source software has become a force to reckon with !!!
http://www.microsoft-watch.com/article2/0,1995,1813672,00.asp
-
June 30, 2005 at 12:07 am #3187877
Some good Java interview questions
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The following links have some good Java questions that one can expect in interviews:http://java.sys-con.com/read/48839_2.htm
http://java.sys-con.com/read/46228.htm
Also interesting is some points given in the second link regarding the trouble is finding good Java developers today.
-
June 30, 2005 at 12:07 am #3187878
Architect or Developer
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
This eternal debate keeps coming up from time to time.
This time the debate was sparked by a article in Javaworld at http://www.javaworld.com/javaworld/jw-05-2005/jw-0509-architect.htmlAll the comments that were posted in response were very very interesting:
http://www.theserverside.com/news/thread.tss?thread_id=33809&News05_10_05-click
http://indicthreads.com/blogs/209/java_architect_developer.htmlAlso I was amused to hear what Martin Fowler of “ThoughtWorks” had to say about this topic.
http://www.martinfowler.com/ieeeSoftware/whoNeedsArchitect.pdfIn Agile methodologies, there is more focus on keeping components flexible and ready for change, hence the role of a architect also changes…Interesting read 🙂
Some really amusing comments are listed below : (who says developers do not have a good sense of humor)
- Of course there are organization where you have PowerPoint-architects who hide their ignorance and lack of actual knowledge behind stack loads of nice-looking high-level block-diagrams that do absolutely nothing and will never be looked upon a second time after they have been presented to the project board or whoever.
- Any of the following is much better definition of a (Java) architect :1. One who does not know how to start a java JVM. 2. One talks about UML all the times and present you a class diagram by copying from Gang of Four pattern book as his design.3. One who has never managed to write more than 100 lines of codes successfully.4. One who is the buddy of the VP of Engineering or CTO.
-
June 30, 2005 at 12:07 am #3187879
Alternate .NET IDE’s
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
While Microsoft Visual Studio .NET is the standard-bearer for .NET development, its hefty price tag and overwhelming features can often push developers away from it. Thankfully, a variety of alternative IDEs (Integrated Development Environment) are available. Here’s a high-level view of these alternatives.ASP.NET Web Matrix
Microsoft provides the freely available ASP.NET Web Matrix tool for developing ASP.NET-based applications. Microsoft describes it as a community-supported, easy-to-use WYSIWYG application development tool for ASP.NET. It includes database connectivity, Web services, mobile platform support, and support for multiple languages. It is supported on Windows 2000 and XP and Internet Explorer 5.5 or greater with the .NET Framework installed. Finally, it includes a development Web server so IIS is not required.SharpDevelop
SharpDevelop is a freely available open source IDE built with the C# language. It provides a great example of what you can achieve with the .NET platform, but it doesn’t restrict you to C#. It is similar to Visual Studio .NET in both appearance and features. It allows you to develop all types of applications including ASP.NET, Windows Forms, and console. At this time, it is only supported on the Windows platform.PrimalCode
PrimalCode is a commercially available .NET IDE available from Sapien. The company describes it as an innovative .NET development environment, incorporating complete scripting and .NET development capability in a compact size that works with your existing hardware. PrimalCode includes two other Sapien tools: PrimalScript and PrimalDiff. In addition to .NET support, PrimalCode supports more than 30 languages including Perl, classic ASP, PHP, ColdFusion, VBScript, JSP, and WMI. Also, it includes a source code control system. It is available for the Windows platform with a trial download available. The download version is available for $249 USD.Antechinus C# Editor
Antechinus C# Editor allows you to develop C# code including both Windows Forms and ASP.NET applications. It resembles Microsoft FrontPage, allowing you to publish an application to the appropriate Web location. It is integrated with the various tools installed with the .NET Framework, and it includes many features to make your life easier like bookmarking, documentation, color-coding, templates, and so forth. It is available for $49.95 USD for the Windows platform.Eclipse
Eclipse is an open, extensible IDE framework developed by IBM. It was originally developed for the Java language. It is built on a mechanism for discovering, integrating, and running modules called plug-ins. That is, a tool provider writes a tool as a separate plug-in that operates on files in the workspace and surfaces its tool-specific user interface in the IDE. One such plug-in is the C# Plugin from Improve Technologies. It allows you to work with C# code, but the creation of C# projects or integrated development of ASP.NET or Windows Forms’ applications is not supported. Both Eclipse and the Improve C# Plugin are freely available for Windows and Linux.MonoDevelop
MonoDevelop is a freely available IDE for the Linux platform. It is connected with the Mono project. It is a simple IDE allowing development of C# code. It includes various Visual Studio .NET features like code completion, extensive help, class management, and an integrated debugger. It is still in the early stages of development so it will continue to add features, including support for building GUI interfaces. You should monitor its site to keep up with associated developments.CodeWright
Borland has been an active member of the development tool community for many years, and they are an active participant in the continuing evolution of Eclipse as well. Its CodeWright tool is a powerful file editing system. It includes peer-to-peer connectivity for remote communication and file editing. Basically, I think of it as a text editor on steroids. It is available as a standalone tool as well as an add-in for Visual Studio .NET. The downside is that the CodeWright product is being discontinued so future support is still to be determined. -
June 30, 2005 at 12:07 am #3187880
In .NET should we implement Finalize() or Dispose() method?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A type must implement Finalize() when it uses unmanaged resources such as file handles or database connections that must be released when the managed object that uses them is reclaimed.But executing Finalize() has its performance bottlenecks. Read the below articles for more info.
http://msdn.microsoft.com/msdnmag/
issues/1100/GCI/default.aspxhttp://msdn.microsoft.com/msdnmag/
issues/1200/GCI2/default.aspxHence it is better if a Dispose() method is implemented and developers are encouraged to call Dispose() or Close(). We can always have Finalize() as a back-up in case the developer forgets to call Dispose(). For this we need to use the SuppressFinalize() method to prevent double execution of clean-up code.
GC class has a SuppressFinalize() method that can be called from the IDisposable.Dispose method to prevent the garbage collector from calling Object.Finalize on an object that does not require it.
-
June 30, 2005 at 12:07 am #3187870
How GC works on .NET?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Two excellent articles on how Garbage Collection works in .NET.
A “MUST READ” for all .NET developers..http://msdn.microsoft.com/msdnmag/
issues/1100/GCI/default.aspxhttp://msdn.microsoft.com/msdnmag/
issues/1200/GCI2/default.aspxExcerpt from the article:
How does the garbage collector know if the application is using an object or not?
As you might imagine, this isn’t a simple question to answer.Every application has a set of roots. Roots identify storage locations, which refer to objects on the managed heap or to objects that are set to null. For example, all the global and static object pointers in an application are considered part of the application’s roots. In addition, any local variable/parameter object pointers on a thread’s stack are considered part of the application’s roots. Finally, any CPU registers containing pointers to objects in the managed heap are also considered part of the application’s roots. The list of active roots is maintained by the just-in-time (JIT) compiler and common language runtime, and is made accessible to the garbage collector’s algorithm.
Now, the garbage collector starts walking the roots and building a graph of all objects reachable from the roots. For example, the garbage collector may locate a global variable that points to an object in the heap.
Once this part of the graph is complete, the garbage collector checks the next root and walks the objects again. As the garbage collector walks from object to object, if it attempts to add an object to the graph that it previously added, then the garbage collector can stop walking down that path. This serves two purposes. First, it helps performance significantly since it doesn’t walk through a set of objects more than once. Second, it prevents infinite loops should you have any circular linked lists of objects.Once all the roots have been checked, the garbage collector’s graph contains the set of all objects that are somehow reachable from the application’s roots; any objects that are not in the graph are not accessible by the application, and are therefore considered garbage. The garbage collector now walks through the heap linearly, looking for contiguous blocks of garbage objects (now considered free space). The garbage collector then shifts the non-garbage objects down in memory (using the standard memcpy function that you’ve known for years), removing all of the gaps in the heap. Of course, moving the objects in memory invalidates all pointers to the objects. So the garbage collector must modify the application’s roots so that the pointers point to the objects’ new locations. In addition, if any object contains a pointer to another object, the garbage collector is responsible for correcting these pointers as well.
-
June 30, 2005 at 12:07 am #3187871
What are weak references in .NET?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Weak references reduce the memory pressure placed on the managed heap by large objects.
When a root points to an object, the object cannot be collected because the application’s code can reach the object. When a root points to an object, it’s called a strong reference to the object. However, the garbage collector also supports weak references. Weak references allow the garbage collector to collect the object, but they also allow the application to access the object.——————————————————
Void Method() {
Object o = new Object(); // Creates a strong reference to the
// object.// Create a strong reference to a short WeakReference object.
// The WeakReference object tracks the Object.
WeakReference wr = new WeakReference(o);o = null; // Remove the strong reference to the object
o = wr.Target;
if (o == null) {
// A GC occurred and Object was reclaimed.
} else {
// a GC did not occur and we can successfully access the Object
// using o
}
}———————————————
Once you’ve created a weak reference to an object, you usually set the strong reference to the object to null. If any strong reference remains, the garbage collector will be unable to collect the object.
To use the object again, you must turn the weak reference into a strong reference. You accomplish this simply by calling the WeakReference object’s Target property and assigning the result to one of your application’s roots. If the Target property returns null, then the object was collected. If the property does not return null, then the root is a strong reference to the object and the code may manipulate the object. As long as the strong reference exists, the object cannot be collected.Note: It seems that “weak” references in .NET are equivalent to “soft” references in Java.
-
June 30, 2005 at 12:07 am #3187872
How GC works in Java?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The GC mechanisms in Java and .NET are the same with some minor differences. Read the following articles for more details:
http://www.javaworld.com/javaworld/jw-12-2001/jw-1207-java101.html
http://www.javaworld.com/javaworld/jw-01-2002/jw-0104-java101.html
http://www.javaworld.com/javaworld/jw-01-2002/jw-0104-java101guide.html
-
June 30, 2005 at 12:07 am #3187873
Soft references, Weak References, Phantom references in Java !!!
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The Reference API in Java can leave any sane person fully confused !!!..I tried to make sense of what the different types of references are and what purpose do they solve.
I am still not crystal clear about the usability of all these references, but I hope I will understand someday.Referent
An object that is softly, weakly, or phantomly referenced from inside a SoftReference, WeakReference, or PhantomReference object, respectively.Soft references:
The garbage collector might or might not reclaim a softly reachable object depending on how recently the object was created or accessed, but is required to clear all soft references before throwing an OutOfMemoryError.Weakly reachable objects are finalized some time after their weak references have been cleared. The only real difference between a soft reference and a weak reference is that the garbage collector uses algorithms to decide whether or not to reclaim a softly reachable object, but always reclaims a weakly reachable object.
Phantomly reachable objects are objects that have been finalized, but not reclaimed.
The garbage collector will never clear a phantom reference. All phantom references must be explicitly cleared by the program.An excellent article explaining GC in Java is given at
http://www.artima.com/insidejvm/ed2/gc17.htmlExcerpts from the article:
————————–
Note that whereas the garbage collector enqueues soft and weak reference objects when their referents are leaving the relevant reachability state, it enqueues phantom references when the referents are entering the relevant state. You can also see this difference in that the garbage collector clears soft and weak reference objects before enqueueing them, but not phantom reference objects. Thus, the garbage collector enqueues soft reference objects to indicate their referents have just left the softly reachable state. Likewise, the garbage collector enqueues weak reference objects to indicate their referents have just left the weakly reachable state. But the garbage collector enqueues phantom reference objects to indicate their referents have entered the phantom reachable state. Phantom reachable objects will remain phantom reachable until their reference objects are explicitly cleared by the program.The garbage collector treats soft, weak, and phantom objects differently because each is intended to provide a different kind of service to the program. Soft references enable you to create in-memory caches that are sensitive to the overall memory needs of the program. Weak references enable you to create canonicalizing mappings, such as a hash table whose keys and values will be removed from the map if they become otherwise unreferenced by the program. Phantom references enable you to establish more flexible pre-mortem cleanup policies than are possible with finalizers
To use the referent of a soft or weak reference, you invoke get() on the reference object. If the reference hasn’t been cleared, you’ll get a strong reference to the referent, which you can then use in the usual way. If the reference has been cleared, you’ll get null back. If you invoke get() on a phantom reference object, however, you’ll always get null back, even if the reference object hasn’t yet been cleared. Because the phantom reachable state is only attained after an object passes through the resurrectable state, a phantom reference object provides no way to access to its referent. Invoking get() on a phantom reference object always returns null, even if the phantom reference hasn’t yet been cleared, because if it returned a strong reference to the phantom reachable object, it would in effect resurrect the object. Thus, once an object reaches phantom reachability, it cannot be resurrected.
Virtual machine implementations are required to clear soft references before throwing OutOfMemoryError, but are otherwise free to decide when or whether to clear them. Implementations are encouraged, however, to clear soft references only when the programs demand for memory exceeds the supply, to clear older soft references before newer ones, and to clear soft references that haven’t been used recently before soft references that have been used recently.
Soft references enable you to cache in memory data that you can more slowly retrieve from an external source, such as a file, database, or network. So long as the virtual machine has enough memory to fit the softly referenced data on the heap together with all the strongly referenced data, the soft reference will in general be strong enough to keep the softly referenced data on the heap. If memory becomes scarce, however, the garbage collector may decide to clear the soft references and reclaim the space occupied by the softly referenced data. The next time the program needs to use that data, it will have to be reloaded from the external source. In the mean time, the virtual machine has more room to accommodate the strongly (and other softly) referenced memory needs of the program.
Weak references are similar to soft references, except that whereas the garbage collector is free to decide whether or not to clear soft references to softly reachable objects, it must clear weak references to weakly reachable objects as soon as it determines the objects are weakly reachable. Weak references enable you to create canonicalizing mappings from keys to values. The java.util.WeakHashMap class uses weak references to provide just such a canonicalizing mapping. You can add key-value pairs to a WeakHashMap instance via the put() method, just like you can to an instance of any class that implements java.util.Map. But inside the WeakHashMap, the key objects are held via weak reference objects that are associated with a reference queue. If the garbage collector determines that a key object is weakly reachable, it will clear and enqueue any weak reference objects that refer to the key object. The next time the WeakHashMap is accessed, it will poll the reference queue and extract all weak reference objects that the garbage collector put there. The WeakHashMap will then remove from its mapping any key-value pairs for keys whose weak reference object showed up in the queue. Thus, if you add a key-value pair to a WeakHashMap, it will remain there so long as the program doesn’t explicitly remove it with the remove() method and the garbage collector doesn’t determine that the key object is weakly reachable.
Phantom reachability indicates that an object is ready for reclamation. When the garbage collector determines that the referent of a phantom reference object is phantom reachable, it appends the phantom reference object to its associated reference queue. (Unlike soft and weak reference objects, which can optionally be created without associating them with a reference queue, phantom reference objects cannot be instantiated without associating the reference object with a reference queue.) You can use the arrival of a phantom reference in a reference queue to trigger some action that you wish to take at the end of an object’s lifetime. Because you can’t get a strong reference to a phantom reachable object (the get() method always returns null), you won’t be able to take any action that requires you to have access to the instance variables of the target. Once you have finished the pre-mortem cleanup actions for a phantom reachable object, you must invoke clear() on the phantom reference objects that refer to it. Invoking clear() on a phantom reference object is the coup de gras for its referent, sending the referent from the phantom reachable state to its final resting place: unreachability.
-
June 30, 2005 at 12:07 am #3187874
How to get localized objects in Java?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A lot of “i18N” programs only have to deal with “strings” that need to be localized. For e.g. labels, other text etc.
But what if U need a localized object ?..i.e a double object, a JPEG object etc.There is a special class in Java “ListResourceBundle” that allows a ResourseBundle to be loaded from a “.class” file.
Read the tutorial below for more info :
http://java.sun.com/docs/books/tutorial/i18n/resbundle/list.html -
June 30, 2005 at 12:07 am #3187543
Number formatting…Really crazy !!!
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
During “i18n” tasks in my development career, I was amused to see how some locales have the formatting exactly opposite to that of US or UK.For e.g.
In en_US locale, a number(currency) would look like $9,876,543.21 (separated by comma and a decimal)But in German, the same number would be written as 9.876.543,21 DM (comma and decimal have opposite meaning !!!)
To furthur add to the confusion, in French, the amount would be written as 9 876 543,21 F (space and comma)
God save us poor mortal developers in understanding these nuances !!!
-
June 30, 2005 at 12:07 am #3187544
What is HTTP tunneling?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In most cases, network administrators will configure a firewall to only allow HTTP traffic on the default Web server port, 80. Traffic sent across an HTTP connection is considered relatively safe and, thus, HTTP has become the standard entry protocol to an internal network. Technologies such as SOAP have been designed to provide safe access through a firewall by using HTTP as the transport protocol.HTTP tunneling is designed mainly for firewall aversion. HTTP tunneling performs protocol encapsulation, by enclosing data packets of one protocol (SOAP, JRMP, etc.) within HTTP Packets. The HTTP packets are then sent across the firewall as normal internet traffic.
SOAP is an excellent example of HTTP-Tunneling in the modern era of distributed computing.
The HTTP tunneling can be thought as a way to use an existing road of communication (HTTP) and create a subprotocol within it to perform specific tasks.
The subprotocol will contain all the information necessary to create an object on the Web Server, invoke the method on that object and return results back to the client. -
June 30, 2005 at 12:07 am #3187545
Dealing with Compound messages during i18n
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A compound message contains variable data. In the following list of compound messages, the variable data is in bold:The disk named MyDisk contains 300 files.
The current balance of account #34-98-222 is $2,745.72.
405,390 people have visited your website since January 1, 1998.
Delete all files older than 120 days.Such messages are always difficult to localize. Just picking up sub-strings from the properties files won’t work and would be very cumbersome. In Java, there is a cool class named “MessageFormat” that can be used in such cases. The following link contains the tutorial:
http://java.sun.com/ -
June 30, 2005 at 12:07 am #3187868
What is double buffering technique in Graphics?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Double Buffering is a technique that is used to prevent flicker when drawing onto the screen. The problem stems from the fact that when a new animation frame is rendered, it is desirable to first clear the old frame. This causes a flicker to occur. The basic idea of double buffering is to create a virtual screen out of the user’s view. A graphics device could be a screen, printer, file, or memory area. The virtual screen used as the buffer is the primary example of using a memory space as a graphics device. When paint() is called, the clearing and painting of the animation frame can occur on the virtual screen and the resulting rendered image can then be transferred to the real screen immediately upon completion. The cost of double buffering is in memory and CPU consumption. However, this cost is probably unavoidable for complex animations and usually isn’t too expensive.A very good tutorial on how to reduce flicker in Java GUI applications is given at:
http://javaboutique.internet.com/tutorials/
Java_Game_Programming/BildschirmflackernEng.htmlExcerpt from the article:
Double buffering means to paint all the things in the paint() method to an offscreen image. If all things that have to be painted, are painted, this image is copied to the applet screen. The method does the following in detail:
- Generates a new offscreen-image by using createImage and stores this image in a instance variable( = generate an empty image)
- Call getGraphics to get graphic context for this image
- Draw everything (including to clear the screen completely) on the offscreen image ( = draw image in the background)
- When finished, copy this image over the existing image on the screen. ( = draw image in the foreground)
This technique means that the picture is already painted before it is copied to the screen. When copying the image to the foreground the old pixels are overlayed by the new ones. There won’t be any flickering picture anymore because there is not a millisecond where you see an empty screen!
The only disadvantage of the double buffering is, that it produces a large amount of data and every image is drawn two times (offscreen and when copying to the screen). But in most cases and on a fast computer this is much better than wasting time on finding an other solution!
-
June 30, 2005 at 12:07 am #3187869
What’s the differene between “setenv” and “export” commands in Unix/Linux?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Actually it depends on what shell U are using…i.e. C shell or Bourne Shell.There are 2 types of variables:
- Shell variables — That are local to the shell
- Environment variables — That are available to all other processes
In C-shell to set a shell variable U type: % set name=value
In bourne shell you can just type: $NAME=value
In C-shell to set an environment variable: % setenv [NAME value]
In bourne shell, U need to export the shell variable, so U type: $ export NAME
A good article explaning the differences is present at:
-
June 30, 2005 at 12:07 am #3187538
The wonder of JavaCC !!!
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have been using JavaCC in a project for parsing Resource files. Anyone who has worked with Parsers before would just love the simplicity and power of JavaCC.I would strongly recommend using JavaCC to generate any Java parser anyone would ever need. The following links would get U started 🙂
http://www.engr.mun.ca/~theo/JavaCC-FAQ/javacc-faq.htm
http://www.engr.mun.ca/~theo/JavaCC-Tutorial/ (An excellent tutorial for beginners)
-
June 30, 2005 at 12:07 am #3187539
What are modules (.netmodule files) in .NET? What is their use?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have often wondered on the “real use” of modules and AL.exe in .NET.The only use of AL.exe seems to be during i18N process, when we can create satellite assemblies. AL.exe is also useful if U need to link different .netmodules files into a single DLL. But we still need to ship the .netmodule files too along with the DLL !!!
An excellent article discussing this topic can be found at:
http://www.codenotes.com/cnp/baseAction.aspx?cnp=NET030009 -
June 30, 2005 at 12:07 am #3187540
What’s the advantage of satellite assemblies over raw resource files?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Coming from a Java background, I always use to wonder why .NET converts ordinary resource files into satellite assemblies for internationalization.
Why not use the raw resource text files themselves..( as Java uses properties files)I guess the most imp. advantage U get by converting resources to assemblies is that U can “version and digitally sign” them…i.e. U can give them a version number and also sign them with a private key. So there is a extra security that no one has tampered with the resource files.
-
June 30, 2005 at 12:07 am #3187541
Use of Reflection in .NET to create classes at runtime (from scratch)
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Just as reflection can be used to retrieve and interpret metadata, it can
be used to construct and “emit” it. The classes found in the System
.Reflection.Emit namespace allow metadata for new types to be generated
in memory and used at runtime. In fact, you can dynamically create
an entire assembly, its classes and methods, and the IL code behind them.
The “in memory” assembly can then be used by other applications.A good example and article can be found at :
http://www.codenotes.com/cnp/baseAction.aspx?cnp=NET040002 -
June 30, 2005 at 12:07 am #3187542
List of common ports
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Here’s a list of the most common ports that are in use. A more complete list can be found at :
http://www.iana.org/assignments/port-numbers0 to 1023
1/tcp: TCP Multiplexor
7/tcp: ECHO protocol
7/udp: ECHO protocol
9/tcp: DISCARD protocol
9/udp: DISCARD protocol
13/tcp: DAYTIME protocol
17/tcp: QOTD (Quote of the Day) protocol
19/tcp: CHARGEN (Character Generator) protocol
19/udp: CHARGEN protocol
20/tcp: FTP (File Transfer Protocol) – data port
21/tcp: FTP – control (command) port
22/tcp: SSH (Secure Shell) – used for secure logins, file transfers (scp, sftp) and port forwarding
23/tcp: Telnet protocol – unencrypted text communications
25/tcp: SMTP (Simple Mail Transfer Protocol) – used for sending E-mails
53/tcp: DNS (Domain Name Server)
53/udp: DNS
67/udp: BOOTP (BootStrap Protocol) server; also used by DHCP (Dynamic Host Configuration Protocol)
68/udp: BOOTP client; also used by DHCP
69/udp: TFTP (Trivial File Transfer Protocol)
70/tcp: Gopher protocol
79/tcp: Finger protocol
80/tcp: HTTP (HyperText Transfer Protocol) – used for transferring web pages
88/tcp: Kerberos – authenticating agent
109/tcp: POP2 (Post Office Protocol version 2) – used for retrieving E-mails
110/tcp: POP3 (Post Office Protocol version 3) – used for retrieving E-mails
113/tcp: ident – old server identification system, still used by IRC servers to identify its users
119/tcp: NNTP (Network News Transfer Protocol) – used for retrieving newsgroups messages
123/udp: NTP (Network Time Protocol) – used for time synchronization
139/tcp: NetBIOS
143/tcp: IMAP4 (Internet Message Access Protocol 4) – used for retrieving E-mails
161/udp: SNMP (Simple Network Management Protocol)
179/tcp: BGP (Border Gateway Protocol)
389/tcp: LDAP (Lightweight Directory Access Protocol)
443/tcp: HTTPS – HTTP over SSL (encrypted transmission)
445/udp: Microsoft-DS SMB – used for file sharing
514/udp: syslog protocol – used for system logging
540/tcp: UUCP (Unix-to-Unix CoPy protocol)
636/tcp: LDAP over SSL (encrypted transmission)
666/tcp: id Software‘s DOOM multiplayer game played over TCP
993/tcp: IMAP4 over SSL (encrypted transmission)
995/tcp: POP3 over SSL (encrypted transmission)
1024 to 49151
1080/tcp: SOCKS proxy
1352/tcp: IBM Lotus Notes/Domino RCP
1433/tcp: Microsoft SQL database system
1434/tcp: Microsoft SQL Monitor
1434/udp: Microsoft SQL Monitor
1984/tcp: Big Brother – network monitoring tool
3128/tcp: HTTP used by web caches and the default port for the Squid cache
3306/tcp: MySQL database system
3389/tcp: Microsoft Terminal Server (RDP)
5190/tcp: AOL and AOL Instant Messenger
5222/tcp: XMPP/Jabber – client connection
5269/tcp: XMPP/Jabber – server connection
5432/tcp: PostgreSQL database system
6000/tcp: X11 – used for X-windows
6667/tcp: IRC (Internet Relay Chat)
8000/tcp: iRDMI – often mistakenly used instead of port 8080
8080/tcp: HTTP Alternate (http-alt) – used when running a second web server on the same machine (the other is in port 80), for web proxy and caching server, or for running a web server as a non-root user. Default port for Jakarta Tomcat.
8118/tcp: Privoxy web proxy – advertisements-filtering web proxy
49152 to 65535
Unregistered Ports
These are ports that may be in common use, but that are not formally registered with IANA. Where the use conflicts with a registered use, the notation CONFLICT is used.
1337/tcp: WASTE Encrypted File Sharing Program
1521/tcp: Oracle database default listener – CONFLICT with registered use: nCube License Manager
2082/tcp: CPanel‘s default port – CONFLICT with registered use: Infowave Mobility Server
2086/tcp: Web Host Manager’s default port – CONFLICT with registered use: GNUnet
5000/tcp: Universal plug-and-play (UPnP) – Windows network device interoperability; CONFLICT with registered use: commplex-main
5223/tcp: XMPP/Jabber – default port for SSL Client Connection
5800/tcp: VNC remote desktop protocol – for use over HTTP
5900/tcp: VNC remote desktop protocol – regular port
6881/tcp: BitTorrent – port often used
6969/tcp: BitTorrent tracker port – CONFLICT with registered use: acmsoda
27960/udp: (through 27969) id Software‘s Quake 3 and Quake 3 derived games
31337/tcp: Back Orifice – remote administration tool (often Trojan horse) (“31337” is the “Leet speak” version of “Elite”) -
June 30, 2005 at 12:07 am #3187533
Events and delegates in .NET
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In .NET events and delegates both seem to behave almost identically. Actually both of them are closely related. Event is just a added modifier on a delegate.Another imp. difference is that invoking an event can only be done from within the class that declared the event, whereas a delegate field can be invoked by whoever has access to it.
For more details check out:
http://blog.monstuff.com/archives/000040.html -
June 30, 2005 at 12:07 am #3187534
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
June 30, 2005 at 12:07 am #3187535
ACID rules for transactions
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
- Transaction must be Atomic (it is one unit of work and does not dependent on previous and following transactions)
- Consistent (data is either committed or roll back, no ?in-between? case where something has been updated and something hasn?t)
- Isolated (no transaction sees the intermediate results of the current transaction)
- Durable (the values persist if the data had been committed even if the system crashes right after).
-
June 30, 2005 at 12:07 am #3187536
Tool to measure cyclomatic complexity in Java
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
“Understand for Java” is a cool tool (also a IDE) that gives us reports showing the cyclomatic complexity of Java classes/methods.
http://www.scitools.com/uj.html -
June 30, 2005 at 12:07 am #3187537
How to debug the OnStart() method of a service in .NET?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
It’s a bit trickly to debug the OnStart() method of a service. To debug a service, U need to attach the process to the debugger (that means the process is already started and the OnStart() has been executed). So how do U debug the OnStart() method.First, the important concept is that U can have more than one service running inside a process i.e. 2 or 3 services can share the same process. (Remember thats why we have 2 classes: ServiceProcessInstaller and ServiceInstaller)
So follow the following steps:- Make a dummy service under the same process as Ur main service
- Start the dummy service and attach the debugger to the process
- Put a break-point in the OnStart() method of Ur main service.
- Then start Ur main service… The break point will be hit ….Yahooooo…..
-
June 30, 2005 at 12:07 am #3187531
What’s the equivalent of EJB’s in Windows (.NET)
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
When I was first introduced to ASP.NET, I wondered if there was an equivalent to EJB’s in .NET.
Well, the answer is YES…
COM+ offer all the same services that a EJB container does. So instead of beans, U write “serviced components”.COM+ services are available on the MTS (Microsoft Transaction Server) plaform and offer the following services:
- Transaction Management
- Object Pooling
- On-Demand (JIT) Object Activation
- Security Management etc.
-
June 30, 2005 at 12:07 am #3187532
Can we convert a Java object into a COM component?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
At first shot, I thought this is absolutely impossible, until I saw this link: -
June 30, 2005 at 4:06 am #3187512
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
June 30, 2005 at 4:06 am #3187513
What is FCAPs in network management?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
FCAPS is the ISO model for network management. It forms the cornerstone of current day network management.
It is an acronym for Faults, Configuration, Accounting, Performance, Security, the categories into which the model breaks the various network management tasks. -
June 30, 2005 at 8:07 am #3187344
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
June 30, 2005 at 8:07 am #3187343
Typed datasets in ADO.NET
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In ADO.NET when I came across the concept of typed data-set, the first question I had on my mind was “WHY?” What are the advantages?.NET SDK help states the following:
A typed DataSet is a class that derives from a DataSet. As such, it inherits all the methods, events, and properties of a DataSet. Additionally, a typed DataSet provides strongly typed methods, events, and properties. This means you can access tables and columns by name, instead of using collection-based methods. Aside from the improved readability of the code, a typed DataSet also allows the Visual Studio .NET code editor to automatically complete lines as you type.Additionally, the strongly typed DataSet provides access to values as the correct type at compile time. With a strongly typed DataSet, type mismatch errors are caught when the code is compiled rather than at run time.
————————————————–
So I understand that one of the advantages of using typed datasets is that you will catch typos in table and column names at compile time not run time as with un-typed data sets. In fact using intellisense eliminates those typos all together..But during the earliers states of the project. when the database may keep changing according to requirements, U would need to synch the database with the code everytime !!!…Anyway, my personal belief is that all errors relating to column names etc. should be captured during unit-testing. (Or is this impossible in a mega-project and the overhead of manually creating dataset schemas would be justified?)
-
June 30, 2005 at 10:42 am #3187223
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
June 30, 2005 at 1:07 pm #3187064
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
June 30, 2005 at 9:06 pm #3186926
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 1, 2005 at 1:06 am #3186889
Capturing Page-output in ASPX pages
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
There is a cool trick thru which one can capture the page-output of Aspx pages before it is send to the browser. An excellent article explaining this is at :
http://west-wind.com/weblog/posts/481.aspxThe trick is to override the Page.Render() method, and capture the output in a TextWriter. Then write the same context back to the original textwriter. Sounds confusing..It is a bit 🙂
Here is the code snippet:protected override void Render(HtmlTextWriter writer)
{
// *** Write the HTML into this string builder
StringBuilder sb = new StringBuilder();
StringWriter sw = new StringWriter(sb);
HtmlTextWriter hWriter = new HtmlTextWriter(sw);
base.Render(hWriter);
// *** store to a string
string PageResult = sb.ToString();
// *** Write it back to the server
writer.Write(PageResult);
}
-
July 1, 2005 at 5:06 am #3186859
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 1, 2005 at 9:06 am #3187747
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 1, 2005 at 1:06 pm #3187664
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 1, 2005 at 5:07 pm #3187601
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 1, 2005 at 9:05 pm #3187557
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 2, 2005 at 1:05 am #3185515
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 2, 2005 at 9:05 am #3185436
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 2, 2005 at 1:06 pm #3185396
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 2, 2005 at 5:06 pm #3185354
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 2, 2005 at 9:05 pm #3185333
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 3, 2005 at 1:05 am #3185315
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 3, 2005 at 5:04 am #3185284
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 3, 2005 at 1:05 pm #3185237
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 3, 2005 at 5:06 pm #3185199
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 3, 2005 at 9:06 pm #3172843
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 4, 2005 at 1:06 am #3172826
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 4, 2005 at 1:06 am #3172825
Cool Tool: Link Checker
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Quite often, we have to unit-test each and every link on a web site. This could be automated thru a tool called “Link Checker” available at : -
July 4, 2005 at 5:06 am #3172810
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 4, 2005 at 1:06 pm #3172727
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 4, 2005 at 5:05 pm #3172697
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 5, 2005 at 1:05 am #3172662
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 5, 2005 at 5:05 am #3172609
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 5, 2005 at 9:10 am #3186798
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 5, 2005 at 9:10 am #3186797
Dictionary Attack on Ur hashed passwords
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Whenever we store a hashed password in a file or in the database, then it may be possible for a intruder to get the password using a ‘dictionary’ attack.Here’s what the MSDN says:
Hashed passwords stored in a text file cannot be used to regenerate the original password, but they are potentially vulnerable to a dictionary attack. In this type of attack, the attacker, after gaining access to the password file, attempts to guess passwords by using software to iteratively hash all words in a large dictionary and compare the generated hashes to the stored hash. If you store hashed passwords by any storage mechanism, you should require your users to choose passwords that are not common words and that contain some numbers and nonalphanumeric characters to help prevent dictionary attacks. -
July 5, 2005 at 1:08 pm #3186653
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 5, 2005 at 5:06 pm #3186550
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 5, 2005 at 9:06 pm #3180120
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 6, 2005 at 1:05 am #3180086
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 6, 2005 at 9:06 am #3179893
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 6, 2005 at 1:06 pm #3183057
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 6, 2005 at 5:05 pm #3182952
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 6, 2005 at 9:06 pm #3182893
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 7, 2005 at 1:09 am #3182852
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 7, 2005 at 1:09 am #3182851
Subversion — A supplant to CVS?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
CVS has done a lot of good to a lot of projects..But there is a new tool that’s making waves in the open-source community..A source-control system named ‘Subversion’ that’s touted to replace CVS.Check out more info at:
http://svnbook.red-bean.com/ -
July 7, 2005 at 5:10 am #3184489
Big endian Vs little endian
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
With Apple officially declaring that Mac’s would move to Intel processors, it brought out an important question in my mind…What would happen to the byte-sex???Mac’s use big-endian format and intel processors always use little-endian format. So how will applications on Mac behave if the Intel processors are used?
For more info on byte-sex, check out these links below:
http://www.cs.umass.edu/~verts/cs32/endian.html -
July 7, 2005 at 9:07 am #3184246
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 7, 2005 at 1:06 pm #3183385
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 7, 2005 at 5:06 pm #3183293
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 7, 2005 at 9:06 pm #3183232
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 8, 2005 at 1:05 am #3183196
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 8, 2005 at 5:05 am #3183156
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 8, 2005 at 5:05 am #3183155
Aspnet_regiis.exe tool
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
There are times when the ‘link’ between IIS and ASP.NET can be broken, because of uninstall or reinstall of IIS or .NET environment.In such as case U can use the Aspnet_regiis.exe tool that comes with the .NET SDK.
Just type : Aspnet_regiis.exe -r
Use Aspnet_regiis.exe -i if U also want to install the asp.net engine embedded within the regiis tool and update the IIS mapping.Sometimes you may also have to register the Aspnet_isapi.dll by clicking start -> run.
In the Open text box, type ?regsvr32 %windir%\Microsoft.NET\Framework\version\aspnet_isapi.dll? and then press ENTER -
July 8, 2005 at 9:05 am #3182671
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 8, 2005 at 1:06 pm #3182601
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 8, 2005 at 5:06 pm #3182536
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 8, 2005 at 9:06 pm #3182506
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 9, 2005 at 5:05 am #3182460
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 9, 2005 at 9:06 am #3169574
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 9, 2005 at 1:06 pm #3169537
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 9, 2005 at 5:05 pm #3169520
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 9, 2005 at 9:05 pm #3169501
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 10, 2005 at 1:05 am #3169470
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 10, 2005 at 9:05 am #3169431
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 10, 2005 at 1:06 pm #3169409
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 10, 2005 at 5:06 pm #3169384
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 10, 2005 at 9:06 pm #3169302
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 11, 2005 at 1:08 am #3169280
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 11, 2005 at 5:06 am #3169263
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 11, 2005 at 9:06 am #3183647
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 11, 2005 at 9:06 am #3183644
SoapSuds.exe Vs the Wsdl.exe
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have often seen developers getting confused over the similarity of the SoapSuds.exe and the WSDL.exe tools — after all, both are used to generate proxies on the client side.The Wsdl.exe tool creates a proxy class that derives from SoapHttpClientProtocol. This proxy does all the plumbing work of marshalling/unmarshalling using SOAP over HTTP.
The Soapsuds.exe tool creates a proxy class that is derived from System.Runtime.Remoting.Services.RemotingClientProxy which in turn subclasses System.MarshalByRefObject.
The RemotingClientProxy class takes over responsibility for serializing the proper messages according to the selected formatter and sends them from a bird?s view through the configured channel.It’s important to note that the Soapsuds.exe tool works only for ServerActivated objects using the Http channel.
-
July 11, 2005 at 9:06 am #3183645
Object Activation in .NET remoting
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have often been confused on when the ‘new()’ operator can be used for remote server activation? Can it be used only for CAO (client activated objects) or SAO (server activated objects) or for both?The answer is that the ‘new’ operator can be used to activate any kind of remote object-both CAO and SAO. The only difference between GetObject/CreateInstance and ‘new’ is that the former allows you to specify a URL as a parameter, where the latter obtains the URL from the configuration.
Another imp point regarding activation is that the remote object on the server is ‘not’ actually created when the ‘new’ operator or the GetObject() methods are called.
Here’s a snippet of what MSDN says:
GetObject or new can be used for server activation. It is important to note that the remote object is not instantiated when either of these calls is made. As a matter of fact, no network calls are generated at all. The framework obtains enough information from the metadata to create the proxy without connecting to the remote object at all. A network connection is only established when the client calls a method on the proxy. When the call arrives at the server, the framework extracts the URI from the message, examines the remoting framework tables to locate the reference for the object that matches the URI, and then instantiates the object if necessary, forwarding the method call to the object. If the object is registered as SingleCall, it is destroyed after the method call is completed. A new instance of the object is created for each method called.
But for CAO, the new operator or the CreateInstance methods send a Activation message to the server machine when the client creates the object and a proxy is created on the client side. Constructors with parameters are supported. -
July 11, 2005 at 9:06 am #3183646
Data Concurrency Violations in ADO.NET
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Bcoz the DataSet is a disconnected data model, quite often we may have to handle concurrency problems. There are basically 3 ways in which data concurrency is handled:- Pessimistic locking– A range lock is obtained on the required rows and no one else can modify the rows during that time. Fully fool-proof, but reduces the scalibility drastically
- Optimistic locking — If there are data changes that has happened in between the user updates, then the user is given the choice to either overwrite the changes or discard his changes.
- Last wins — Whoever updates last will overwrite everything.
ADO.NET used Optimistic concurrency and hence it is possible to alert the user of any concurrency violations. An excellent article regarding the same is available here.
-
July 11, 2005 at 1:06 pm #3183560
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 11, 2005 at 5:07 pm #3183478
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 11, 2005 at 9:06 pm #3184089
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 12, 2005 at 1:04 am #3184032
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 12, 2005 at 1:04 am #3184031
.NET Remoting Proxies
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In .NET remoting, proxies are generated transparently by the remoting runtime, hence it is necessary to have the remote object metadata at the client side.
This metadata can be obtained in many ways. I only knew of the ‘sharing interfaces’ and ‘soapsuds.exe’ utility, but there are a couple more —? Shared interfaces
? Shared base classes
? Shared implementation (implementation is copied to server and client)
? SoapSuds.exe (lets you extract metadata from running server or from an Assembly) -
July 12, 2005 at 1:04 am #3184028
Elements in the .NET remoting chain
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
There are a lot of components/elements that play a role in the .NET remoting architecture:Client –> Proxy {Converts the stack frame into a message}
— > Message Sink (chain) { Intercepts the message }
— > Formatter { Converts the message into a stream }
— > Channel Sink (chain) {Intercepts the stream }
— > Transport Sink { Transfers the stream from one process to the other }
====================================
— > Transport Sink { On Server side }
— > Channel Sink
— > Formatter
— > Message Sink
— > Dispatcher { Converts the message into a stack frame }
— > Remote Object -
July 12, 2005 at 1:04 am #3184029
SOAP encoding concepts
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Web Services Description Language (WSDL) defines two styles for how an XML Web service method, which it calls an operation, can be encoded in a SOAP request or a SOAP response: RPC and Document. The RPC style refers to encoding the XML Web service method according to the SOAP specification for using SOAP for RPC; otherwise known as Section 7 of the SOAP specification. This style specifies that all parameters are encapsulated within a single element named after the XML Web service method, and that each element within that element represents a parameter named after their respective parameter name.A more detailed explanation can be found at MSDN here.
-
July 12, 2005 at 1:04 am #3184030
Access a .NET webserice using proxy generated from SoapSuds.exe
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Both WSDL.exe and Soapsuds.exe generate proxies that can be used to access a web service.
But we need to be aware of the SOAP encoding differences.SoapSuds.exe expects a RPC style WSDL/Web Service but ASP. NET Web Services are Document style per default. These different styles imply different XML message encoding.
In order for a Soapsuds-generated proxy to communicate with a ASP.NET webservice, we need to apply an attribute to your ASP.NET Web Service class to achieve ‘compatibility’: [SoapRpcService()]
-
July 12, 2005 at 5:07 am #3183992
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 12, 2005 at 5:07 am #3183990
Important points regarding Sponsors in .NET remoting
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
- The lease manager calls ISponsor’s single method, Renewal, when the lease expires, asking for new lease time. Because the sponsor is called across an AppDomain boundary, the sponsor must be a remotable object, i.e. extend from MarshalByRef object.
- We need to override the InitializeLifetimeService() method to return null, so that the sponsor object itself has infinite lease.
- Also the client needs to register a channel so that the server can make the lease renewal calls.
-
July 12, 2005 at 5:07 am #3183991
Problems with CAO in .NET remoting.
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In his excellent article here, Ingo Rammer states the points why CAO is not a good option for many scenarios.Excerpt from the article:
CAOs are always bound to the machine on which they have been created. This means that you can’t use load balancing or failover clustering for these objects. If on the other hand you’d use SingleCall SAOs, you could use Windows Network Load Balancing (NLB) quite easily to randomly dispatch the method invocations to one out of a number of available servers.
If you are running a single-server application, this doesn’t matter too much for you. If however there is the slightest chance that the application has to scale out to a server-side cluster, than CAOs will definitely limit its scalability.
CAOs also affect you on a single server. When running SingleCall SAOs (and when strictly keeping all state information in a database) you can shutdown and restart your server on demand. You could for example upgrade to a newer version or apply some bug fix without having to tell any user to close and restart your client-side application. As soon as you use CAOs however, you instantly lose this feature. If you restart a server in which you host CAOs, the client application will receive exceptions when calling any methods on these objects. CAOs are not restored after restarting your server. Don’t use them if you care about restartability or scalability. -
July 12, 2005 at 9:06 am #3183882
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 12, 2005 at 9:06 am #3183881
Chatty interfaces Vs Chunky interfaces
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In distributed applications, we need to put special emphasis on issues such as network latency, low bandwidth. Hence as a good design principle, we should make our interfaces ‘chunky’ and not ‘chatty’Chatty interfaces are interfaces that make a lot of transitions(between layers, processes etc.) without doing any significant work on the other side. For example, property setters and getters are chatty. Chunky interfaces are interfaces that make only a few transitions and work done on the other side is significant. For example, method that opens a database connection and retrieves some data is chunky.
This does not mean that U return unnecessary data in Ur calls…U need to take a decision based on ‘balance’ and the ‘problem situation’
-
July 12, 2005 at 1:06 pm #3185175
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 12, 2005 at 5:06 pm #3185077
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 12, 2005 at 9:06 pm #3185044
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 13, 2005 at 1:05 am #3185007
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 13, 2005 at 5:06 am #3184906
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 13, 2005 at 5:06 am #3184904
Named pipes in Linux
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In computing, a named pipe (also FIFO for its behaviour) is an extension to the classical pipe concept on UNIX and UNIX-like systems, and is one of the methods of interprocess communication. The concept is also found in Windows, albeit the semantics are largely different.
A good article is available at http://www2.linuxjournal.com/article/2156
Snippet from the article:We often used “un-named” pipes on the command prompt. For e.g. ls grep x
The other sort of pipe is a “named” pipe, which is sometimes called a FIFO. FIFO stands for “First In, First Out” and refers to the property that the order of bytes going in is the same coming out. The “name” of a named pipe is actually a file name within the file system. Pipes are shown by ls as any other file with a couple of differences:
% ls -l fifo1
prw-r–r– 1 andy users 0 Jan 22 23:11 fifo1
The p in the leftmost column indicates that fifo1 is a pipe. The rest of the permission bits control who can read or write to the pipe just like a regular file. On systems with a modern ls, the character at the end of the file name is another clue, and on Linux systems with the color option enabled, fifo is printed in red by default.
To make a pipe named pipe1
% mkfifo pipe
Then open 2 console windows:
% ls -l > pipe1 { in one window }
% cat <>
Voila! The output of the command run on the first console shows up on the second console. Note that the order in which you run the commands doesn’t matter. -
July 13, 2005 at 5:06 am #3184905
IPC channel in .NET 2.0 (remoting)
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Good news is that MS has finally included the ‘named-pipe’ channel into the core .NET 2.0 remoting framework. The channel is known as IPC channel and enables on-box communication between processes on the same m/c.
It has, additionally, the capability to secure that channel with an ACL. You can use an Access Control List with this particular channel to limit the number of users that can access it.More information here.
-
July 13, 2005 at 9:07 am #3184706
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 13, 2005 at 9:07 am #3184705
Diff btw a Corba object and a servant
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have been perplexed by the concepts of Corba object and servant. Finally after a lot of reading, things are falling into place. The following articles give a good explanation of the same:http://www.javaworld.com/javaworld/jw-09-2002/jw-0927-corba_p.html
http://www4.informatik.uni-erlangen.de/~geier/corba-faq/poa.htmlExcerpt from the above articles:
In the CORBA world, an object is a programming entity with an identity, an IDL (interface definition language)-defined interface, and an implementation. An object is an abstract concept and cannot serve client requests. To do so, an object must be incarnated or given bodily form?that is, its implementation must be activated. The servant gives the CORBA object its implementation. At any moment, only one servant incarnates a given object, but over an object’s lifetime, many (different) servants can incarnate the object at different points in time.
The terms creation and destruction apply to objects, while the terms incarnation and etherealization apply to servants.
Once an object is created, it can alternate between many activations and deactivations during its lifetime. To serve requests, an object must:
1)Be activated if it is not active.
2)Be associated with a servant if it does not already have one. Just because an object is active does not mean that it has an associated servant. You can configure/program the POA to use a new servant upon request.A client views a CORBA object as an object reference. The fact that a client has an object reference does not mean that a servant is incarnating the object at that time. In fact, the object reference’s existence does not indicate an object’s existence. If the object does not exist (that is, it has been destroyed), the client will receive an OBJECT_NOT_EXIST error when it tries to access the object using the object reference. However, as noted above, if the object is in a deactivated condition, it will activate, a process transparent to the client.
Servant: A programming language entity that exists in the context of a server and implements a CORBA object. In non-OO languages like C and COBOL, a servant is implemented as a collection of functions that manipulate data (e.g., an instance of a struct or record) that represent the state of a CORBA object. In OO languages like C++ and Java, servants are object instances of a particular class.
The POA distinguishes between the CORBA object reference (IOR) and the implementation object that does the work. This implementation object is called a servant. A BOA-based approach has the IOR and servant existing at the same time. A POA-based approach can support this, but can also support IORs existing without being associated with servants, and also servants existing without being associated with IORs.
Obviously, the association between an IOR and a servant has to be made at some point, to make the servant a useable CORBA object. But this association can be done on-demand. Consider the following example scenarios to motivate the advantages of on-demand association:
- A pool of servants can be instantiated, and then associated in turn with IORs, as needed.
- A set of IORs can be created for the purposes of publishing the references to the Name Service, without going through the work to actually instantiate the servants.
Moreover, the POA allows a single servant to simultaneously support several IORs.
All of the above significantly contribute to scalable applications.HOW DOES THE POA MAKE THE ASSOCIATION BETWEEN SERVANTS AND CORBA OBJECTS?
This is where the Object ID and and POA Active Object Map come in. So, for a given POA, the Object ID identifies a specific CORBA object, which is used in the Active Object Map to identify the servant.
-
July 13, 2005 at 1:06 pm #3184553
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 13, 2005 at 9:06 pm #3190335
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 14, 2005 at 1:11 am #3190296
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 14, 2005 at 9:06 am #3190059
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 14, 2005 at 12:48 pm #3188638
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 14, 2005 at 4:48 pm #3188566
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 14, 2005 at 8:01 pm #3188534
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 15, 2005 at 4:01 am #3188471
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 15, 2005 at 8:02 am #3188393
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 15, 2005 at 12:01 pm #3188285
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 15, 2005 at 4:01 pm #3188208
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 15, 2005 at 8:01 pm #3188174
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 16, 2005 at 12:03 am #3188156
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 16, 2005 at 4:01 am #3188145
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 16, 2005 at 8:01 am #3188126
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 16, 2005 at 12:01 pm #3188103
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 16, 2005 at 4:01 pm #3188090
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 16, 2005 at 8:00 pm #3188079
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 17, 2005 at 12:00 am #3188061
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 17, 2005 at 4:00 am #3188036
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 17, 2005 at 8:03 am #3190582
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 17, 2005 at 12:01 pm #3190558
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 17, 2005 at 4:01 pm #3190540
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 17, 2005 at 8:01 pm #3190512
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 18, 2005 at 12:00 am #3190679
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 18, 2005 at 4:01 am #3190649
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 18, 2005 at 8:02 am #3190382
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 18, 2005 at 12:02 pm #3188883
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 18, 2005 at 4:04 pm #3188815
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 19, 2005 at 4:01 am #3190010
What?s the difference between the System.Array.CopyTo() and System.Array.Clone()?
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The first one performs a deep copy of the array, the second one is shallow. -
July 19, 2005 at 8:01 am #3189896
Java and .NET interop
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Came across a cool tool today that can be used to convert Java byte-code to .NET IL.
What does this mean to developers..Well, it means that if U have a Java library, U need not ‘manually’ port the Java library to .NET. Just use the IKVM tool to do this for U…For furthur details, check out the following links:
http://www.ikvm.net/index.html
http://www.onjava.com/pub/a/onjava/2004/08/18/ikvm.html -
July 20, 2005 at 2:25 am #3176177
Java Classpaths on Cygwin
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The problem with using Java on Cygwin is that Java.exe is a windows program and expects the path to be in windows style. Whereas Cygwin expects paths to be in Unix style.Hence if U run a simple Java command like the below, U will get an error:
java -classpath /cygdrive/d/naren MyJavaProgramEven the following would give an error, bcoz cygwin cannot understand windows path on the command prompt
java -classpath d:\naren MyJavaProgramSo, the solution is to use a cygwin utility known as cygpath.exe. This tool converts from unix paths to windows path, before passing it to the shell.
java -classpath `cygpath -wp $CLASSPATH` [arguments] -
July 22, 2005 at 8:30 am #3186227
Java Decompilers and Obfuscators
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Was looking for a comprehensive list of Java decompilers and obfuscators..Found a nice article here:
http://www.program-transformation.org/Transform/JavaDecompilers -
July 22, 2005 at 8:30 am #3186228
Proxy setting for Java programs
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Quite often whenever we need to connect to the internet thru the company firewall, we need to set the proxy details for the Java interpreter.Here is the syntax:
java -DproxySet=true -DproxyHost=localhost -DproxyPort=80In Ant, we need to set it as:
set ANT_OPTS=-DproxySet=true -DproxyHost=localhost -DproxyPort=80
ant mytarget -
July 25, 2005 at 8:34 am #3189503
Design By Contract
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
When I first heard about DBC 4 years back, little did I know how important a role it can play in software development. But my experience in the past few years have made me wiser. I have seen so much of cluttered code where inside each method call, the first thing that is seen is the checking of all the parameters. (This is sometimes also replicated on the client side). How many times I have seen a try/catch for a condition that will never occur if the method is called correctly.The “Design By Contract” paradigm eliminates all this. It specifies that a method should have a pre-condition, a post-condition and an invariant. At first, I found the concept of invariant a bit foggy to understand.
Well, actually it is very simple. An invariant is something (in a class) which does not change. Classes should specify their invariants: what is true before and after executing any public method.
If U are planning to incorporate DBC in Ur code, then check out :
http://jcontractor.sourceforge.net/
http://c2.com/cgi/wiki?DesignByContractI feel “Unit Tests” can also play the role of checking Contracts as it is used in Extreme Programming. But may be both can be used to complement each other.
UnitTests tests for things which should happen. DesignByContract watches for things which shouldn’t. These two categories overlap somewhat, but both techniques are still useful.
-
July 25, 2005 at 8:34 am #3189502
Some good Wiki sites on the web.
by narendrn · about 18 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I cam upon this wiki as I was surfing the web, searching for more info on XP…It turned out to be a gold mine of information.. -
August 1, 2005 at 1:24 am #3195010
Specify java files names in a text file for javac.exe
by narendrn · about 18 years, 8 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Found out that there was an alternative way to pass Java source files names to the javac compiler 🙂Here’s what the Java docs say:
There are two ways to pass source code file names to javac:
– For a small number of source files, simply list the file names on the command line.
– For a large number of source files, list the file names in a file, separated by blanks or line breaks. Then use the list file name on the javac command line, preceded by an @ character. -
August 1, 2005 at 1:24 am #3195011
Changing the bootstrap classes in javac.exe
by narendrn · about 18 years, 8 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Sometimes we may wish to change the default bootstrap classes that are loaded by the java compiler while compiling.javac.exe provides us with a ‘-bootclasspath’ option for that.
I found this option useful, when I was using a older version of CORBA interfaces, which were not compatible with the “org.omg.*” CORBA interfaces in JDK 1.5. So I included the old CORBA interfaces jar file before rt.jar in the bootstrap classpath and the problem was solved.
In Eclipse, the problem was solved just by changing the order of jar files in the “Build path” menu.
-
August 1, 2005 at 5:24 am #3194970
Code coverage tools
by narendrn · about 18 years, 8 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Even if we are using JUnit and NUnit for executing our unit test cases, there are still some loopholes left. For e.g. how do we test that all paths in the code have been covered in the test cases? What code are the tests actually testing? What code isn’t being tested? Is the test suite getting out of date?Code coverage tools prove to be invaluable in such occasions. These tools instrument the code/binaries to discover those sections of the code that have not been tested.
Two such tools for Java and .NET are provided by Clover:
http://www.cenqua.com/clover/
http://www.cenqua.com/clover.net/Check out the trail versions and see the benefits Urself..
-
August 9, 2005 at 8:36 am #3052701
Java 1.4 and 1.5 compatibility problems
by narendrn · about 18 years, 8 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently I faced a peculiar problem when I had compiled a application using JDK 1.5 and then tried to run it inside TOMCAT running Java 1.4. And I got an runtime exception – Version mismatch — 0.49 should be 0.48
I was bewildered, but later on searching the NET understood that the class files generated by the JDK 1.5 compiler(v 0.49) and JDK 1.4(v 0.48) compiler are not same.My application was not using any of the new JDK 1.5 features, even then this problem was arising. I think the reason for this being the host of new features introduced in JDK1.5
For e.g. in Java 1.5, U can write:
Integer I=7; and it will compile with Java1.5 and also run inside a Java 1.5 JVM.But if the above code is run inside a Java 1.4 JVM, then it will fail. Hence SUN has put a check to ensure that there is a runtime error shown if the class files are of different versions than that of the JVM.
-
August 16, 2005 at 7:58 am #3047936
Diff btw “java.exe” and “javaw.exe”
by narendrn · about 18 years, 8 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
This is what the SUN documentation says:The javaw command is identical to java, except that with javaw there is no associated console window. Use javaw when you don’t want a command prompt window to appear. The javaw launcher will, however, display a dialog box with error information if a launch fails for some reason.
So If Ur application is 100% GUI, then U can use javaw to launch it instead of java.exe
-
August 16, 2005 at 7:58 am #3047937
Java XML processing APIs
by narendrn · about 18 years, 8 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
It’s been some time that I have worked on any new XML processing program. My favaourite Java XML library had always been JDOM (promoted by Jason Hunter) JDOM was so intutive to use for Java developers and also made excellent use of Java collections. But today, there are quite a number of alternatives that one needs to study before deciding on which library to use.Check out the following links to learn more:
http://www.artima.com/intv/jdomP.html
http://www-128.ibm.com/developerworks/xml/library/x-injava/index.html http://xml.apache.org/xerces-j/index.html
http://www.extreme.indiana.edu/soap/xpp/
http://xml.apache.org/crimson/index.html
http://jdom.org/index.html-
August 18, 2005 at 2:50 am #3048767
Java XML processing APIs
by ernst.dehaan · about 18 years, 8 months ago
In reply to Java XML processing APIs
For XML output, don’t forget xmlenc:
http://xmlenc.sourceforge.net/ -
August 21, 2005 at 7:54 am #3068274
Java XML processing APIs
by satur9 · about 18 years, 8 months ago
In reply to Java XML processing APIs
Sorry, but JDOM is hopeless for loading several megabyte documents.
I personally prefer XML frameworks, where an XSD is available, I use Castor because it is dead easy to maintain.
http://www.castor.org/xml-framework.html
-
-
August 18, 2005 at 1:00 am #3048786
JProbe – A cool cool tool
by narendrn · about 18 years, 8 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I had used JProbe in my earlier project for some basic memory profiling and performance bottleneck detection. JProbe suite consists of 3 important components:JProbe Profiler: Identify Method and Line-level Performance Bottlenecks
JProbe Memory Debugger: Investigate Memory Leaks and Garbage Collection Activity
JProbe Coverage: Measure Code Coverage After TestingRecently on visiting their site, I saw a free version of JProbe Profiler which I belive would be immensely useful to anyone doing development in Java.
http://www.quest.com/jprobe/profiler_freeware.asp -
August 18, 2005 at 5:02 am #3049736
Debugging in Java
by narendrn · about 18 years, 8 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
When I was first introduced to Java, most of the program debugging was done through console/file logging. (using the ubiquitous System.out.println).But today, we have so many GUI debuggers at our disposal. IDEs contain their own debuggers (such as IBM VisualAge for Java, Symantec VisualCafe, and Borland JBuilder, IBM Eclipse), Stand-alone GUIs (such as Jikes, Java Platform Debugger Architecture javadt, and JProbe) ,Text-based and command-line driven (such as Sun JDB)
My favourite is the Eclipse Debugger and it serves most of my purposes.
But there are some other cool stand-alone debuggers available too. Here are links to a few of them:
http://www.bluemarsh.com/java/jswat/
http://www.debugtools.com/index.html
http://freshmeat.net/projects/jikesdebugger/If any of the above still do not meet your needs, the Java platform has introduced the JavaDebugging APIs, which you may use to create a debugger that specifically meets yourneeds. The revised Java Debugger (JDB) serves as both a proof of concept for the Java DebuggingAPI, and as a useful debugging tool. It was rewritten to use the Java Debug Interface (JDI)and is part of the JDK.
Some basic fundamentals:
If you use the javac compiler to build your code for debugging, use the -g compiler option.This option lets you examine local, class instance, and static variables when debugging. You can still set breakpoints and step through your code if you do not compile your classes withthe -g option; however, you will not be able to inspect variables.
Tip: Check out the differences in ‘class’ file size when U use the ‘-g ‘ compiler option and when U do not. Also decompile both the versions of the ‘class’ file and see what extra code was inserted when U compile with the ‘-g’ option. It would be a good fun 🙂
-
August 24, 2005 at 4:57 am #3066574
More info about VNC
by narendrn · about 18 years, 8 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have been using VNC for years and I always assumed it to be a product of a company named RealVNC. It was only recently that I realised that VNC (Virtual Network Computing) is a open-source technology and had been first developmed on the Unix platform !!!…(I thought VNC works only on Windows)
We have VNC servers available for all platforms such as Unix X-window, Solaris CDE, Linux, Windows XP etc.More info can be found at :
http://www.softpanorama.org/Xwindows/vnc.shtml
http://www.realvnc.com -
August 25, 2005 at 12:58 am #3067909
Enabling FTP on Solaris
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently I wanted to enable FTP on my Solaris box and had to make quite a few changes to start the FTP server. I got a summary of all the things that should be done/checked :
#vi /etc/services – uncomment
-> ftp 21/tcp
#vi /etc/inetd.conf – uncomment
-> ftp stream tcp nowail root /usr/sbin/in.ftpd in.ftpd
# vi /etc/ftpd/ftpuser – to uncomment “root” out
-> # root
#vi /etc/shells – put in all the shell as possible
-> /usr/sbin/ksh
#vi /etc/default/login – to uncomment
-> CONSOLE=/dev/console
check http://ftp.allow and http://ftp.deny files as well
#kill -HUPpid – to restart #/usr/sbin/inetd -s -
August 25, 2005 at 12:58 am #3067908
Unix /dev/null
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In quite a few unix programs ( shell scripts) I see the following command =
someprog > /dev/null 2>&1
The > /dev/null 2>&1 part means to send any standard output to /dev/null (the linux trash can) and to redirect standard error (2) to the same place as the standard output (1). Basically it runs the command without any output to a terminal etc.
-
August 30, 2005 at 2:17 am #3046936
Convert from byte[] to string in C#.NET
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently I had to convert a byte[] array to a string in .NET. I knew that there should be some method somewhere which takes a encoding and returns the string accordingly.
I searched in the “byte[]” class, then in the “string” class, but could not find any appropriate method. Finally I found it in the System.Text.Encoding class. It has other subclasses such as
System.Text.ASCIIEncoding,System.Text.UnicodeEncoding,System.Text.UTF7Encoding,
System.Text.UTF8Encoding.Code snippet:
System.Text.Encoding enc = System.Text.Encoding.ASCII;
string myString = enc.GetString(myByteArray );I would have preferred a String Constructor which takes a byte[] and a encoding string. Much more intuitive…
-
September 8, 2005 at 6:18 am #3064258
Immutable Collections in Java
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Quite often, we may feel the need for an immutable collection, i.e. users cannot modify the collection and bring it to an invalid state, but can only read it.
The Collection API has methods to help us with this. For e.g. to get an immutable list, use the following code:List ul = Collections.unmodifiableList(list);
Check out the other methods of Collections which give you other helper methods to make collections immutable. Any attempt to modify the returned list, whether direct or via its iterator, result in an UnsupportedOperationException.
The ‘immutablity’ aspect can also be used as a design pattern for concurrent read-and-write access to a collection. (Think mutiple users or threads). Anyone who needs to modify a collection will make a copy of the collection object and modify it.
-
September 9, 2005 at 2:17 am #3063938
Double checked Locking idiom and the Singleton pattern.
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have seen a lot of programs using the double-checked locking pattern in their singleton classes to avoid the overhead of synchronization for each method call.But it is now known that the double-check locking idiom does not work. It is bcoz of the memory model of Java, which allows out-of-order writes to memory. i.e. There exists a window of time, when an instance is not null, but still not fully initiliazed(constructor has not returned) !!!
For more explanation, check out this simple and lucid article:
http://www-128.ibm.com/developerworks/java/library/j-dcl.html -
September 12, 2005 at 8:41 am #3065810
Recursively adding files to Clearcase.
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently I wanted to add a whole directory struture to Clearcase VOB and I was suprised to see that the Graphical Explorer did not have a option to recursively add an entire directory structure to source-control. Thankfully I found out a command line tool (“clearfsimport”) using
which I could import/add all directories and files to the VOB.
The general usage of the command is :clearfsimport [ ?preview ] [ ?follow ] [ ?recurse ] [ ?rmname ]
[?comment comment ] [ ?mklabel label ] [ ?nsetevent ] [ ?identical ][ ?master ] [ ?unco ] source-name [ . . . ] target-VOB-directoryFor more details RTFM or check out these links:
http://www.cmcrossroads.com/ubbthreads/showflat.php?Cat=&Number=33221
http://www.cmcrossroads.com/ubbthreads/showflat.php?Number=33343 -
September 15, 2005 at 4:43 am #3057225
Accessing Windows Registry using Java
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I always wished someone could provide me with a neat API for accessing the windows registry using Java. I did not want to get into the nitty-gritty of JNI calls..
Fortunately there is an opensource library available at:
http://www.trustice.com/java/jnireg/Check out the source code to understand it better.
-
September 15, 2005 at 4:43 am #3057226
How do download managers work?
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have often wondered how download managers worked? I wanted to know the internal working that makes it possible for these components to download faster?The main functions of a download manager are:
? Resuming interrupted downloads (i.e., downloading only the rest of the file instead of restarting theprocess from the very beginning);
? Scheduled operation: connecting to the Internet, downloading a list of specific files and disconnectingaccording to a user-defined schedule (e.g. at night when the connection quality is usually higher, while the connection rates are lower);
? some download managers have additional functions: searching for files on WWW and FTP servers byname, downloading files in several “streams” from one or from different mirror servers, etc.Most download managers use the concept of “Multi-connection downloading” – the file is downloaded in several segments through multiple connections and reassembled at the user’s PC.
To understand how this would work, we first need to understand a feature of web-servers.
A lot of webservers (http and ftp) today support the “resume download” function – what this means is that if your download is interrupted or stopped, U can resume downloading the file from where U left it. But the question now arises, how does the client(web-browser) tell the server what part of the file it wants or where to resume download? Is this a standard or server proprietary? I was suprised when I found out that it is the HTTP protocol itself that has support for “range downloads”, i.e. when U request for a resource, U can also request what portion/segment of the resource U want to download. This information is passed from the client as a HTTP header:See http header snipper below:
GET http://lrc.aiha.com/English/Training/Dldmgrs-Eng.pdf?Cache HTTP/1.1
Host: lrc.aiha.com
Accept: */*
User-Agent: DA 7.0
Proxy-Authorization: Basic bmFyZW5kcjpuYXJlbjEyNDM=
Connection: Close
Range: bytes=0-96143Now what download managers do is that they start a number of threads that download different portions of the resource. So the download manager will make another request with the header:
GET http://lrc.aiha.com/English/Training/Dldmgrs-Eng.pdf?Cache HTTP/1.1
Host: lrc.aiha.com
Accept: */*
User-Agent: DA 7.0
Proxy-Authorization: Basic bmFyZW5kcjpuYXJlbjEyNDM=
Connection: Close
Range: bytes=96143-192286
This solves the mystery of how the download managers are able to simultaneously download different portions of the resource.Imp Note: To resume interrupted downloads, it is not enough to use a download manager: the server from which the file is being downloaded should support download resumption. Unfortunately, some servers do not support thisfunction, and are called ?non-resumable.?
So Ur download managers won’t work (no increase in speed either), as the servers would ignore the HTTP “range” header.But I was still confused how exactly does this increase the speed. After all if the current bandwidth is “fully utilized” with one connection, how does making more connections help? The answers I found on the net are as below:
Normal TCP connections, as used by HTTP, encounter a maximum connection throughput well below that of the available bandwidth in circumstances with even moderate amounts of packet loss and signal latency. (so bcoz of packet loss and latency, the client will have to re-request some packets ) Multiple TCP connections can help to alleviate these effects and, in doing so, provide faster downloads and better utilization of available bandwidth.
Opening more connections means less sharing with others. Web servers are set up to split their bandwidth into several streams to support as many users downloading as possible. As an example, if the download manager created eight connections to the server, the server thinks it is transmitting to eight different users and delivers all eight streams to the same user. Each of the eight requests asks for data starting at a different location in the file.
Here are the links to some good download managers:
http://www.getright.com
http://www.internetdownloadmanager.com/
http://www.netants.com
http://www.alwaysfreeware.co.uk/dload.html -
September 16, 2005 at 5:12 am #3056739
Eating Ur own dog food :)
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I came accross this slang many a times over the last few years. So what does “eating Ur own dog food ” mean??A company that eats its own dog food sends the message that it
considers its own products the best on the market.?
?This slang was popularized during the dotcom craze when some
companies did not use their own products and thus could “not even eat
their own dog food”. An example would’ve been a software company that
created operating systems but used its competitor’s software on its
corporate computers.? -
September 20, 2005 at 1:16 am #3054437
Improving the performance of Eclipse
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I often used to get frustrated with the speed of eclipse on my machine. Then I heard from my friend how I can increase the initial memory allocated to Eclipse. U just have to pass values from the command prompt using the vmargs argument.eclipse -vmargs -Xms256m -Xmx256m
This single change, gave me a very good “perceived” performance benifit while using the IDE.
Other tips to increase the performance of Eclipse can be found at:
http://eclipsewiki.editme.com/GeneralFaq -
September 23, 2005 at 2:43 am #3061515
Diff btw “protected” access specifier in Java and .NET
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In Java, when a class is declared as ‘protected’, it is also given ‘package’ access automatically. i.e. a protected member can be accessed within the same package by other members.But in .NET, ‘protected’ access specifier means that only subclasses can see it. If we want other members of a assembly to see the ‘protected’ class, then we need to put the access specifier as ‘protected internal’.
Thus ‘protected’ in Java is equivalent to ‘protected internal’ in .NET
-
September 23, 2005 at 6:43 am #3061453
.NET Remoting fundas
by narendrn · about 18 years, 7 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.

Developers often get confused when they see the following methods (all sound the same).
RegisterWellknownServiceType()
RegisterWellknownClientType()
RegisterActivatedServiceType()
RegisterActivatedClientType()Finally I got hold of a image that explains the above in a lucid manner…
-
September 28, 2005 at 2:56 am #3062789
How does the Page’s IsPostBack property work?
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
IsPostBack checks to see whether the HTTP request is accompanied by postback data containing a __VIEWSTATE or __EVENTTARGET parameter. If there are none, then it is not a postback. -
September 28, 2005 at 2:56 am #3062788
File Upload in ASP.NET
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
There are a couple of things we need to keep in mind while doing a file-upload in ASP.NET.
If the upload fails it could be bcoz of the following reasons:
ASP.NET limits the size of file uploads for security purposes. The default size is 4 MB. This can be changed by modifying the maxRequestLength attribute of Machine.config’s
element. If we are using the HtmlInputFile html control, then we need to set the the Enctype property of the HtmlForm to “multipart/form-data” for this control to work properly, or we might get ‘null’ for the PostedFile property.
-
October 3, 2005 at 2:45 am #3073513
Diff btw ‘package’ access specifier in Java and ‘internal’ access specifier in .NET
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
At first I thought that the “package” access-specifier in Java is equivalent to the “internal” access-specifier in .NET. But actually there is a subtle difference.The ‘package’ access-specifier in Java limits the access to a particular package/namespace, where as the ‘internal’ access-specifier in .NET limits the access to the containing assembly. Now a .NET assembly can contain more than one ‘namespace’ or package.
So is there any way to restrict the scope of a member of a class to the same namespace?Suprisingly NO, there is none in .NET..So if we were designing by ‘separation of concerns’, maybe it would make sense to map one namespace to one physical assembly.
-
October 5, 2005 at 9:15 am #3057835
I still love Struts…
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have been a strong advocate of Struts right from the start. I often see developers getting confused over making a choice between struts, velocity, tiles etc.The point is that “Struts” is a “controller-centric” MVC solution. The “View” and the “Model” parts are pluggable thanks to the plug-in architecture of Struts1.1
Hence is possible to use “Tiles” or Velocity templates inplace of plain JSP for the View in Struts.
Similarly the Model can be used to interact with EJB, JDO, Hibernate…etc.The various choices available in Server-side Java may seem daunting to a new developer,but with experience we come to realize and appreciate the value of each solution and where it fits best 🙂
-
October 6, 2005 at 3:55 am #3069479
I still love Struts…
by shimonbenamy · about 18 years, 6 months ago
In reply to I still love Struts…
I started with struts when i was in the last year of my developper studies. I saw that with a big application you can work properly. I like very well the mvc model, i think it s good way to develop web application.
we are never speaking about the opensource project in the time. Struts now is a ex jakarta project without any support, anyn new version.
So , i’m loving struts but how you can provide a web application based on the struts model but you ‘re not sure that you can working with struts for a long time(more than 2 or 3 years).
You can migrate to the JSF but when you have big apllication it’s very dangerous.
But the developper are living dangerously 😉
When an opensource project close , you have a big problem.
See ya
Shimon@bxl
-
October 6, 2005 at 5:58 am #3069379
I still love Struts…
by jrmint · about 18 years, 6 months ago
In reply to I still love Struts…
I’m a Struts developer but since there hasn’t been any move in a while
since 1.2 and the original Number 1 and Number 2 committers on the
Struts project are now backing JSF implementations in place of Struts
that looks like a product with a longer lifespan. JSF is MVC just like
Struts and can use the Validator in the same way as Struts so why limit
myself to a Web Server with Struts when with a simple change to an xml
file I can have a JSF app run standalone as an applet, web site, in a
portlet in a portal or be readable with handhelds? -
October 6, 2005 at 6:10 am #3069370
I still love Struts…
by porky625 · about 18 years, 6 months ago
In reply to I still love Struts…
I would like to try it.
Any good tutorial which can helps to follow?
And by the way, which IDE will use for structs? any recommendation?
-
October 6, 2005 at 6:31 am #3069346
I still love Struts…
by johnnysacks · about 18 years, 6 months ago
In reply to I still love Struts…
I got involved with struts after reviewing the initial example of a controller servlet detailed in (as I remember) the book Core Servlets And Java Server Pages. After using the example in the book for building a tutorial project for a group of developers transitioning from ASP to Java, struts was a logical next step towards a more refined web application framework.
The reason that it’s no longer in the spotlight as an open source project may be because it has reached the limit of the functionality it was initially designed to provide. It performs a job, it performs it extremely well, and it will continue to do so.
-
October 6, 2005 at 6:49 am #3069322
I still love Struts…
by wayne m. · about 18 years, 6 months ago
In reply to I still love Struts…
As a manager, my view on Struts is more pragmatic. Struts is well defined and there is quite a bit of literature, both on the internet and in bookstores, to describe it. For this reason alone, I endorse its use in projects.
From a purely personal evaluation, and at the risk of being labeled a fire-starter, though, I find Struts to be overly complex and largely applies MVC solely for the sake of doing MVC. A developer needs to learn JSP and XML and perform indirect mapping of actions. JSP code does not promote code reuse thoughout the project and changes and corrections to data fields need to be propogated manually across many pages. This is an open invitation to errors when fields or pages are overlooked. Similar issues ocurr on the database side, though the database tends to be more static.
I am not a big fan of the MVC pattern and feel few projects actually benefit from the independence of the three layers. I find much of the purported benefit to be illusory as the differences between a stateful client-server design and a stateless web-based design affect the entire software. One cannot simply skim off the View and change a client-server to a web-based system.
Putting my personal opinions aside, however, the reality is that Struts is a defined approach and I am much more likely to find personnel and implement a project successfully using Struts than a custom approach.
-
October 6, 2005 at 6:54 am #3069313
I still love Struts…
by techrepublic@muddyga · about 18 years, 6 months ago
In reply to I still love Struts…
Struts is still alive an kicking, if you look at sites like HP support, Airlingus.com etc you’ll see its used
for business applicationsPersonally I use M7 for Struts development, they have just been bought by Bea so as regards
getting the job done its just that.We should always look to the future and new framworks but companies that have invested
in applications like to get their moneys worth. I expect Struts will be around for some time
as its a quiry bug mostly bug free framework.It great to see that JSF is being influenced by the likes of the Struts creators, for me JSF will be looked
as when developing new greenfield projects. For the others, well the run reliably and if the bosses want to
change the framework ( dont think they will pay the money ) then I’ll start strutting to JSF. -
October 6, 2005 at 10:10 am #3066175
I still love Struts…
by naveen_arur · about 18 years, 6 months ago
In reply to I still love Struts…
Struts now is a ex jakarta project without any support, any new version.
Can somebody please confirm this please?
I am new to java web development and I thought of putting some struts
skills into my tookit but if struts is no longer under development I am
not sure i want to continue my struts learning an dinstead jump on to
the jsf bandwagon
-
October 6, 2005 at 4:09 pm #3065984
I still love Struts…
by the chad · about 18 years, 6 months ago
In reply to I still love Struts…
Struts is absolutely a live project, however it–like
all the other Apache projects–has community support. Apache does not
support their products (there are some companies that may provide
support, though).Even if struts died tomorrow, who cares? We have the source and could easily extend it and continue to fix bugs. That’s THE POINT OF OPEN-SOURCE SOFTWARE, unlike closed source software. Once the company goes, that’s it for you. For example, there is a very nice application called Powertab editor.
Even though it is free to use, it is not open-source. It hasn’t been
updated in over three years or so, so it appears to be a dead product.
There is no way to fix bugs, add new features, etc., so everyone who
uses it must either live with its shortcomings or find something else.I agree that not all projects require Model II archetecture (MVC).
However, for anything that starts out small with the potential to grow,
Model II is absolutely essential. Yes, it takes a little longer to
write, but the key is maintenance. Model I is an absolute bear to maintain.For those of you who think struts is way too hard (hand editing the
config files and manually creating all the form getter/setter files, no doubt), you’re doing way too much work. Grab yourself
a copy of Struts console and Eclipse, and you’ll find these tools will automatically generate much of the mundane code one has to work with when using Struts.Cheers
-
October 6, 2005 at 4:50 pm #3065962
I still love Struts…
by atan · about 18 years, 6 months ago
In reply to I still love Struts…
We wrote an application in Apache Struts with no prior knowledge of the
framework. 3 months down the track and it was such a joy to use. And as
a bonus, at the end of the project we’d learnt more about MVC than any
textbook could possible impart. Sweet…We also used MyEclipse, Tomcat, MySQL, Hibernate, JFreeChart, Maven, iText, JUnit and DbUnit.
-
October 9, 2005 at 12:58 pm #3070187
I still love Struts…
by barddzen · about 18 years, 6 months ago
In reply to I still love Struts…
I agree somewhat that Struts is overly complex for small projects.
Example: Can Struts be used for a simple online form?
Yes. The bigger question is: Is Struts the right solution
for this particular task? IMHO, no, it’s not. Setting up
all the XML, Actions, Mappings, Validators, etc. just to capture 10
fields on a web site and send an email is over complicating something
that you could have coded in Straight JSP in less than 1 hour.Now, having said this, would I consider Struts for larger “web applications”? Absolutely.
Which is where I personally draw the line between using a framework
like Struts or any other framework. Web applications are a far
cry from simple online capture forms and keeping it simple is ALWAYS
the best approach.
-
-
October 6, 2005 at 5:17 am #3069435
Diff btw Java and C#.NET
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I came across this comprehensive document stating all the minute differences between Java and C#.NET. A good read 🙂 -
October 7, 2005 at 5:12 am #3070067
XML parsing APIs in .NET
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The .NET API has quite a few classes to help us manipulate XML data.
We have the ‘XMLReader’ class and its subclasses like ‘XMLTextReader’, ‘XMLValidatingReader’ ect that provide a forward-only, non-cached, read-only cursor to XML data. An interesting point is that XMLReader uses a ‘pull model’ unlike SAX push event model.Then we have XPathDocument that provides a fast, read-only cache for XML document processing using XSLT. Quite good if U need to use XPath to query the XML data.
We have a special class for loading a DataSet directly into a XML form for manipultion. This class is the XMLDataDocument class that can load either relational data or XML data and manipulate that data using the W3C Document Object Model (DOM).
-
October 18, 2005 at 5:53 am #3072439
XML databinding in Java using Castor
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Often in my applications, I needed to persist some Java data objects as XML. For this I used to use JDOM which was quite cool to use bcoz of its Java-like API.
But there is one more XML data binding framework known as “Castor” which can handle all the marshalling and unmarshalling of object to XML for you automatically or with the help of a mapping file. Castor is indeed a cool XML data binding framework.Furthur reading:
OnJava tutorial
http://www.castor.org/ -
October 19, 2005 at 2:00 am #3071174
GAC folder in Windows
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
When we go the default GAC folder in Windows located at : “C:\WINNT\assembly” we see the dlls that are registered in the GAC. But what if we have different versions of the same DLL registered in the GAC? How can a single Windows folder allow 2 files with the same name to exist?To understand this, go to the DOS prompt and navigate to “C:\WINNT\assembly”. Do a ‘dir’ command and see the contents. There would be a ‘GAC’ folder and inside the folder, there is a folder for each Assembly. Each assembly folder has a folder for each version. Inside this version folder there is the actual DLL. Try this out 🙂
-
October 19, 2005 at 3:00 am #3071028
GAC folder in Windows
by lukcad · about 18 years, 6 months ago
In reply to GAC folder in Windows
For everyone application Microsoft.Net creates the temporary directory in section of the corresponding application. For example, you can find it for Framework version of v1.1.4332 by this way: C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\Temporary ASP.NET Files
There you will find all your server applications running on your server, also you will find that in every directory of your running application is saved copy of assembly. In assembly we will find the copy of libraries from bin directory of virtual catalog of current application.
So you can image how a lot of structured directories also will created till your application is runnig. So if you have a lot of virtual catalogues then not wonder why you need to have mirror copy of your hard disk.;-) Some programmers love to make image disks for repair system, but i afraid with Microsoft.NET it is trick is not suitable.
Sincerely, LukCAD
-
-
October 19, 2005 at 5:58 am #3070989
Advantages of using netmodules in .NET
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I often wondered what was the advantage of compiling files into .net modules and linking them together using the Al.exe tool. I also noticed that al.exe actually only creates a stub dll, the netmodule files really have to be physically deployed too.I guess the advantage of compiling to netmodules are:
- Each module may be independently developed by a separate set of developers.
- Each module may be written in any .net language.
- A multimodule assembly does have memory advantages: if you put rarely-usedtypes in one module, that module will only be loaded when one of its types is referenced, when the type is first used. If the rarely-used types are never used in an execution of the assembly, the module is not loaded.
-
October 19, 2005 at 10:01 am #3070869
How to implement Role authorization after Forms authentication
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
After authenticating a user using forms authentication, we may want to restict access to certain parts of the website to certain users – i.e. Authorize users.To implement Role based authorization we would need to set up a database containing info about which role a user belongs to. Then we need to construct a Principal object specifying which role the user belongs to and assign it to the HttpContext user property.
An excellent article discussing this concept is at:
http://aspnet.4guysfromrolla.com/articles/082703-1.aspx -
October 20, 2005 at 2:43 am #3060648
Reusable Application blocks for .NET
by narendrn · about 18 years, 6 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I often used to write some utility classes that would simplify the coding of most used tasks.
For e.g. accessing a DataReader for binding to a grid, we have to write all the database plumbing code again and again.
Hence MS has released some utility wrapper classes that can be used to simplify such routine tasks. A good article explaining this is at http://aspnet.4guysfromrolla.com/articles/070203-1.aspxThe application blocks can be downloaded from http://www.microsoft.com/downloads
-
November 8, 2005 at 1:18 pm #3135772
Common terms in Datawarehousing.
by narendrn · about 18 years, 5 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have been interested in datawarehousing concepts for a long time, but unfortunately never got a chance to work on them. Here are some common concepts U need to know to understand any datawarehousing glibber.Data Warehousing: An enterprise-wide implementation that replicates data from the same publication table on different servers/platforms to a single subscription table. This implementation effectively consolidates data from multiple sources.
Data Warehouse: A data warehouse is a subject oriented, integrated, non volatile, time variant collection of data. The data warehouse contains atomic level data and summarized data specifically structured for querying and reporting.
Data Mining: The process of finding hidden patterns and relationships in data. For instance, a consumer goods company may track 200 variables about each consumer. There are scores of possible relationships among the 200 variables. Data mining tools will identify the significant relationships.
OLAP (On-Line Analytical Processing)
Describes the systems used not for application delivery, but for analyzing the business, e.g., sales forecasting, market trends analysis, etc. These systems are also more conducive to heuristic reporting and often involves multidimensional data analysis capabilities.OLTP (OnLine Transaction Processing)
Describes the activities and systems associated with a company’s day-to-day operational processing and data (order entry, invoicing, general ledger, etc.).Data Dictionary:
a software tool for recording the definition of data, the relationship of one category of data to another, the attributes and keys of groups of data, and so forth. -
November 8, 2005 at 1:18 pm #3135773
Preventing SQL injection attacks…
by narendrn · about 18 years, 5 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I still see a lot of applications that are vulnerable to SQL injection attacks bcoz of usage of dynamic SQL using string concatenation. It is a common myth that to circumvent SQL injection attacks we ‘have’ to use stored procedures.
Even if we are using dynamic SQL, it is pretty simple to avoid these attacks.In .NET the following techniques can be used:
Step 1. Constrain input – Validate input using client side validation and server side validation (e.g. using regular expressions)
Step 2. Use parameters with stored procedures. There is one caveat with Stored procedures. If Ur stored procedure uses the ‘EXEC’ command which takes a string, then the same vulnerability exists there too.
Step 3. Use parameters with dynamic SQL. (Yepppiee…in .NET it’s so simple to have named parameters even for dynamic SQL)Code snippet :
———————————–
SqlDataAdapter myDataAdapter = new SqlDataAdapter( “SELECT au_lname, au_fname FROM Authors WHERE au_id = @au_id”, connection);
myCommand.SelectCommand.Parameters.Add(“@au_id”, SqlDbType.VarChar, 11); myCommand.SelectCommand.Parameters[“@au_id”].Value = SSN.Text;
———————————–Other important points to be considred are using a least-privileged database account and avoiding disclosing error information to the user.
A good article discussing this is at: http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnpag2/html/paght000002.aspIn Java, one can use ‘Prepared Statements’ and ‘Stored Procedures’ to prevent SQL injection attacks.
-
November 9, 2005 at 2:38 am #3120424
On Bytes and Chars…
by narendrn · about 18 years, 5 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
During i8n and localization, we often come across basic fundamental issues such as:
– How many bytes make a character?
– How many characters/bytes are present in a string?Each character gets encoded into bytes according to a specific charset. For e.g. ASCII uses 7 bit encoding, i.e. each char is represented by 7 bits. ANSI/Cp1521 uses 8-bit encoding, Unicode uses 16 bit encoding. UTF-8, which is a popular encoding set on the internet is a multibyte Unicode charset. So if someone asks – how many bytes make a character – the answer is – it depends on the charset used to encode the character.
Another interesting point in Java is the difference btw a ‘char’ and a character.
When we do “String.length()” in Java, we get the number of chars in the string. But a Unicode character may be made up of more than one ‘char’.
This blog throws light on this concept: http://forum.java.sun.com/thread.jspa?threadID=671720Snippet from the above blog:
———————————
A char is not necessarily a complete character. Why? Supplementary characters exist in the Unicode charset. These are characters that have code points above the base set, and they have values greater than 0xFFFF. They extend all the way up to 0x10FFFF. That’s a lot of characters. In Java, these supplementary characters are represented as surrogate pairs, pairs of char units that fall in a specific range. The leading or high surrogate value is in the 0xD800 through 0xDBFF range. The trailing or low surrogate value is in the 0xDC00 through 0xDFFF range. What kinds of characters are supplementary? You can find out more from the Unicode site itself.
So, if length won’t tell me home many characters are in a String, what will? Fortunately, the J2SE 5.0 API has a new String method: codePointCount(int beginIndex, int endIndex). This method will tell you how many Unicode code points are between the two indices. The index values refer to code unit or char locations, so endIndex – beginIndex for the entire String is equivalent to the String’s length. Anyway, here’s how you might use the method:
int charLen = myString.length();
int characterLen = myString.codePointCount(0, charLen);
-
November 9, 2005 at 6:38 am #3120339
Understanding Unicode
by narendrn · about 18 years, 5 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I still see many people with a lot of myths about Unicode. I guess the reason for this is that a lot of people still feel that Unicode is a encoding format that uses 16 bits to represent a character.
Let’s put a few things in perspective here:Unicode is a standard which has defined a character code for every character in most of the speaking languages in the world. Also it has defined a character code for items such as scientific, mathematical, and technical symbols, and even musical notation. These character codes are also known as code points.
Unicode characters may be encoded at any code point from U+0000 to U+10FFFF, i.e. Unicode reserves 1,114,112 (= 220 + 216) code points, and currently assigns characters to more than 96,000 of those code points. The first 256 codes precisely match those of ISO 8859-1, the most popular 8-bit character encoding in the “Western world”; as a result, the first 128 characters are also identical to ASCII.
The number of bits used to represent each code point may differ – e.g. 8 bits, 16 bits.
The size of the code unit used for expressing those code points may be 8 bits (for UTF-8), 16 bits (for UTF-16), or 32 bits (for UTF-32).
So what this means is that there are several formats for storing Unicode code points. When combined with the byte order of the hardware (BE or LE), they are known officially as “character encoding schemes.” They are also known by their UTF acronyms, which stand for “Unicode Transformation Format”UTF-8 is widely used because the first 128 bits in the byte are ASCII, and although up to four bytes can be used, only one byte is required for use in the English speaking world. UTF-16 and UTF-32 use a fixed number of bytes.
So to put in other words, Unicode text can be represented in more than one way, including UTF-8, UTF-16 and UTF-32. So, hey…what’s this UTF ?
A Unicode transformation format (UTF) is an algorithmic mapping from every Unicode code point to a unique byte sequence. UTF-8 is most common on the web. UTF-16 is used by Java and Windows. UTF-32 is used by various Unix systems. The conversions between all of them are algorithmically based, fast and lossless. This makes it easy to support data input or output in multiple formats, while using a particular UTF for internal storage or processing.
For more information visit http://www.unicode.org/faq/
-
November 17, 2005 at 12:50 am #3131533
StringBuilder in Java 5.0
by narendrn · about 18 years, 5 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
There is a new class in Java5.0 – StringBuilder class that can be used whenever we are doing some heavy-duty string manipulation and we do not wish to get bogged down by the immutable property of strings.
But then what happened to the old good StringBuffer class. Well, it’s still there.
Here’s what the JavaDoc says:This StringBuilder class provides an API compatible with StringBuffer, but with no guarantee of synchronization. This class is designed for use as a drop-in replacement for StringBuffer in places where the string buffer was being used by a single thread (as is generally the case). Where possible, it is recommended that this class be used in preference to StringBuffer as it will be faster under most implementations.
Instances of StringBuilder are not safe for use by multiple threads. If such synchronization is required then it is recommended that StringBuffer be used.
-
November 24, 2005 at 1:21 am #3113906
Thread pools in Java
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have often used thread pools in my applications. My favourite opensource thread pool was the PooledExecutor class written by Doug Lea (available here )But it’s also important to understand when to use thread pools and when not to use. I recently came across a good article on the web – http://www-128.ibm.com/developerworks/java/library/j-jtp0730.html
In this article the author argues that using thread pools makes sense whenever U have a large number of tasks that need to be processed and each task is short-lived. For e.g. Webservers, FTP servers etc.
But when the tasks are long running and few in number it may make sense to actually spawn a thread for each task. Another common threading model is to have a single background thread and task queue for tasks of a certain type. AWT and Swing use this model, in which there is a GUI event thread, and all work that causes changes in the user interface must execute in that thread.Java 5.0 has come up with a new package java.util.concurrent that contains a lot of cool classes if U need to implement threading in Ur applications.
-
November 24, 2005 at 1:21 am #3113905
Doug Lea’s Home Page
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have been impressed with the genius of Doug Lea when I saw his concurrent package in Java. His home page contains a lot of interesting links : http://gee.cs.oswego.edu/dl/
Chief among them are :
- A online OO book : http://gee.cs.oswego.edu/dl/oosdw3/index.html
- Roles Before Objects : http://gee.cs.oswego.edu/dl/rp/roles.html
This page is worth a perusal.
-
November 24, 2005 at 5:20 am #3113870
Object pooling in Java
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Quite often, we may have to use object pooling to conserve resources and increase performance.
I came across some pretty good abstract components that can be used to develop a object pooling mechanism.Check out the followling link to see all the classes that are available for use:
http://jakarta.apache.org/commons/pool/An interesting aspect of the package was the clear separation of object creation from the way the objects are pooled. There is a PoolableObjectFactory interface that provides a generic interface for managing the lifecycle of a pooled instance.
By contract, when an ObjectPool delegates to a PoolableObjectFactory : –
makeObject is called whenever a new instance is needed.
activateObject is invoked on every instance before it is returned from the pool.
passivateObject is invoked on every instance when it is returned to the pool.
destroyObject is invoked on every instance when it is being “dropped” from the pool (whether due to the response from validateObject, or for reasons specific to the pool implementation.)
validateObject is invoked in an implementation-specific fashion to determine if an instance is still valid to be returned by the pool. It will only be invoked on an “activated” instance.-
December 8, 2005 at 12:42 am #3130041
Object pooling in Java
by rstrydom · about 18 years, 4 months ago
In reply to Object pooling in Java
Hi,
I have found the performance in the jakarta commons pool to be very
poor, to such an extent that I have thrown it away for a custom written
solution.Regards,
Rudi
-
December 8, 2005 at 5:54 am #3129910
Object pooling in Java
by mjremijan · about 18 years, 4 months ago
In reply to Object pooling in Java
I would have to agree the performance is very bad. Since I deal with building Strings a lot I thought it might be a good idea to create a pool of StringBuffers instead of creating new objects every time. The performance with jakarta commons pool was terrible. I don’t know of it’s just a matter of synchronization making it slow or the way the jakarta commons pool is designed.
-
December 8, 2005 at 8:25 am #3124819
Object pooling in Java
by absolutezero · about 18 years, 4 months ago
In reply to Object pooling in Java
I have seen very specific uses for this object. To increase performance, I will create a pool of managed connections to a datastore and recycle those. This enhances performance as I don’t have to deal with object creation, looking up connection parameters, authentication, and so forth…
Performance issues some people have seen with the object pool might actually result from other factors. Consider the types of objects a developer is pooling. Does it make good engineering sense to place those objects in a pool? Also examine how the pooled objects are constructed and operate as they may be causing the reduction in performance.
As for me, I have not experienced any problems using the apache objects.
-
December 10, 2005 at 5:24 pm #3124191
Object pooling in Java
by shahinianrazmik · about 18 years, 4 months ago
In reply to Object pooling in Java
Insert comment text here
It is a very bad idea (it is even problematic) to define methods as throwing generic Exception.
One must define some checked exceptions and use it instead of declaring the methods with throws Exception.
I hope that you do not need more details or examples on pitfalls of your declarations.
-
December 12, 2005 at 7:04 am #3120868
Object pooling in Java
by jslarochelle · about 18 years, 4 months ago
In reply to Object pooling in Java
I am surprised to see this discussion about object pooling since I have
read that this is a bad idea with latest VM and could actually worsen
performance by throwing off the GC (except for Thread object were
overhead of creation is actually quite large).
-
-
November 25, 2005 at 1:22 am #3122794
Making web service proxy URL dynamic in .NET
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In VS.NET, whenever we add a web-reference to a webservice, what happens behind the scenes is that a proxy is created which contains the URL to the webservice.Now if we need to shift the webservice to a production server, do we have to create the proxy again?. (The IP address of the webservice server would have changed)
Fortunately there is a easy way out. Just right-click on the proxy in VS.NET and change its URL property from ‘static’ to ‘dynamic’. And Voila !!!, VS.NET automatically adds code to the proxy class and web.config. The newly added code in the proxy will first check for a URL key in the web.config and use it to bind to the webservice.
So when we move the webservice to a different server, we just have to change the URL in the web.config file. -
November 25, 2005 at 1:22 am #3122795
Ruminating on Transactions
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Most of us have worked on transactions one time or the other. Transactions can be broadly classified as local or distributed.
Local transactions are of the simplest form in which the application peforms CRUD operations with a single datasource/database. The simplest form of relational database access involves only the application, a resource manager, and a resource adapter. The resource manager can be a relational database management system (RDBMS), such as Oracle or SQL Server. All of the actual database management is handled by this component.
The resource adapter is the component that is the communications channel, or request translator, between the “outside world,” in this case the application, and the resource manager. In Java applications, this is a JDBC driver.In a distributed transaction, the transaction accesses and updates data on two or more networked resources, and therefore must be coordinated among those resources.
These resources could consist of several different RDBMSs housed on a single sever, for example, Oracle, SQL Server, and Sybase; or they could include several instances of a single type of database residing on a number of different servers. In any case, a distributed transaction involves coordination among the various resource managers. This coordination is the function of the transaction manager. The transaction manager is responsible for making the final decision either to commit or rollback any distributed transaction. A commit decision should lead to a successful transaction; rollback leaves the data in the database unalteredThe first step of the distributed transaction process is for the application to send a request for the transaction to the transaction manager. Although the final commit/rollback decision treats the transaction as a single logical unit, there can be many transaction branches involved. A transaction branch is associated with a request to each resource manager involved in the distributed transaction. Requests to three different RDBMSs, therefore, require three transaction branches. Each transaction branch must be committed or rolled back by the local resource manager. The transaction manager controls the boundaries of the transaction and is responsible for the final decision as to whether or not the total transaction should commit or rollback. This decision is made in two phases, called the Two-Phase Commit Protocol.
In the first phase, the transaction manager polls all of the resource managers (RDBMSs) involved in the distributed transaction to see if each one is ready to commit. If a resource manager cannot commit, it responds negatively and rolls back its particular part of the transaction so that data is not altered.
In the second phase, the transaction manager determines if any of the resource managers have responded negatively, and, if so, rolls back the whole transaction. If there are no negative responses, the translation manager commits the whole transaction, and returns the results to the application.
-
November 25, 2005 at 5:22 am #3122742
Microsoft Enterprise Application blocks
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently, Microsoft’s Pattern & Practices Group has released the Enterprise Library, a large configurable and extensible software library that consists of seven integrated application blocks.
For more information and download visit http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnpag2/html/entlib.asp
The application blocks that comprise the Enterprise Library are the following:
Caching Application Block. This application block allows developers to incorporate a local cache in their applications.
Configuration Application Block. This application block allows applications to read and write configuration information.
Data Access Application Block. This application block allows developers to incorporate standard database functionality in their applications.
Cryptography Application Block. This application block allows developers to include encryption and hashing functionality in their applications.
Exception Handling Application Block. This application block allows developers and policy makers to create a consistent strategy for processing exceptions that occur throughout the architectural layers of enterprise applications.
Logging and Instrumentation Application Block. This application block allows developers to incorporate standard logging and instrumentation functionality in their applications.
Security Application Block. This application block allows developers to incorporate security functionality in their applications. Applications can use the application block in a variety of situations, such as authenticating and authorizing users against a database, retrieving role and profile information, and caching user profile information. -
December 2, 2005 at 12:05 am #3129320
User Defined Functions Vs Stored Procedures
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Most databases have built-in functions, such as GetDate, DateAdd, and ObjectName. Such built-in functions are useful, but you can?t alter their functionality in any way, and that?s why UDFs are so powerful and necessary. UDFs allow you to add custom solutions for unique application-specific problems.
A UDF is actually a kind of subroutine that contains T-SQL statements and can return a scalar value or a table value. Hence U can call a UDF from a SELECT statement. Whereas a Stored Procedure needs to be invoked using the ‘EXEC’ command.
So when to use what? The answer depends on the problem situation. If you have an operation such as a query with a FROM clause that requires a rowset be drawn from a table or set of tables, then a function will be your appropriate choice. However, when you want to use that same rowset in your application the better choice would be a stored procedure.The other differences btw a UDF and a Stored Procedure are as follows:
- A stored prodecure supports output parameters, whereas a UDF does not.
- A UDF can have a return value (scalar or table). A SPROC can create a table, but cannot return it. It can only return a integer (as status code)
- SPROCs are powerful enough to change server environment variables. UDFs are not.
- SPROCs can be used in the FOR XML clause but UDFs can’t be.
- Whenever an error occurs in a UDF, the function stops immediately. In a SPROC, we must include error handling code, or the next statement is processed.
- U can ‘join’ to a UDF, but cannot ‘join’ to a SPROC.
-
December 2, 2005 at 8:08 am #3129168
DataReader Vs DataSet in ADO.NET
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Came across a wonderful article on MSDN which contrasts the use of DataReader Vs DataSet.
The article is available at : http://msdn.microsoft.com/msdnmag/issues/04/06/DataPoints/Salient points of the article:
- A DataReader is a stream of data that is returned from a database query. When the query is executed, the first row is returned to the DataReader via the stream. The stream then remains connected to the database, poised to retrieve the next record. The DataReader reads one row at a time from the database and can only move forward, one record at a time. As the DataReader reads the rows from the database, the values of the columns in each row can be read and evaluated, but they cannot be edited.
- The DataReader can only get its data from a data source through a managed provider. The DataSet can also get its data from a data source via a managed provider, but the data source can also be loaded manually, even from an XML file on a hard drive.
- The DataReader supports access to multiple resultsets, one at a time, in the order they are retrieved. (Methods to checkout are NextResult() and Read() )
- When the SqlDataAdapter’s Fill method is executed it opens its associated SqlConnection object (if not already open) and issues its associated SqlCommand object against the SqlConnection. Behind the scenes, a SqlDataReader is created implicitly and the rowset is retrieved one row at a time in succession and sent to the DataSet. Once all of the data is in the DataSet, the implicit SqlDataReader is destroyed and the SqlConnection is closed.
- The DataSet’s disconnected nature allows it to be transformed into XML and sent over the wire via HTTP if appropriate. This makes it ideal as the return vehicle from business-tier objects and Web services. A DataReader cannot be serialized and thus cannot be passed between physical-tier boundaries where only string (XML) data can go.
- There are other times when a DataReader can be the right choice, such as when populating a list or retrieving 10,000 records for a business rule. When a huge amount of data must be retrieved to a business process, even on a middle tier, it can take a while to load a DataSet, pass the data to it on the business tier from the database, and then store it in memory. The footprint could be quite large and with numerous instances of it running (such as in a Web application where hundreds of users may be connected), scalability would become a problem. If this data is intended to be retrieved and then traversed for business rule processing, the DataReader could speed up the process as it retrieves one row at a time and does not require the memory resources that the DataSet requires.
-
December 5, 2005 at 8:12 am #3128264
Cool APIs for packet sniffing
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A few years back, I often used to lament on the lack of packet sniffing API’s available in Java or C#.NET. I knew of the WinPcap library, but I wanted a wrapper around it. Fortunately some good guys in the open source community have build these wrappers around WinPcap.Check out the following links:
http://www.tamirgal.com/home/dev.aspx?Item=SharpPcap (A C# API)
http://sourceforge.net/projects/jpcap (A Java API)
http://www.winpcap.org/
http://www.tcpdump.org/ -
December 5, 2005 at 8:12 am #3128263
Quick HEX dump utility in DOS
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently, I wanted to see the hex dump of a binary file on a server. The server machine did not have my favourite hex GUI editors. I struggled to download a hex dump utility from the web, when my friend showed me how to use the ‘debug.exe’ tool in DOS to get a hex dump of a file.
On the DOS prompt type :
C:\>debug
-d
———————–
The ‘d’ (dump) option would dump the first 128 bytes. Typing ‘d’ again would give the hex dump of the next block of bytes.U can type ‘?’ to get a list of all the commands. Type ‘q’ to quit from debug mode.
-
December 6, 2005 at 8:36 am #3126786
Ruminating on Database Cursors
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Cursors are database objects that allow us to manipulate data in a set in a row-by-row basis or on a group of rows at one time. Cursors are quite popular among database developers as the row can be updated at the same time itself. There is no need to fire a separate SQL query.But there is also a lot of confusion regarding the exact definition of cursors, because different people use it in different contexts. For e.g. when a database administrator talks of cursors, he means the server-side cursor he uses inside stored procedures. But if a JDBC application developer talks about a cursor, he may mean the pointer in the JDBC ResultSet object.
I did a bit of reseach on the web, and finally cleared a few cobwebs from the head. Here’s a snapshot of what I learned:- There are implicit cursors and explicit cursors. An implicit cursor is – well, that’s just a piece of memory used by the database server to work with resulsets internally. Implicit cursors are not accessible via an externally exposed API, whereas explicit cursors are.
- Server-side cursors and Client-side cursors: The difference between a client-side cursor and a server-side cursor in classic ADO is substantial and can be confusing. A server-side cursor allows you to manipulate rows on the server through calls on the client, usually storing all or a portion of the data in TEMPDB. The client-side cursor fetches data into a COM object on the client. Its name comes from the fact that the buffered data on the client exhibits cursor-like behaviors you can scroll through and, potentially, update it. The behavior difference manifests itself in a few ways. Fetching a large resultset into a client cursor causes a big performance hit on the initial fetch, and server cursors result in increased memory requirements for SQL Server and require a dedicated connection all the time you’re fetching. Client-side cursors can be dangerous because using them has the side effect of retrieving all records from the server that are a result of your command/SQL statement. If you execute a procedure or SQL statement that could retrieve 10,000 records, and use a client-side cursor, you had better have enough memory to hold 10,000 records on the client. Also, control will not return to your code/application until all of these records are retrieved from the server, which can make your application appear slow to users. If you suspect that you are going to retrieve a large number of rows, client-side cursors are not the way to go.
- DYNAMIC, STATIC, and KEYSET cursors: Dynamic cursors will show changes made on the base table as you scroll through the cursor. Static cursors copy the base table, to the tempdb. The cursor then reads from the tempdb, so any changes happening on the base table will not be reflected in the cursors scrolling. Keysets are in between Dynamic and Static cursors. A keyset will copy the base table’s selected records keys into the tempdb, so the cursor will select the rows from the tempdb, but the data from the base table. So change to the base table will be seen, but new record inserts will not be.
Next, I tried to find out how these cursors can be manipulated using .NET and Java APIs.
In .NET, the DataReader object acts as a wrapper class for a server-side cursor. The DataReader provides a read-only and forward-only cursor. More info about this is here.
In JDBC, we handle everything using ResultSet objects. Since JDBC 2.0/3.0, we have ResultSets that are scrollable backwards and also that allow update operations. So I believe if U configure a ResultSet to be scrollable backwards and allow update opeartions, U are essentially dealing with a server-side cursor.
Code snippet:
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_READ_ONLY);
ResultSet srs = stmt.executeQuery(“SELECT COF_NAME, PRICE FROM COFFEES”);
———————————————————————————
The above code makes the ResultSet as scroll-sensitive, so it will reflect changes made to it while it is open. This is the equivalent of a dynamic cursor. In a dynamic cursor, the engine repeats the query each time the cursor is accessed so new members are added and existing members are removed as the database processes changes to the database.
The second argument is one of two ResultSet constants for specifying whether a result set is read-only or updatable: CONCUR_READ_ONLY and CONCUR_UPDATABLE.
Specifying the constant TYPE_FORWARD_ONLY creates a nonscrollable result set, that is, one in which the cursor moves only forward. If you do not specify any constants for the type and updatability of a ResultSet object, you will automatically get one that is TYPE_FORWARD_ONLY and CONCUR_READ_ONLY (as is the case when you are using only the JDBC 1.0 API). You might keep in mind, though, the fact that no matter what type of result set you specify, you are always limited by what your DBMS and driver actually provide.
-
December 8, 2005 at 12:33 am #3130045
What are Multi-dimensional databases?
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A multidimensional database (MDB) is a type of database that is optimized for data warehouse and online analytical processing (OLAP) applications. Multidimensional databases are frequently created using input from existing relational databases.A multidimensional database – or a multidimensional database management system (MDDBMS) – implies the ability to rapidly process the data in the database so that answers can be generated quickly. A number of vendors provide products that use multidimensional databases. Approaches to how data is stored and the user interface vary.
Conceptually, a multidimensional database uses the idea of a data cube to represent the dimensions of data available to a user. For example, “sales” could be viewed in the dimensions of product model, geography, time, or some additional dimension. In this case, “sales” is known as the measure attribute of the data cube and the other dimensions are seen as feature attributes. Additionally, a database creator can define hierarchies and levels within a dimension (for example, state and city levels within a regional hierarchy).
More information can be at:
http://flame.cs.dal.ca/~panda/overview.html
http://www.dba-oracle.com/cou_mdb_class.htm-
December 14, 2005 at 8:19 am #3121440
What are Multi-dimensional databases?
by awolfe_ii · about 18 years, 4 months ago
In reply to What are Multi-dimensional databases?
I never quite got the idea of MDBs. It always struck me that each table column is a dimension anyway.
This post supports my suspicion that MDB is primarily a query/UI mechanism rather than a form of new data modeling construct, perhaps supported by special SQL row/group functions. Granted, of course, that special DB features under the covers can greatly accelerate such highly specialized types of queries, but as a data-model-oriented guy, that doesn’t sound like ‘a new type of database.’
So am I understanding MDBs correctly?
-
-
December 8, 2005 at 4:34 am #3129973
Data Modelling Vs OO Modelling
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
While working on projects, often I had tussles with erst-while database developers who used to drive the design of the system using Data Models. Most of them came from non-OO background and were apt in ER diagrams. But the porblem is that a Data Model cannot and should not drive the OO model. I came across this excellent article by Scott Ambler discussing this dilemma.http://www.agiledata.org/essays/drivingForces.html
In the above article, the author argues that object schemas can be quite different from physical data schemas. Using two lucid examples he shows how different object schemas can map to the same data schema and how it is possible for a single object schema to correctly map to several data schemas.
There are situations where OO varies significantly from ERD, for example in cases of inheritance and non-persistent classes.
Aslo, OO models can convey more specification on the class diagram in representing certain things like associations than ERD can.I personally believe that if U are building a OO system, then we should first go for OO Class modelling and then think about resolving the OO-relational database impedance mismatch.
-
December 8, 2005 at 4:34 am #3129974
Cool Free Data Models
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
While browsing the web, I came across this cool site which has over 200 data-models samples.
Great for anyone who wants to learn about data-modelling or have a template for a given problem domain.The link is here : http://www.databaseanswers.org/data_models/index.htm
Some interesting data models I found in this site are – datamodels for Hierarchies , e-commerce etc. Worth a perusal.
-
December 8, 2005 at 4:34 am #3129972
Tools used in SDLC
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I decided to list down all the available tools for different phases of a SDLC. Here it goes:Requirements Management:
– DOORS: Dynamic Object Oriented Requirements System
– RequisitePro : A requirements management tool from Rational Software
– Requirements Traceability Management (RTM)Design:
– ArgoUML: http://argouml.tigris.org/
-Rational Rose http://www.rationalrose.com/
-Enterprise Architect http://www.sparxsystems.com.au/
-Rhapsody http://www.ilogix.com/homepage.aspx
-ERwin http://www3.ca.com/solutions/Product.aspx?ID=260
-Rational Rose Real Time http://www-128.ibm.com/developerworks/rational/products/rose
-Describe http://www.embarcadero.com/products/describe/
-MagicDraw http://www.magicdraw.com/
-SmartDraw: http://www.smartdraw.com/examples/software-erd/
-Visio : http://www.mvps.org/visio/Code Generation:
-OptimalJ: http://www.compuware.com/products/optimalj/
– Rational Application Developer
–Object Frontier
–JVider is Java Visual Interface Designer which helps with GUI building for Swing applicationsUnit Testing:
-Jtest: http://www.parasoft.com/jsp/home.jsp
-JUnit: http://www.junit.org/Load Testing:
SilkPerformer is load performance testing tool.
LoadRunner
JMeter
ANTS Load
Microsoft Web Application Stress Tool
Web Testing/ GUI testing:
SilkTest from Segue Software
Rational ROBOT
WinRunnerConfiguration Management Tools:
Concurrent Version System – CVS
Subversion
Clearcase
Visual SourceSafeDocumentation:
FramemakerWill keep augmenting this list…
-
December 13, 2005 at 1:40 am #3197808
Deleting duplicate rows from a table
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
This seems to a favourite question during interviews – How to delete duplicate rows in a table?
Well, we can have many strategies:– Capture one instance of the unique rows using a SELECT DISTINCT .., and dump the results into a temp table. Delete all of the rows from the original table and then insert the rows from the temp table back into the original table.
– If there is an identity column, the we can also write a query to get all the rows that have duplicate entries :
SELECT Field1, Field2, Count(ID)
FROM Foo1
GROUP BY Foo1.Field1, Foo1.Field2
HAVING Count(Foo1.ID) > 1
—————————–
Then loop thru the resultset and get a cursor for the query
“SELECT Field1, Field2, ID
FROM Foo1
WHERE Field1 = @FIELD1 and Field2 = @FIELD2″.
Use the cursor to delete all the duplicate rows returned except one.The following links discuss the above techniques and some more:
-
December 14, 2005 at 3:20 am #3127186
Locking in Databases
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Databases support different types of locking strategies. We have optimistic locking strategies where concurrency would be more, but data integrity would be less. We have pessimistic locking strategies where concurrency is less, but there is more data integrity. Basically when it comes to locking and transaction isolation levels, its a trade-off between data integrity and concurrency.
Databases supports various levels of lock granularity. The lowest level is a single row. Sometimes, the database doesn’t have enough resources to lock each individual
row. In such cases, the database can acquire locks on a single data or index page, group of pages, or an entire table. The granularity of locks depends on the memory available to the database. Servers with more memory can support more concurrent users because they can acquire and release more locks.We can give locking hints to the database while sending queries that would help us override locking decisions made by the database. For instance, in SQL Server. we can specify the ROWLOCK hint with the UPDATE statement to convince SQL Server to lock each row affected by that data modification.
While dealing with transactions, the type of locking used depends on the Transaction Isolation Level specified for that particular transaction.
SQL Server supports implicit and explicit transactions. By default, each INSERT, UPDATE, and DELETE statement runs within an implicit transaction.Explicit transactions, on the other hand, must be specified by the programmer. Such transactions are included in
BEGIN TRANSACTION … COMMIT TRANSACTION blockThere are two common types of locks present in all databases- Shared locks and Exclusive locks.
Shared locks (S) allow transactions to read data with SELECT statements. Other connections are allowed to read the data at the same time; however, no transactions are allowed to modify data until the shared locks are released.
Exclusive locks (X) completely lock the resource from any type of access including reads. They are issued when data is being modified through INSERT, UPDATE and DELETE statementsLocking/Transaction Isolation levels solve the following concurrency problems:
- Lost Updates: Lost updates occur when two or more transactions select the same row and then update the row based on the value originally selected. Each transaction is unaware of other transactions. The last update overwrites updates made by the other transactions, which results in lost data.
- Dirty Read: Uncommitted dependency occurs when a second transaction selects a row that is being updated by another transaction. The second transaction is reading data that has not been committed yet and may be changed by the transaction updating the row.
- Nonrepeatable Read: Inconsistent analysis occurs when a second transaction accesses the same row several times and reads different data each time.
- Phantom reads: These occur when an insert or delete action is performed against a row that belongs to a range of rows being read by a transaction. The transaction’s first read of the range of rows shows a row that no longer exists in the second or succeeding read, as a result of a deletion by a different transaction. Similarly, as the result of an insert by a different transaction, the transaction’s second or succeeding read shows a row that did not exist in the original read.
These concurrency problems can be solved using the correct transaction isolation level in our programs. To balance between high concurrency and data integrity, we can choose from the following isolation levels:
- READ UNCOMMITTED: This is the lowest level where transactions are isolated only enough to ensure that physically corrupt data is not read. Does not protect against dirty read, phantom read or non-repeatable reads.
- READ COMMITTED: The shared lock is held for the duration of the transaction, meaning that no other transactions can change the data at the same time. Protects against dirty reads, but the other problems remain.
- REPEATABLE READ: This setting disallows dirty and non-repeatable reads. But phantom reads are still possible.
- SERIALIZABLE: This is the highest level, where transactions are completely isolated from one another. Protects against dirty read, phantom read and non-repeatable read.
There are other types of locks available in the database such as ‘update lock’, ‘intent lock’, ‘schema lock’ etc. The update lock prevents deadlocks in the database. For more information about these check out the following links:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/acdata/ac_8_con_7a_6fhj.asp
http://www.awprofessional.com/articles/article.asp?p=26890&rl=1
-
December 14, 2005 at 7:24 am #3121475
Proxy setting for .NET programs
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
To access an internet site thru a .NET program U may have to go thru Ur company proxy.
Here’s the sample code for doing so:string query=”
http://narencoolgeek.blogspot.com
“;
WebProxy proxyObj = new WebProxy(“10.10.111.19”, 8080) ;
NetworkCredential networkCredential = new NetworkCredential(“username”, “secret_password”) ;
HttpWebRequest req = (HttpWebRequest)HttpWebRequest.Create(query) ; proxyObj.Credentials = networkCredential ;
req.Proxy = proxyObj ;For proxy setting in Java programs click here.
-
December 14, 2005 at 7:24 am #3121474
Duplicate Form Submission and the Synchronizer Token pattern
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
The Synchronizer Token pattern addresses the problem of duplicate form submissions. A synchronizer token is set in a user’s session and included with each form returned to the client. When that form is submitted, the synchronizer token in the form is compared to the synchronizer token in the session. The tokens should match the first time the form is submitted. If the tokens do not match, then the form submission may be disallowed and an error returned to the user. Token mismatch may occur when the user submits a form, then clicks the Back button in the browser and attempts to resubmit the same form.On the other hand, if the two token values match, then we are confident that the flow of control is exactly as expected. At this point, the token value in the session is modified to a new value and the form submission is accepted.
Struts has inbuild support for the Synchronizer Token pattern. Method such as “saveToken()” and “isTokenValid()” are present in the ActionForm class.
Other ways of preventing a duplicate submit is using javascript to disable the submit button after it has been pressed once. But this does not work well with all browsers.
-
December 20, 2005 at 5:29 am #3197347
Is Swing really slow?
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Often I have heard people complain that Swing Apps are slow. I also have had some bad experiences with slow Swing Apps, but then I have also seen some very cool high performant applications. So, what’s the secret of these fast Swing apps. I think the reason can be found in James Gosling’s answer:The big problem that Swing has is that it’s big and complicated. And the reason that it’s big and complicated is that it is the most fully featured, flexible, whatever-way-you-want-to-measure-it UI [user interface] tool kit on the planet. You can do the most amazing things with Swing. It’s sort of the 747 cockpit of UI design tool kits, and flying a 747 is a little intimidating, and what people really want is a Cessna.
It is definately possible to write good speedy Swing applications, but U need to be a master of Swing and threading and know all the potholes which hog memory.Here are a few links which contain some good info on fast Swing apps:
http://www.swingwiki.org/table_of_contents
http://www.javalobby.org/articles/swing_slow/index.jsp
http://www.clientjava.com/blog
http://www.javaworld.com/channel_content/jw-awt-index.shtml
http://www.javalobby.org/eps/galbraith-swing-1/index.html -
December 21, 2005 at 5:27 am #3196818
O/R mapping tools
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have had some experience with some O/R mapping tools such as TopLink and Hibernate.
But I did not know that the market is flooded with a variety of OR tools.
Here are a few of them:Abra – http://abra.sourceforge.net
BasicWebLib – http://basicportal.sourceforge.net/
Castor – http://castor.exolab.org
Cayenne – http://objectstyle.org/cayenne/
DataBind – http://databind.sourceforge.net
DB VisualArchitect – http://www.visual-paradigm.com/dbva.php
EnterpriseObjectsFramework – http://www.apple.com/webobjects/
Expresso – http://www.jcorporate.com
FireStorm – http://www.codefutures.com/products/firestorm
Hibernate – http://www.hibernate.org
Hydrate – http://hydrate.sourceforge.net
iBATIS DB Layer – http://www.ibatis.com
Infobjects ObjectDRIVER- http://www.infobjects.com
InterSystems Cache – http://www.intersystems.com
Jakarta ObjectRelationalBridge – http://db.apache.org/ojb
Java Ultra-Lite Persistence (JULP) – http://julp.sourceforge.net
Jaxor – http://jaxor.sourceforge.net
JdoGenie – http://www.jdogenie.com
JDOMax – http://www.jdomax.com
JDX – http://www.softwaretree.com
KodoJdo – http://www.solarmetric.com/Software/Kodo_JDO/
LiDO – http://www.libelis.com
O/R Broker – http://orbroker.sourceforge.net/
Persistence EdgeXtend – http://www.persistence.com/products/edgextend/
PlanetJ’s WOW = http://planetjavainc.com/wow.html
PowerMapJdo – http://www.powermapjdo.com
Signsoft intelliBO – http://www.intellibo.com
SimpleOrm – http://www.SimpleOrm.org
SpadeSoft XJDO – http://www.spadesoft.com
Sql2java – http://sql2java.sf.net
Sun Microsystem certified (SunTone?) – FrontierSuite? for J2EE & J2SE – http://www.objectfrontier.com
Sun Microsystem certified (SunTone?) – FrontierSuite? for JDO – http://www.objectfrontier.com
The ProductivityEnvironmentForJava (PE:J) – http://www.hywy.com/
TopLink – http://otn.oracle.com/products/ias/toplink/content.html
VBSF – http://www.objectmatter.comAlso the following articles give some some good introduction to O-R mapping tools and their comparisions:
http://c2.com/cgi-bin/wiki?ObjectRelationalToolComparison -
December 22, 2005 at 1:48 am #3198186
Ruminating on ClassLoaders in JVM.
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
One interesting point about ClassLoaders is that it is possible for the same class to be loaded separately by different class-loaders, resulting in multiple copies of the class object.
I came across a good synopsis on classloaders here : http://www.onjava.com/pub/a/onjava/2003/04/02/log4j_ejb.htmlHere are some snippets from the above article:
Classloaders, as the name suggests, are responsible for loading classes within the JVM. Before your class can be executed or accessed, it must become available via a classloader. Given a class name, a classloader locates the class and loads it into the JVM. Classloaders are Java classes themselves. This brings the question: if classloaders are Java classes themselves, who or what loads them?
When you execute a Java program (i.e., by typing java at a command prompt), it executes and launches a native Java launcher. By native, I mean native to your current platform and environment. This native Java launcher contains a classloader called the bootstrap classloader. This bootstrap classloader is native to your environment and is not written in Java. The main function of the bootstrap classloader is to load the core Java classes.The JVM implements two other classloaders by default. The bootstrap classloader loads the extension and application classloaders into memory. Both are written in Java. As mentioned before, the bootstrap classloader loads the core Java classes (for example, classes from the java.util package). The extension classloader loads classes that extend the core Java classes (e.g., classes from the javax packages, or the classes under the ext directory of your runtime). The application classloader loads the classes that make up your application.
bootstrap classloader <-- extension classloader <-- application classloader All three default classloaders follow the delegation model. Before a child classloader tries to locate a class, it delegates that task to a parent. When your application requests a particular class, the application classloader delegates this request to the extension classloader, which in turn delegates it to the bootstrap classloader. If the class that you requested is a Java core class, the bootstrap classloader will make the class available to you. However, if it cannot find the class, the request returns to the extension classloader, and from there to the application classloader itself. The idea is that each classloader first looks up to its parent for a particular class. Only if the parent does not have the class does the child classloader try to look it up itself. In application servers, each separately-deployed web application and EJB gets its own classloader (normally; this is certainly the case in WebLogic). This classloader is derived from the application classloader and is responsible for that particular EJB or web application. (Note that if an application is deployed as an EAR file–a combination of EJB and webapps–it gets one classloader, no more). This new classloader loads all classes that the webapp or EJB require that are not already part the Java core classes or the extension packages. It is also responsible for loading and unloading of classes, a feature missing from the default classloaders. This feature helps in hot deploy of applications. When WebLogic starts up, it uses the Java-supplied application classloader to load the classes that make up its runtime. It then launches individual classloaders, derived from the Java application classloader, which load the classes for individual applications. The individual classloaders are invisible to the classloaders of the other applications; hence, classes loaded for one particular application will not be seen by another application. What if you want to make a single class available to all applications? Load it in a top-level classloader. This could be in the classpath of WebLogic. When WebLogic starts, it will automatically load this class in memory using the Java-supplied application classloader. All sub-application classloaders get access to it. However, the negatives of this approach are clear too. First, you lose the capability of hot deploy for this particular class in all individual applications. Second, any change in this class means that the server needs to be restarted, as there is no mechanism for a Java application classloader to reload classes. You will need to weigh in the pros and cons before you take this approach. WebLogic Server allows you to deploy newer versions of application modules such as EJBs while the server is running. This process is known as hot-deploy or hot-redeploy and is closely related to classloading.
Java classloaders do not have any standard mechanism to undeploy or unload a set of classes, nor can they load new versions of classes. In order to make updates to classes in a running virtual machine, the classloader that loaded the changed classes must be replaced with a new classloader. When a classloader is replaced, all classes that were loaded from that classloader (or any classloaders that are offspring of that classloader) must be reloaded. Any instances of these classes must be re-instantiated. -
December 22, 2005 at 6:01 am #3198091
The beauty of Log4J
by narendrn · about 18 years, 4 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
It took me sometime to appreciate the inheritance heirarchy in Log4J. It’s quite simple to understand the Log Levels and their usage.It is because of this heirarchy that we can have any arbitraty level of granularity in logging. For e.g. suppose we have 10 components in a distributed environment and we want to shutdown the logging of one component. This can be easily done in Log4J using config files. We can also disable logging at a class level – provided we have a Logger for that class – using the Logger.getLogger(this.class) method. Another example is if U want to switch off logging of one or more modules in a application.
We can even make dymanic changes in the configuration file at runtime and these changes would get reflected provided we have used the configureAndWatch() method.
-
December 23, 2005 at 9:58 am #3196353
Hierarchical databases Vs Relational Databases
by narendrn · about 18 years, 3 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
While designing a systems, I often came across the moot point of choosing btw a heirarchical database and a relational flat table database. There are some domain problems, where heirarchical databases such as LDAP and MS Directory Services make sense over RDBs.
The hierarchical database model existed before the far more familiar relational model in early mainframe days. Hierarchical databases were blown away by relational versions because it was difficult to model a many-to-many relationship – the very basis of the hierarchical model is that each child element has only one parent element.
In his article, Scott Ambler makes the following statement:
Hierarchical databases fell out of favor with the advent of relational databases due to their lack of flexibility because it wouldn?t easily support data access outside the original design of the data
structure. For example, in the customer-order schema you could only access an order through a customer, you couldn?t easily find all the orders that included the sale of a widget because the schema isn?t designed to all that.I found an article on the microsoft site which discusses the areas where directory services can be used in place of Relational databases.
Some good candidates for heirarchical databases are- White pages” information, User credential & security group information, Network configuration and service policies, Application deployment policies etc.
-
December 23, 2005 at 3:44 pm #3081480
Hierarchical databases Vs Relational Databases
by sbailey · about 18 years, 3 months ago
In reply to Hierarchical databases Vs Relational Databases
Nice post. I agree that network identity data (credentials, policies, location/reachability maps) are often well suited to hierarchical modeling due to clear requirements for distinction (namespaces) and containment (groups). It’s often appropriate to separate modeling from implementation. Directories often conflate this two aspects inappropriately. I go into this in a little detail in a recent blog entry.
– Stu
-
December 27, 2005 at 10:53 am #3082989
Hierarchical databases Vs Relational Databases
by mleach · about 18 years, 3 months ago
In reply to Hierarchical databases Vs Relational Databases
The mainframe hierarchical databases were actually just file systems with nested directories. Todays LDAP and object-oriented databases do in fact support many-to-many relationships, but require globally unique primary keys to do so.
The impedence mismatch of relational databases and object-oriented programming languages is revitalizing the concept of nested relational database (a hierarchical schema) to mirror todays development environments.
-
December 27, 2005 at 4:07 pm #3082858
Hierarchical databases Vs Relational Databases
by jaqui · about 18 years, 3 months ago
In reply to Hierarchical databases Vs Relational Databases
The “Historical” Hierarchical database is closer to themagnetic tape filesystem than to the current relational databases.
The relational databases and Structured query Language were developed
to make databases more usefull, once a random access media was
available. The original media used for data storage was the anciant
magnetic tape, where you could only work your way along the tape
checking each entry to see if it’s the one you need.The advent of hard drives, where you could access any record on the
drive by name, no need to scan all entries prior to it, inspired the
relational database model. This is actually a case of hardware
improving the productivity of software. -
December 28, 2005 at 10:06 am #3083314
Hierarchical databases Vs Relational Databases
by dc guy · about 18 years, 3 months ago
In reply to Hierarchical databases Vs Relational Databases
The distinction among the various database architectures is becoming moot as processing speeds approach Starburst. Datastores are physically laid out in patterns that facilitate maintenance, backup/recovery, integrity, currency, security, corporate turf, tradition, etc. Meanwhile the programs that read and write the data presume a relational pattern. It’s the heroic middleware that tirelessly converts the relational operators into the appropriate physical commands and presents the results back to the user in the desired format.
Look at what you can do with OS/X Tiger. Type in a keyword and it will search the entire hard drive, paying no attention to architecture. If the keyword is embedded in a file or directory name, if it’s part of the text of an e-mail or other document, if it’s in the cell of a spreadsheet, or if it’s in any other datastore in ASCII format, it will find it and tell you where it found it. And give you the entire list within a couple of seconds.
The next generation of processors will do the same thing on the scale of a corporate network in about the same time. And the nice folks who build Google and the other search engines want us to be able to do the same thing across the entire internet.
Relational, schmelational!
-
-
December 23, 2005 at 9:58 am #3196352
Select second highest record with a query
by narendrn · about 18 years, 3 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A friend of mine was asked in an interview to write a query to fetch the second highest marks in a table of students.Well, I found out 2 ways to do this:
1) Using TOP to get the topmost 2 rows from the table in descending order and then again getting a TOP of the resultset.
SELECT TOP 1 *
FROM(SELECT TOP 2 *
FROM Table1
ORDER BY Marks desc)
ORDER BY Marks;
2) Using the MAX function. (I was suprised to see this work)SELECT Max(Marks) FROM Table1
WHERE Marks Not In (SELECT MAX(Marks) FROM Table1); -
December 26, 2005 at 9:46 am #3082362
Debug information in Java .class files
by narendrn · about 18 years, 3 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have often wanted to learn more about the class file format of Java class files. This study let me to interesting discoveries – regarding what debug information is stored in class files and how it is stored.When we compile a Java source using the ‘javac’ exe, the generated class file by default contains some debug info – By default, only the line number and source file information is generated.
Hence when a stack trace is printed on the screen, we can see the source file name and the line number also printed on the screen. Also, when using log4J, I remember using a layout which can print the line number of each log statement – I bet log4J uses the debug infomation present in the class file to do this.The javac exe also has a ‘-g’ option – This option generates all debugging information, including local variables. To understand this better, I compiled a java source twice; once with the -g option and once without. I then decompiled both the class files to see how the decompiled output differs. The class file compiled with the debug option, showed all the local variable names same as in the original Java file, whereas the one without the debug option, had the local variables named by the decompiler as the local variable information was not stored in the class file.
Another interesting fact is that the class file can contain certain attributes that are non-standard; i.e. vendor specific. Suprised !!!…So was I..Please find below a snippet from the VM spec :
Compilers for Java source code are permitted to define and emit class files containing new attributes in the attributes tables of class file structures. Java Virtual Machine implementations are permitted to recognize and use new attributes found in the attributes tables of class file structures. However, all attributes not defined as part of this Java Virtual Machine specification must not affect the semantics of class or interface types. Java Virtual Machine implementations are required to silently ignore attributes they do not recognize.
For instance, defining a new attribute to support vendor-specific debugging is permitted. Because Java Virtual Machine implementations are required to ignore attributes they do not recognize, class files intended for that particular Java Virtual Machine implementation will be usable by other implementations even if those implementations cannot make use of the additional debugging information that the class files contain
-
December 29, 2005 at 5:46 am #3083589
About Daemon Threads in Java
by narendrn · about 18 years, 3 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Came across this cool article about Daemon Threads at http://www.absolutejava.com/main-articles/beware-the-daemons/I knew that the VM does not exit as long as there is one non-daemon thread running. But there were a couple of new things I learned. Some snippets from the above article:
There are two ways a thread can become a daemon thread (or a user thread, for that matter) without putting your soul at risk. First, you can explicitly specify a thread to be a daemon thread by calling
setDaemon(true)
on a
Thread
object. Note that the setDaemon() method must be called before the thread’s
start()
method is invoked.Once a thread has started executing (i.e., its start() method has been called) its daemon status cannot be changed.
The second technique for creating a daemon thread is based on an often overlooked feature of Java’s threading behavior: If a thread creates a new thread and does not call setDaemon() to explicitlly set the new thread’s “daemon status”, the new thread inherits the “daemon-status” of the thread that created it. In other words, unless setDaemon(false) is called, all threads created by daemon threads will be daemon threads; similarly, unless setDaemon(true) is called, all threads created by user threads will be user threads. -
January 17, 2006 at 9:41 am #3097393
On Screen Scraping
by narendrn · about 18 years, 3 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently I came across the term “Screen Scraping” when interfacing with a legacy application. I was not really sure what it mean in the context of EAI.. A google search came up with a good explanation at http://en.wikipedia.org/wiki/Screen_scrapingAs a concrete example of a classic screen scraper, consider a hypothetical legacy system dating from the 1960s — the dawn of computerized data processing. Computer to user interfaces from that era were often simply text-based dumb terminals which were not much more than virtual teleprinters. (Such systems are still in use today, for various reasons.) The desire to interface such a system to more modern systems is common. An elegant solution will often require things no longer available, such as source code, system documentation, APIs, and/or programmers with experience in a 45 year old computer system. In such cases, the only feasible solution may be to write a screen scraper which “pretends” to be a user at a terminal. The screen scraper might connect to the legacy system via Telnet, emulator the keystrokes needed to navigate the old user interface, process the resulting display output, extract the desired data, and pass it on to the modern system.
-
January 17, 2006 at 1:11 pm #3097216
On Screen Scraping
by wayne m. · about 18 years, 3 months ago
In reply to On Screen Scraping
Actually, screen scraping is more common with more complex user interfaces based on things like IBM-style 3270 displays which did many things similar to HTML. The issue is typically not a technology issue, but usually a funding and responsibility issue.
Screen scraping is usually chosen not because of lack of technical ability or knowledge to implement a more convenient interface, but because of political issues. Screen scraping allows a group who wishes automated access to the data on another system to pull the data without requiring programming changes on the taret system. In most projects, direct funding for interfaces is only provided to one of the systems involved. The other system must essentially develop its side for free (out of its O&M budget). Screen scraping shifts almost all of the develop cost to the user of the data with minimal consulting assistance from the provider.
-
-
January 25, 2006 at 7:49 am #3257537
Message Driven Beans Vs Stand-alone JMS clients
by narendrn · about 18 years, 2 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In many design scenarios, asynchronous messaging is required- for integration purposes, for handling large volume of requests etc.
In the J2EE scenario, we often have to decide whether to write a simple JMS client or go for a MDB in a EJB container. Though, a simple JMS client is neat and easy to write, it has some disadvantages:
JMS has no built-in mechanism to handle more than one incoming request at a time. To support concurrent requests, you will need to extend the JMS client to spawn multiple threads, or launch multiple JVM instances, each running the application.On the downside, we have issues of security, transaction handling, and scalability.The main advantage that MDBs have over simple JMS message consumers is that the EJB container can instantiate multiple MDB instances to handle multiple messages simultaneously.
A message-driven bean (MDB) acts as a JMS message listener. MDBs are different from session beans and entity beans because they have no remote, remote home, local, or local home interfaces. They are similar to other bean types in that they have a bean implementation, they are defined in the ejb-jar.xml file, and they can take advantage of EJB features such as transactions, security, and lifecycle management.As a full-fledged JMS client, MDBs can both send and receive messages asynchronously via a MOM server. As an enterprise bean, MDBs are managed by the container and declaratively configured by an EJB deployment descriptor.
For instance, a JMS client could send a message to an MDB (which is constantly online awaiting incoming messages), which in turn could access a session bean or a handful of entity beans. In this way, MDBs can be used as a sort of an asynchronous wrapper, providing access to business processes that could previously be accessed only via a synchronous RMI/IIOP call.
Because they are specifically designed as message consumers and yet are still managed by the EJB container, MDBs offer a tremendous advantage in terms of scalability. Because message beans are stateless and managed by the container, they can both send and receive messages concurrently (the container simply grabs another bean out of the pool). This, combined with the inherent scalability of EJB application servers, produces a very robust and scalable enterprise messaging solution.They cannot be invoked in any manner other than via a JMS message. This means that they are ideally suited as message consumers, but not necessarily as message producers. Message-driven beans can certainly send messages, but only after first being invoked by an incoming request. Also, MDBs are currently designed to map to only a single JMS destination. They listen for messages on that destination only.
When a message-driven bean’s transaction attribute is set to Required, then the message delivery from the JMS destination to the message-driven bean is part of the subsequent transactional work undertaken by the bean. By having the message-driven bean be part of a transaction, you ensure that message delivery takes place. If the subsequent transactional work that the message-driven bean starts does not go to completion, then, when the container rolls back that transactional work it also puts the message back in its destination so that it can be picked up later by another message-driven bean instance.
-
January 26, 2006 at 11:52 pm #3258427
What are XA transactions? What is a XA datasource?
by narendrn · about 18 years, 2 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Came across this wonderful explanation by Mike regarding XA transactions hereExcerpt:
An XA transaction, in the most general terms, is a “global transaction” that may span multiple resources. A non-XA transaction always involves just one resource. An XA transaction involves a coordinating transaction manager, with one or more databases (or other resources, like JMS) all involved in a single global transaction. Non-XA transactions have no transaction coordinator, and a single resource is doing all its transaction work itself (this is sometimes called local transactions).XA transactions come from the X/Open group specification on distributed, global transactions. JTA includes the X/Open XA spec, in modified form. Most stuff in the world is non-XA – a Servlet or EJB or plain old JDBC in a Java application talking to a single database. XA gets involved when you want to work with multiple resources – 2 or more databases, a database and a JMS connection, all of those plus maybe a JCA resource – all in a single transaction. In this scenario, you’ll have an app server like Websphere or Weblogic or JBoss acting as the Transaction Manager, and your various resources (Oracle, Sybase, IBM MQ JMS, SAP, whatever) acting as transaction resources. Your code can then update/delete/publish/whatever across the many resources. When you say “commit”, the results are commited across all of the resources. When you say “rollback”, _everything_ is rolled back across all resources.
The Transaction Manager coordinates all of this through a protocol called Two Phase Commit (2PC). This protocol also has to be supported by the individual resources. In terms of datasources, an XA datasource is a data source that can participate in an XA global transaction. A non-XA datasource generally can’t participate in a global transaction (sort of – some people implement what’s called a “last participant” optimization that can let you do this for exactly one non-XA item).
-
January 26, 2006 at 11:52 pm #3258428
How to gaurantee “Once-and-only-once” delivery in JMS
by narendrn · about 18 years, 2 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In one application scenario, it was required to process the message only once. The message contained a donation amount that needed to be put in the database. Using a Queue and AUTO_ACK semantics, we were able to achieve this. But there was a problem – What would happen if the JMS provider fails before the acknowledgement is received from client. It would send the message again when it comes up. How to avoid this ?The consumer may receive the message again, because when delivery is guaranteed, it’s better to risk delivering a message twice than to risk losing it entirely. A redelivered message will have the JMSRedelivered flag set. A client application can check this flag by calling the getJMSRedelivered() method on the Message object. Only the most recent message received is subject to this ambiguity.
-
January 27, 2006 at 3:51 am #3258376
Java Service Wrapper
by narendrn · about 18 years, 2 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Came across this tool that can be used to run Java apps as a Windows Service or Unix deamon.
Includes fault correction software to automatically restart crashed or frozen JVMs. Critical when app is needed 24×7. Built for flexibility.The following links provide more info:
http://sourceforge.net/projects/wrapper/ http://wrapper.tanukisoftware.org/doc/english/introduction.html-
February 2, 2006 at 6:22 pm #3107921
Java Service Wrapper
by sjtech · about 18 years, 2 months ago
In reply to Java Service Wrapper
I was looking for such software in December and happened to find
Wrapper on Sourceforge. I installed and tested on my laptop and it
works very nicely. Easy to setup and run. Also nice for Tomcat
and their web site explains how to.
-
-
January 27, 2006 at 3:51 am #3258375
Implementing Req/Res paradigm using JMS
by narendrn · about 18 years, 2 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Quite often in messaging applications, we need to simulate a simple request-response paradigm using JMS. This can be achieved using temporary queues.If you create a temporary destination and specify it as the value of the JMSReplyTo message header field when you send a message, the consumer of the message can use the value of the JMSReplyTo field as the destination to which it sends a reply and can also reference the original request by setting the JMSCorrelationID header field of the reply message to the value of the JMSMessageID header field of the request.
An important point is that the temporary queue is only valid till the connection object is open.
-
January 27, 2006 at 7:52 am #3258214
Having both HTTP and HTTPS in a web-application
by narendrn · about 18 years, 2 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Web applications often need to have both http and https access; i.e. some URIs in the web application need to have HTTPS access and some can do with HTTP.Hard-coding the URL address with https whereever required is not an elegant solution as this has to be reflected in all the links in all pages. An alternative soln will be to do a Response.redirect from the page with https in the URL. More detailed info is available at :
http://www.javaworld.com/javaworld/jw-02-2002/jw-0215-ssl.htmlAlso Struts has a extension through which we can specify which URLs need HTTPS access. For more info check out:
http://struts.apache.org/struts-taglib/ssl.html
http://sslext.sourceforge.net/ -
January 30, 2006 at 7:49 am #3108281
ATMI vs Corba OTS
by narendrn · about 18 years, 2 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently while working on BEA Tuxedo server, I came across the term ‘ATMI’ – Application to Transaction Monitor Interface. I beleive Tux was quite a popular product for handling large number of transactions in a distributed environment – right from the early days when most business critical applications were written in Cobol.
ATMI is a procedural, non object oriented API that you use to write stateless services to manage transactions. This API is developed by the OpenGroup and forms the core service API of Tuxedo. The Application-Transaction Monitor Interface (ATMI) provides the interface between the COBOL application and the transaction processing system. This interface is known as ATMI and these pages specify its COBOL language binding. It provides routines to open and close resources, manage transactions, manage record types, and invoke request/response and conversational service calls.But I believe today’s TP monitors are based on Corba OTS (Object Transaction service) semantics. Corba OTS is used by any OO application as the underlying semantics for communications with resouce managers in a distributed transaction. Even JTS is the Java langauge mapping of Corba OTS. A JTS transaction manager implements the Java mappings of the CORBA OTS 1.1 specification, specifically, the Java packages org.omg.CosTransactions and org.omg.CosTSPortability. A JTS transaction manager can propagate transaction contexts to another JTS transaction manager via IIOP.
-
January 31, 2006 at 3:52 am #3108795
Tibco RV vs Tibco EMS
by narendrn · about 18 years, 2 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A lot of people are familiar with the Tibco RV (Rendezvous) product. This product is around 20 years old and powers many mission critical systems across different domains. Tibco has another product called Tibco EMS (Enterprise messaging Server) which is based on the JMS hub-and-spoke model and is quite popular in EAI. So what’s the difference btw the two products? – When to use what ?First we need to understand the differences in the architecture between the two products. Tibco RV is based on the multicast publish/subscribe model, where as Tibco EMS is based on the hub-and-spoke model.
Multicast is the delivery of information to a group of destinations simultaneously using the most efficient strategy to deliver the messages over each link of the network only once and only create copies when the links to the destinations split. By comparison with multicast, conventional point-to-single-point delivery is called unicast. When unicast is used to deliver to several recipients, a copy of the data is sent from the sender to each recipient, resulting in inefficient and badly scalable duplication at the sending side.
Googled out a white paper that contained some good architecture details about Tibco RV. The link is here.
Excerpt from the article:
TIB/RV is based on a distributed architecture . An installation of TIB/RV resides on each host on the network.Hence it eliminates the bottlenecks and single points offailures could be handled. It allows programs to sendmessages in a reliable, certified and transactional manner,depending on the requirements. Messaging can be delivered in point-to-point or publish/subscribe, synchronously orasynchronously, locally delivered or sent via WAN or theInternet. Rendezvous messages are self-describing and platform independent.
RVD (Rendezvous Daemon) is a background process that sits in between the RVprogram and the network. It is responsible for the deliveryand the acquisition of messages, either in point-to-point or publish/subscribe message domain. It is the most important component of the whole TIB/RV.Theoretically, there is an installation of RVD on every host on the network. However, it is possible to connect to a remote daemon, which sacrifices performance and transparencies. The RV Sender program passes the message and destination topic to RVD. RVD then broadcasts this message using User Data Packet(UDP) to the entire network. All subscribing computers with RVDs on the network will receive this message. RVD will filter the messages which non-subscribers will not be notified of the message. Therefore only subscriber programs to the particular topic will get the messages.
So when to use Tibco RV and when to use Tibco EMS (or any other hub-and-spoke model). An article at http://eaiblueprint.com/3.0/?p=17 describes the trade-offs between the two models:Excerpt:
In my opinion, the multicast-based publish/subscribe messaging is an excellent solution for near-real-time message dissemination when 1 to ‘very-many’ delivery capabilities matter. RV originated on the trading floors as a vehicle for disseminating financial information such as stock prices.
However, in most EAI cases the opposite requirements are true:
?Cardinality? of message delivery is 1-1, 1-2; 1 to-very-many is a rare case. With exception of ?consolidated application? integration model (near real time request reply with timeout heuristics), reliability of message delivery takes priority over performance. Effectively, in most EAI implementations of RV, RV ends up simulating a queueing system using its ?Certified Delivery? mechanism. While this works, it is a flawed solution (see the discussion of Certified Messaging below).
Reliable delivery is a ?native? function of hub-and-spoke solutions. The multicast solution must be augmented with local persistence mechanism and re-try mechanism.
While RV offers reliable delivery (queueing) referred to as Certified Messaging, this solution is flawed in that: Inherently, reliability of CM is not comparable to the hub-and-spoke topologies as the data is stored in local file systems using non-transactional disk operations, as opposed to centralized database in hub-and-spoke topology. Corruption of RV ?ledger files? is not a rare case that leads to loss of data.
Temporal de-coupling is not the case. While a message can be queue for a later delivery (in case the target system is unavailable), for a message to be actually delivered both system must be up at the same time.
RV / CM lacks a basic facility of any queueing system: a queue browser that is frequently required for production support (for example, in order to remove an offending message). In contrast, MQ Series offers an out-of the box queue browser and a host of third party solutions. Transactional messaging is difficult to implement in multicast environment. TIBCO offers a transactional augmentation of RV (RVTX) that guarantees a 1-and-onlu-once delivery; however, this solution essentially converts RV into a hub-and-spoke system. Consequently, very few RV implementations are transactional.
Having said that, the shortcomings of hub and spoke include:
- Single point of failure, when the hub is down, everything is down. MQ Series addresses this problem by providing high-reliability clustering.
- Non-native publish/subscriber (publish/subscribe is emulated programmatically ) that results in reduced performance, especially in 1-to-very many delivery
- Overhead of hub management (a need for administering hub objects: queues, channels, etc).
- Inferior performance, especially in 1 to-many publish/subscribe and request/reply cases.
These shortcomings ? in my opinion ? do not outweigh benefits and for that reason MQ Series / hub-and-spoke solutions constitute a better choice for most EAI problem. Multicast-based publish subscribe is better left to its niches (high volume, high performance, accepter unreliability, 1 to very many).
-
February 23, 2006 at 11:26 pm #3102347
Citrix Server and Terminal Services
by narendrn · about 18 years, 1 month ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I was quite familiar with Terminal Services in Windows and also the Remote Desktop Protocol used in it. But recently I came across a technology called ‘Citrix’ that was similar in nature, so I decided to dig into the root of it. This is the info I found on the net:Citrix Presentation ServerSoftware from Citrix that provides a timeshared, multiuser environment for Unix and Windows servers. Formerly MetaFrame, Citrix Presentation Server uses the ICA protocol to turn the client machine into a terminal and governs the input/output between the client and server. Applications can also be run from a Web browser
Citrix Presentation Server (formerly Citrix MetaFrame) is a remote access/application publishing product built on the Independent Computing Architecture (ICA), Citrix Systems’ thin client protocol. The Microsoft Remote Desktop Protocol, part of Microsoft’s Terminal Services, is based on Citrix technology and was licensed from Citrix in 1997. Unlike traditional framebuffered protocols like VNC, ICA transmits high-level window display information, much like the X11 protocol, as opposed to purely graphical information.Independent Computing Architecture (ICA) is a proprietary protocol for an application server system, designed by Citrix Systems. The protocol lays down a specification for passing data between server and clients, but is not bound to any one platform.
Practical products conforming to ICA are Citrix’s WinFrame and MetaFrame products. These permit ordinary Windows applications to be run on a suitable Windows server, and for any supported client to gain access to those applications. The client platforms need not run Windows, there are clients for Mac and Unix for example. -
February 28, 2006 at 1:52 am #3272560
What is a DMZ?
by narendrn · about 18 years, 1 month ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
DMZ stands for demilitarized zone. DMZ is also known as perimeter network and is used for security purposes. A DMZ is that part of the network/subnet that sits between the organisations LAN and the Internet. The concept behind creating a DMZ is that m/c’s from the Internet and the org’s LAN can connect to DMZ, but the DMZ can only connect to the external network – i.e. the Internet.
This allows m/c’s hosted in the DMZ to interact with the external network for services such as Email, Web and DNS. So even if a host in the DMZ is compromised, the internal network is still safe. Connections from the external network to the DMZ are usually controlled using port address translation (PAT).A DMZ can be created by connecting each network to different ports of a single firewall (3-legged-firewall) or by having 2 firewalls and the area btw them as a DMZ.
In case of Enterprise Applications (3-layered), the webserver is placed in the DMZ. This protects the applications business logic and database from intruder attacks.
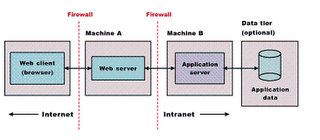
-
February 28, 2006 at 1:52 am #3272561
Why put a webserver in front of an application server?
by narendrn · about 18 years, 1 month ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A lot of my developer friends pop up the question of why to use a webserver when today’s application servers such as Weblogic, Websphere, Tomcat, JBoss etc. also have a HTTP listener. But in almost every architecture, we will see Apache in front of Tomcat, or IBM Http Server in front of WAS. The question is why?…and the answers are as follows:
- Webservers serve static content faster than application servers. Hence for performace reasons, it makes sense to shift all the static contect to the webserver. (J2EE developers hate this, as they now have to split the *.war files)
- The webserver can be put in a DMZ to enable enhanced security.
- The webserver can be used as a load balancer over multiple application server instances.
- The webserver can have agents/plug-in’s to security servers such as Netegrity. Hence security is taken care by the webserver, putting less load on the application server.
-
February 28, 2006 at 4:58 am #3088147
Why put a webserver in front of an application server?
by jaqui · about 18 years, 1 month ago
In reply to Why put a webserver in front of an application server?
Apache isn’t just a webserver though.
it’s a file server, a network server [ strong extranet module ] and even an APPLICATION server in itself.heck, apache even has a kitchen sink:
Name: apache-mod_kitchensink
Version: 2.0.54_1.1-2
Size: 51 KBSummary: Mod_KitchenSink is a DSO module for the apache web server
Description: Mod_KitchenSink was inspired by a discussion around Mozilla bug #122411. To make a story short, if people ever say “ADVX.org is too bloated with useless features, it has everything but the kitchen sink”, they just have been proved wrong.
With this module, ADVX *has* a kitchen sink. Just install this package, and point your browser to http://localhost/kitchensink.
-
March 2, 2006 at 5:59 am #3087746
Why put a webserver in front of an application server?
by barddzen · about 18 years, 1 month ago
In reply to Why put a webserver in front of an application server?
I have asked the same questions, but the answers you mentioned can be solved in other ways besides plopping Apache in front of your app server. For example, many of the proxy systems today such as Netegrity and Net Scaler also come with a customized and locked down web server already, so hooking your Apache into a system like that only adds yet another web server to the equation.
The other issue with another web server on top of app server is products like Netegrity means the app servers have to assume the user has already been authenticated and looks for elements in the http header, so anyone passing these values directly to the app server can simply bypass the proxy and get to everything anyway, so how does this add to security?
How is having static content, images, and flat HTML in a DMZ more secure? In fact, who gives a crap if someone has access to that content anyway? Anyone who knows how to right-click, view source can get to it and there are a bunch of tools that can suck entire web sites: The point being, securing flat and static HTML is this really that big of a security concern for most of us? Maybe in some instances, but the vast majority of sites? I don’t think so. I’d rather concentrate on securing everything the app serve does and secure that layer more since it deals with compiled code, data connections, etc.
Splitting .war files is just a headache in and of itself and I see no point in doing that. Depending on the middle hardware/proxy you get, most devices now a days can be setup to cache common requested static content out of the box so complicating your deployment process just for the sake of doing it isn’t even worth the effort in my mind. Let the tools do their job.
Just my 50 cents…
-
February 28, 2006 at 5:53 am #3088126
MySQL – import and export of database
by narendrn · about 18 years, 1 month ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently I had to move my MySQL server from a WinXP machine to a Win2000 server machine. I thought that the data migration of the MySQl database would be a pain.
To my suprise, it just took me 5 mins flat to do it. Here are the steps:
1)First export the database into a flat file. This exports not just the schema but also the “insert” statements for all the data in the tables
mysqldump -u DBUSER -p DBNAME > DBNAME.sql
substituting DBUSER with your MySQL username and DBNAME with your database name.
2) Create a new empty schema/database on your new machine. The name of the database will probably be same as the name in the old server.
3) Import the dump file into the new database server.
mysql -u DBUSER -p -h MACHINE-NAME DBNAME<>
substituting DBUSER with your MySQL username and DBNAME with your database name, and MACHINE-NAME with the name of the SQLServer instance – quite often the name of the machine itself.That’s it…migration of database done.
-
March 1, 2006 at 9:56 am #3088264
What is virtual hosting?
by narendrn · about 18 years, 1 month ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Virtual hosting is essentially “shared web hosting”. Virtual hosting is a method that webservers use to host more than one domain name on the same host. It is generally the most economical option for hosting as many people share the overall cost of server maintenance.There are two basic methods of accomplishing virtual hosting:
name-based, and IP address or ip-based.In name-based virtual hosting, also called shared IP hosting, the virtual hosts serve multiple host names on a single machine with a single IP address.
With web browsers that support HTTP/1.1 (as almost all do today), upon connecting to a webserver, the browser sends the URL to the server. The server can use this information to determine which web site to show the user. So each website would have a DNS entry and all the DNS entries for the websites point to the same IP address.In IP-based virtual hosting, also called dedicated IP hosting, each webserver has a different IP address. The webserver is configured with multiple physical network interfaces, or virtual network interfaces on the same physical interface. The webserver uses the IP address from the HTTP request to determine which web site to show the user.
Disadvantages of virtual hosting:
Older web browsers that only support HTTP/1.0 will not work because they do not send the URL.
If the Domain Name System (DNS) is not properly functioning, it becomes much harder to access a virtually-hosted website.
They do not support secure websites (HTTPS), at least not on the same TCP port. All virtual hosts on a single HTTPS webserver must share the same digital certificate. Because the SSL handshake takes place before the expected hostname is sent to the server, the server doesn’t know which encryption key to use when the connection is made. -
March 2, 2006 at 6:23 am #3087727
Free Portal frameworks out there
by narendrn · about 18 years, 1 month ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently I was trying to evaluate some open-source portals that I can use for my personal use.
Here is the list of interesting portals I found out:http://www.exoplatform.com/
http://www.liferay.com/
http://portals.apache.org/
http://jboss.com/products/jbossportal
http://www.gridsphere.org/Out of the above I found Apache Jetspeed 2.0 and Liferay to be promising…I had a bad experience with JBoss Portal…it sucks !!!
-
March 3, 2006 at 3:52 am #3090053
HSQL – A cool Java database..
by narendrn · about 18 years, 1 month ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently I developed a portal which made use of MySQL database. The database was small in size and had only a few tables. But I was facing problems, when the web-application had to be installed in different locations. I had to give instructions to users on how to create the MySQL database, run the script to add all the necessary tables etc.Then I came across HSQL (Hypersonic SQL) database. This is a 100% pure Java database and can be run in-process inside a Java application…even a webapplication. No need to install anything or start any database process. More information about HSQL can be found at http://www.hsqldb.org/
For me, just the following 2 lines of code, created a database in my Tomcat webapps directory.
Class.forName(“org.hsqldb.jdbcDriver”);
Connection c = DriverManager.getConnection(“jdbc:hsqldb:file:webapps/myPortal/database/narenDB”, “sa”, “”);So simple………:)
-
March 9, 2006 at 1:48 am #3086314
HSQL – A cool Java database..
by franktp · about 18 years, 1 month ago
In reply to HSQL – A cool Java database..
Did you hear about IBM Cloudscape or Apache Derby?
This is an open source ‘basic’ version of the IBM DB2 UDB database which can be run inside your cade as well. All java based. I have no experience with it but maybe you like to try this out as well.
read all about it at: http://www-128.ibm.com/developerworks/db2/library/techarticle/dm-0410prial/
-
March 9, 2006 at 11:59 am #3084147
HSQL – A cool Java database..
by pkolega · about 18 years, 1 month ago
In reply to HSQL – A cool Java database..
HSQL has been around for, well… forever. Yes, it’s amazing little database, very well suited for Java development. As for Derby/Cloudscape being “lite DB/2” — simply not true. Yes – the JDBC drivers you use to connect to them are the same, but underlying technology is very much different. Cloudscape came to IBM when they took over Informix; IBM turned codebase of it (after some cleanup, I’m pretty sure…) to Apache. But I think they still sell and support Cloudscape as a product. BTW: being able to use the same drivers to connect to Cloudscape and DB/2 is a nifty trick – you can use one for development and the other for deployment — “just-change-connection-string”. And yes, I know – it may not be _that_ easy.
Peter W.
-
-
May 22, 2006 at 2:17 pm #3148136
When to do Object Pooling?
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Pooling basically means utilizing your resources better. For example, imagine a fairly large
number of clients utilizing a small number of database or network connections efficiently. By
limiting object access to only the period when the client requires it, you can free resources for
use by other clients. Increasing utilization through pooling usually increases system
performance.You can use pooling to minimize costly initializations. Typical examples include database and
network connections and threads. Such connections often take a significant amount of time to
initialize. You can achieve significant savings by creating these connections once and reusing
them later. Finally, you can pool objects whose initialization is expensive, in terms of time,
memory, or other resources. For example, most containers pool Enterprise JavaBeans to avoid
repeated resource allocation and state initialization.Examples of objects holding external OS resources:
-database connection pooling,
– socket connection pooling (including HTTP, RMI, CORBA, WS, etc…)
– thread pooling,
– bitmaps, fonts, other graphics objects…For objects that do not hold external OS resources, but are time-consuming to initialize and are
memory-heavy, a cost benefit analysis needs to be done. What is the cost of pooling
(synchronization, management, GC etc.) vs the benefit (quick access to connection or socket).One very important concern during pooling is the problem of concurrency bottlenecks….when we snchronize access to the pooled resources.Simple object pooling (which hold no external resources, but only occupy memory) could be a
waste, as the performance improvments in the latest versions of the JVM have tilted this
equation, so we better re-evaluate what we think we know……..There was also an old school of thought that pooling reduces the need of GC and hence improves the performance. But with the introduction of the concept of ‘generations’ to GC algorithms, it is possible that pooled resources would be more difficult to GC as they are put in older generations of objects.But for external resources the JVM improvements are of no-concern. Whether objects holding
external resources (out of JVM, either OS resources on JVM host machine, or on the other machine) should be pooled or not, does not depend on JVM efficiency, but on their availability, weight and and other costs of holding these resources.Why stateless session beans pooled ?The EJB spec states that only one thread at the time can execute method code in a statelss session bean instance. So you need to pool them to provide concurrency. The qustion is whether this spec requirement makes sense?
As only reason for this request I can see is that this way you can have local instance state (as
instance fields) in a stateless session bean that is valid during a single method execution. Note
that your method can call other (possibly private) methods of the same bean, so in this scenario
this makes sense.
However, you can get the same behavior by holding a state and logic in a separate POJO and having your session bean playing a facade to that POJO. Probably this request is to simplify programming model for stateless session EJBs, making them completely thread safe .
The EJB standard does not require that Stateless Session EJBs have no internal state (ie.
fields). It simply requires that no conversational state be maintained between the bean and its
clients. A pool of these that are doled out to client threads on a per-call-basis is valuable if
the bean manages some expensive-to-allocate-or-create resource.From the EJB 2.0 Specification, section 7.5.6: “A container serializes calls to each session bean instance. Most containers will support many instances of a session bean executing concurrently; however, each instance sees only a serialized sequence of method calls. Therefore, a session bean does not have to be coded as reentrant.”
Is there some other reason why stateless session beans are pooled?…Something in the
architecture of EJB that forces this decision? -
May 22, 2006 at 2:17 pm #3148137
Retrieval of AutoGenerated Keys
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
We often face the problem of retrieving a ‘auto-generated’ column after a ‘INSERT’ operation. For e.g.insert into myTable (name) values (‘Naren’)”);
Now immediately after the insert, I want to get the ‘auto-generated’ key of the inserted row. The only way to do it earlier in JDBC was to fire another query to get the last inserted row. But this method is fundamentally flawed, as there could be other inserts that have happened in-between.Now, in JDBC 3.0 (in JDK 1.4), we have core JDBC methods that enable us to retrive the autogenerated key automatically. For e.g.
int rowcount = stmt.executeUpdate(“sql here…”,Statement.RETURN_GENERATED_KEYS);
ResultSet rs = stmt.getGeneratedKeys ();
The ability to retrieve auto generated keys provides flexibility to the JDBC programmer and it provides a mechanism to realize performance boosts when accessing data.The following methods are available since JDK 1.4
public int executeUpdate(String sql, int autoGeneratedKeys) throws SQLException
Executes the given SQL statement and signals the driver with the given flag about whether the auto-generated keys produced by this Statement object should be made available for retrieval.
Parameters:
sql – must be an SQL INSERT, UPDATE or DELETE statement or an SQL statement that returns nothing.
autoGeneratedKeys – a flag indicating whether auto-generated keys should be made available for retrieval; one of the following constants: Statement.RETURN_GENERATED_KEYS
Statement.NO_GENERATED_KEYS—————————————
public int executeUpdate(String sql, int[] columnIndexes)
throws SQLExceptionExecutes the given SQL statement and signals the driver that
the auto-generated keys indicated in the given array should be made available for retrieval. The driver will ignore the array if the SQL statement is not an INSERT statement.Parameters:
columnIndexes – an array of column indexes indicating the columns that should be returned from the inserted row
——————————————
public int executeUpdate(String sql, String[] columnNames)
throws SQLExceptionExecutes the given SQL statement and signals the driver that
the auto-generated keys indicated in the given array should be made available for retrieval. The driver will ignore the array if the SQL statement is not an INSERT statement.Parameters:
columnNames – an array of the names of the columns that should be returned from the inserted row
—————————————-
In Spring JDBC API, the JDBCTemplate has a utility method that directly gives the genetated key:
int update(PreparedStatementCreator psc, KeyHolder generatedKeyHolder) -
May 22, 2006 at 2:17 pm #3148138
StringBuffer Myth
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I have noticed that a lot of people are wasting their precious time changing code that contains “+” overloaded String operator toStringBuffer…in the following way :
For eg.
—————–
1 ) String sTemp = “a” + “b” + “c”;is being replaced with
—————
2 )StringBuffer sBuffer = new StringBuffer()
sBuffer.append(“a”);
sBuffer.append(“b”);
sBuffer.append(“c”);
String sTemp = sBuffer.toString();Now the point is for simple string concatenations such as the above the compiler itself does the conversion to StringBuffer. Thus the code in 1) gets converted to code in 2) during compilation time only…….ie conversion to platform independant byte form…
So there is no need for us to do this explictly….But yes, there will be a remarkable advantage when we have String concatenation in a for loop…
for eg, if the above code was within a for loop…..for eg:
for(int i=0;i<n;i++)
{ sTemp = “a” + “b” + “c”;}Then it makes sense to use StringBuffer, otherwise a new String Buffer object will be created for each iteration of the loop. So in such cases we can instantiate the StringBuffer outside the loop and just use “append” inside the loop..
-
May 22, 2006 at 2:17 pm #3148139
Precompiling JSPs in Tomcat
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
For faster startup access to a website, it is sometimes desirable to precompile all the JSP pages on a production server, so that the first users of the website do not have to bear the performance hit of JSP compilation (first to servlet java file and then to class file)Tomcat 5.0 and above comes with a cool ANT script that uses the Jasper JSP compiler to precompile the JSPs in a webapp. The ANT script is available here.
On running the ANT script, the “WEB-INF\classes” directory has a new package “\org\apache\jsp” that contains all the class files of the compiled JSPs. The src folder would contain the generated Java Servlet files.If U edit a JSP page on the fly, then it would again be compiled at run-time and swapped in memory with the old one, but the classes directory would still contain the old class file.
-
May 22, 2006 at 2:17 pm #3148130
Debugging Server-side Java with JPDA
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
JPDA stands for Java Platform Debugger Architecture. It is a new debugging design adopted by the VM that facilitates debuggers to attach to the VM process easily. More info about JPDA can be found here.I tried out debugging a Struts application running on Tomcat using Eclipse. (Versions: Tomcat-5.0; Eclipse-3.1.2)
Here are the steps to be followed:- Start Tomcat in JPDA debug mode. For this, set up two variables in the environment as follows:
- The first variable is: set JPDA_TRANSPORT=dt_socket (This tells the VM that the debugger would talk to the VM on Tcp sockets)
- The second variable is: set JPDA_ADDRESS=8000 (This tells the VM the port on which it should listen for debugger connections)
- Go to the command prompt and run the ‘Catalina.bat’ batch file present in {TomcatHome}\bin. On the command prompt pass the following argument: catalina jdpa start
- Go to Eclipse and open the Debug window. Create a new configuration under ‘Remote Java Application’ . Make sure ‘Connection Type’ is Socket and port is 8000
- Navigate the webapplication thru web browser and see Ur Eclipse stop at breakpoints..
Happy debugging…………
-
May 22, 2006 at 2:17 pm #3148131
Diff btw div and span tags in HTML
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
I was trying to get the hang of AJAX and was learning a lot of JavaScript and HTML. I was confused btw the <div>and <span> tags in HTML. A quick google came up with these answers:The main difference between <div> and <span>is that <div>defaults as a block-level element and <span>defaults as an inline element.
Block-level elements create a new formatting context. They are stacked vertically(acts as a paragraph break) in the order they appear in the source code and may contain any number of other block-level elements or inline elements.
Inline elements do not create a new formatting context. They line up horizontally within their block container in the order they appear in the source code, wrapping to new lines within their block container if necessary and can contain only other inline level elements (or inline text boxes).
Both <div> and <span>are generic elements. Both can be used as many times as you like on a page. They hold no defaults settings besides their value for display (block on <div>, inline on <span>) -
May 22, 2006 at 2:17 pm #3148132
Debugging JavaScript
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
While working with VisualStudio.NET, I was impressed with the ability of VS.NET to even debug JavaScript on a HTML page. It saved a lot of time – or the other alternative was writting alert() statements.I wondered if there was some similar JavaScript Debugger tool for the Java community.
Fortunately, Mozilla has come up with a cool tool that allows developers to debug Javascript code. The tool is “Venkman Debugger” and it’s a free download.Here’s the URL for more details: http://www.mozilla.org/projects/venkman/
For firefox 1.0 (my fav browser), the debugger is available as a plug-in. Installation was a breeze !!!
I just had to download the *.xpi” file and drag and drop the file in a open window of Firefox…that’s it..Then start the debugger from the tools menu…After this, any page U see on Firefox – the debugger windows will show all the Javascript functions and we can set breakpoint and step thru the code…also available is the local window and watch window 🙂
Happy debugging..
-
May 22, 2006 at 2:17 pm #3148133
Unix Quirks for Windows developers
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently came across a wonderful blog stating a few things about Unix/Linux which ever developer should know. The link to the blog is here.
Some useful points in the blog were:- In Unix, if U want Ur application or server to use a port less than 1024, then U must be running as ‘root’. This imposes security risks !!!
- In Unix, it is possible for one process to open a file stream and an another process to delete the same file. (Windows does a automatic file lock). For the same reason, in Unix, U can delete a directory right from under it.
- Equivalent of Windows services in the Unix world are just plain shell scripts that are mentioned in the /etc/init.d directory.
- The Unix shell runs scripts by creating a copy of itself and running the script in the new shell. This new shell will read in the script, perform all the steps in the script (e.g. set all the environment variables) and then exit, leaving the original shell and its environment unchanged. So to run scripts in the same shell, we need to type “. setenv.sh” For c-shell, we need to type “source setenv.sh”
- And last, but not the least, every developer learns early – Unix new line character is \n and on Windows \r\n.
-
May 24, 2006 at 1:29 pm #3147358
Unix Quirks for Windows developers
by hcabral00 · about 17 years, 11 months ago
In reply to Unix Quirks for Windows developers
Better subject line would be “Naive windows developers”.
Every platform has its own design decisions. Anyone trying to
develop for a platform without knowing the basics is going to be in
trouble.To answer your “quirks”:
1) ports below 1024 are special ports reserved to trusted
servers. Remember that Unix machines are multi-user, it’s not
only you who may use the machine. Therefore, you don’t anybody
able to start a trojan horse passing as a web server in port 80.2) Design decision, for better or for worse. You protect against
deletion by using the acess control facilities Unix provides you
as a multi-user system.4) This is so your environment doesn’t get “polluted” by spurious
scripts. You run a script, it gets its own environment, mess it
up at its own will and when it finishes you have your environment as it
was before. Neat, isn’t it?5) Yeah, for some reason windows decided to go for the \r\n. Why? Beats me…
-
May 22, 2006 at 2:17 pm #3148134
Uses of Reverse Proxy
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
We are all aware of proxy servers, that enable us to access the internet from inside a firewall. These proxies are known as forward proxies. Similarly we have reverse proxy that sits in front of a webserver and can provide caching and also redirection.
Recently, we needed to expose a website to the internet. I thought the only way of doing it would be to assign a new IP to the webserver machine and have a DNS setup for it. Alternatively, we can put in one more NIC card and have that IP address exposed to the public.
But Reverse Proxy presents us with an interesting alternative. A reverse proxy can be used to enable controlled access from the Web at large to servers behind a firewall.
Here is a simple example provided at the Apache website (Apache can also be used as a reverse proxy server)Scenario:
Company example.com has a website at http://www.example.com, which has a public IP address and DNS entry can be accessed from anywhere on the Internet.The company also has a couple of application servers which have private IP addresses and unregistered DNS entries, and are inside the firewall. The application servers are visible within the network – including the webserver, as “internal1.example.com” and “internal2.example.com”, But because they have no public DNS entries, anyone looking at internal1.example.com from outside the company network will get a “no such host” error.
A decision is taken to enable Web access to the application servers. But they should not be exposed to the Internet directly, instead they should be integrated with the webserver, so that http://www.example.com/app1/any-path-here is mapped internally to http://internal1.example.com/any-path-here and http://www.example.com/app2/other-path-here is mapped internally to http://internal2.example.com/other-path-here. This is a typical reverse-proxy situation.
————————————————–
In my scenario, my network admin guys were able to put my website on the internet without touching my server even once 🙂For more information on reverse proxy check out the following links:
http://www.apacheweek.com/features/reverseproxies
http://www.informit.com/articles/article.asp?p=169534&rl=1
http://en.wikipedia.org/wiki/Reverse_proxy -
May 22, 2006 at 2:17 pm #3148135
Storing passwords in database
by narendrn · about 17 years, 11 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
This is one of the most common and trivial challenges that developers face in any enterprise application development ? How to store passwords in database in a safe and secure manner?
It?s common sense to reconcile that passwords should not be stored as plain text as it would be possible for anyone to hack the passwords if he has access to the database table.One option is to encrypt the passwords using a symmetric key and decrypting it for comparison during password authentication. But then we have the problem of securely storing the secret symmetric key, because if the key were compromised all the passwords would become accessible.
The most common and simple solution to this problem is to ?hash? the passwords before storing it in database. MD5 or SHA-1 hash algorithms can be used to perform a one-way hash of the password. To compare passwords for authentication, you retrieve the password entered by the user and hash it; then you compare the hashed value with the hashed value in the database. This method is quite foolproof and safe as it?s impossible to convert a hashed entry into its original value.
But still it possible for a hacker to perform a brute-force dictionary attack on the passwords and guess some passwords. More info on this here.To hinder the risk of a dictionary attack, it is important that password contain special characters that are difficult to guess. Another option is to ?salt? the password before hashing it. Salting the password means adding some padding data in front or back of the password to create a new string that is hashed and put inside the database table. This padding data could be a random generated number or the userID of the user itself. This makes the dictionary attack much difficult to succeed.
Recently there was a lot of furor over the security of MD5 algorithm. The problem is that of MD5 hash collisions. The problem that arises is the following:
Since what we did is take the characters in some text, however many they are, and producing 128 characters out of them somehow, there will be lots of texts that give the same set of 128 characters, and hence have the same MD5 value. I.e. the hash-function is not 1-1 as we say. So how do we know that the file we received is not one of those other millions of files that have the same MD5 value? The simple answer is, we don?t. But what we believe is that the chance that this other file will be meaningful is miniscule. In other words, we believe that even if someone were to tamper with our file on its way to us, they would not be able to produce a file that has the same MD5 value and can harm u.
But the site below shows how two different postscript files end up having the same MD5 hash. http://www.cits.rub.de/MD5Collisions/So, what are the other options? Tiger and SHA-2 are still considered to be safe hash functions to use. One could possibly also apply a number of hash-functions to the same file, as secondary checks.
-
June 7, 2006 at 5:06 am #3164257
XMI-XML Metadata Interchange
by narendrn · about 17 years, 10 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently, I started using Rational Software Modeller for UML modelling. The UML diagram files that the tool creates have a *.emx extension. I was expecting it to be some proprietary binary format, but when I opened the file in Notepad, I was suprised to see a XML format!!!. It looks like even IBM has decided to make its UML models XMI compatible.So what exactly is XMI?The XML Metadata Interchange (XMI) is an OMG standard for exchanging metadata information via Extensible Markup Language (XML). It can be used for any metadata whose metamodel can be expressed in Meta-Object Facility (MOF). The most common use of XMI is as an interchange format for UML models, although it can also be used for serialization of models of other languages (metamodels).
Here’s an excerpt from Wikipedia : http://en.wikipedia.org/wiki/XMIXMI can be used to transfer UML diagrams between various modeling tools.At the moment there are severe incompatibilities between different modeling tool vendor implementations of XMI, even between interchange of abstract model data. The usage of Diagram Interchange is almost nonexistent. Unfortunately this means exchanging files between UML modeling tools using XMI is rarely possible.
-
June 8, 2006 at 1:05 am #3143736
Association – Aggregation and Composition
by narendrn · about 17 years, 10 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
An aggregation is a special form of association between classes that represents the concept of “WHOLE -PART”. Each object of one of the classes that belong to the aggregation (the composed class) is composed of objects of the other class of the aggregation (the component class). The composed class is often called “whole” andthe component classes are often called “parts”.A simple aggregation is an aggregation where each part can be part of more than one whole.
Composition is a special kind of aggregation in which the parts are physically linked to the whole. So, a composition defines restrictions with regard the aggregation concept:
– A part can not simultaneously belong to more than one whole.
– Once a part has been created it lives and dies with its whole. -
June 15, 2006 at 5:19 am #3270151
Automatic Language Identification from text.
by narendrn · about 17 years, 10 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In one of my recent projects, there was a business requirement to identify the language of a text document automatically and segregate them.I tried to do some research on the internet and came up with some open-source tools that can help in identifying a language. One such popular tool is “Lingua” – open source and written in Pearl.
Language identification happens by searching for common patterns of that language. Those patterns can be prefixes, suffixes, common words, ngrams or even sequences of words. More information about n-grams can be found here.
Other interesting links on the same subject:
http://staff.science.uva.nl/~jvgemert/mia_page/LangTools.html
http://odur.let.rug.nl/~vannoord/TextCat/Demo/
http://staff.science.uva.nl/~jvgemert/mia_page/demo.html#Lid -
June 16, 2006 at 9:48 am #3268641
OnBlur Javascript recursive loop
by narendrn · about 17 years, 10 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Recently some of the developers in my team were struggling with a javascript issue.
The problem was very simple. There were 2 textfields on the screen – one after the other. Both of which have an OnBlur call to a routine that simply validates that the fields are not left blank.Now when the first field is left blank and a ‘tab’ is pressed, then the javascript goes into a recursive loop !!! The loop is started because we used the focus method in the javascript function: tabbing out of field one fires onblur and sets focus to field two. The function focusses back to field one, “taking focus off field two”, which fires a new onblur, which makes your function put focus back on field two firing onblur for field one. This goes on forever.
The solution to this is very simple – Just keep a global variable that points to the current object being validated and check that inside the function. Here is the script for doing so:
var currentObjectName=”;
function NoBlank(object, label)
{
if (currentObjectName!=” && currentObjectName!= object.name) return;currentObjectName=object.name;
if (object.value == “”)
{
lc_name = label;
alert(lc_name + ” input field cannot be blank!”)
object.focus();
return false;
}currentObjectName=”;
return true;
} -
June 19, 2006 at 3:46 am #3270674
Diff btw MTS and COM+
by narendrn · about 17 years, 10 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
During the good old days of WinNT, MTS used to provide the middle layer for distributed computing using MS technologies. The MTS (Microsoft Transaction Service) environment used to sit in between the client and database and provide distributed transaction services, object pooling, security and other services.With Windows 2000, MTS was upgraded to COM+. While MTS was actually an add-on to Windows NT, COM+ was natively supported by Windows 2000. This simplified the programming model quite a bit. It was often said that MTS + COM = COM+.
Thus MTS/COM+ is the equivalent of EJB in the J2EE world.
In .NET, COM+ components can be written as .NET component services. The “System.EnterpriseServices” namespace provides us with classes that enable us to deploy a .NET component as a COM+ component. Existing COM+ components can be accessed using .NET remoting and COM-Interop.
-
June 19, 2006 at 7:29 am #3270553
Deployment options in Tomcat 5.0
by narendrn · about 17 years, 10 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
Generally developers are used to deploy J2EE applications by dropping the war file or the application folder directly into the webapps directory of Tomcat.But it is possible for the application to be deployed in a separate location also – even on a separate logical drive.
We just have to create a XML fragment file and place it in the following folder:
$CATALINA_HOME/conf/[enginename]/[hostname]/[applicationName].xml
If one opens this folder, then we can see the context XML descriptors of all applications deployed on Tomcat.The files typically contain the docBase attribute that points to the physical location on the hard-disk and the web logical path.
<context path=”/ASGPortal” docbase=”ASGPortal”>
So, if want to deploy the above webapp on a separate path, say d:/myApps/ASGPortal, I copy my webapp folder there and change the docBase attribute in Context. Zimple…… 🙂
Note: This comes really handy when we are using a Source-control tool and the check-in/check-out folders are not under Tomcat.
-
June 22, 2006 at 1:10 am #3269041
Deployment options in Tomcat 5.0
by firefox700101 · about 17 years, 10 months ago
In reply to Deployment options in Tomcat 5.0
I think you can modify the server.xml of Tomcat to add a corresponding context block.
Maybe this is a little easier. Such as:<Context
path=”/shopping”
reloadable=”true”
docBase=”e:\workspace\shopping”
workDir=”e:\workspace\shopping\work”/>
-
June 22, 2006 at 2:45 am #3269021
Deployment options in Tomcat 5.0
by martinfitzg · about 17 years, 10 months ago
In reply to Deployment options in Tomcat 5.0
Comments on this post
Does any one know is it possible to do this with
jboss application server version 4.* ? -
June 22, 2006 at 7:49 am #3268846
Deployment options in Tomcat 5.0
by jim-mn · about 17 years, 10 months ago
In reply to Deployment options in Tomcat 5.0
And if I’m on Linux, so can’t use Windows-style drive mappings, what does the path to the physical location look like? What if it’s not on the same box; maybe on a Samba share?
Jim
-
July 12, 2006 at 2:11 pm #3210939
Deployment options in Tomcat 5.0
by jchapple · about 17 years, 9 months ago
In reply to Deployment options in Tomcat 5.0
To see what the path would look like on a xNIX server:
find the location of where your would like to put your files and issue the command pwd.
In UNIX (and Windows too) you mount remote file stores via NFS (older Windows you just map a drive, newer windows you can map external stores to a directory as well) and the O/S makes it look local to you. So, create a common share, mount it up and path out to it. Although you can share the Tomcat container with all the servers, it will become a pain. It would be best to create one for each server by using the command $hostname in the xNIX path. The reason, temp files, log files, work dirs, etc tend to collide, and itis just easier to separate them out. You still gain a common location to view all the files though, which is better than logging into many servers to see the Tomcat apps.
-
-
June 23, 2006 at 4:44 am #3269411
Struts – Forward Action Vs Direct JSP call
by narendrn · about 17 years, 10 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
A recent developer asked me why should one use ForwardAction, when one can directly give a link to a separate JSP directly.The reason is: When we use ForwardAction, the ActionServlet in Struts intercepts the request and provides appropriate attributes such as Message Resource Bundles and also FormBeans.
If we directly give a reference to a JSP page, then the behavior of the Struts tags may become unpredictable.Another reason when ForwardAction would be necessary is when direct access to JSP files are prevented from direct access by using the “security-constraint” tag in web.xml.
-
June 27, 2006 at 5:05 pm #3110923
DAO access in Struts Action?
by narendrn · about 17 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In quite a few projects in the past, I have directly accessed the DAO methods from the Struts Action classes. This strategy makes a lot of sense when we are only retrieving data from the database and populating beans that would be binded to the JSP page.But there are many who consider including any persistance code or business logic code in the Action classes as ‘sacrilege’. Many prefer having a business service layer (aka business delegate) layer that encapsulates all persistance and business-logic.
But for simple CRUD operations, the service layer just becomes a thin layer around the DAO layer. But nevertheless, there are advantages of adding this business service layer.
- Consolidates the data access layer to all clients. Every method in the DAO need not be present in the ServiceLayer. You see only the methods that we wish to expose to the rest of the world.
- Serves as an attachment point for other services, such as transaction support. For e.g. using Spring.
- Presents a single common interface for other applications to use. For e.g. exposing the business functionality as a WebService.
Another reason this extra layer can be helpful is in a real-life scenario- For e.g. A more complex application there are often other business operations you might want to perform besides just calling you DAO. For example, maybe when an “update” is done you need to call some process that sends out an e-mail or some kind of notification. If you don’t use a Service class you are stuck now between coding this business logic either in your Action class or in the DAO. Neither of those places is really a good place for that kind of logic – hence we provide an extra service class to handle business rules that shouldn’t be in the Action and don’t belong in a DAO. Of course for rapid development, you could possibly skip the Service classes and just use the DAOs directly within your Action.
But there is no absolute right or wrong answer. This reminds me of a quote:
“I’m always wary of absolutes. Know the rules, know the reasons behind the rules, know when and why to break the rules, proceed accordingly.”
-
June 28, 2006 at 8:40 am #3111985
DAO access in Struts Action?
by munish k gupta · about 17 years, 9 months ago
In reply to DAO access in Struts Action?
Accessing DAO directly from the Action classes usally make sense for read only kind of data. Infact, Fast Lane Reader Pattern advocates the same thing.
Any data which potentially might have business logic or might participate in transactions should not be directly accessed from the Action class.~munish
Tech Spot -
July 6, 2006 at 12:59 am #3168317
DAO access in Struts Action?
by zaidatheer · about 17 years, 9 months ago
In reply to DAO access in Struts Action?
Bypassing the Business Delegate layer (Business service layer) can save some time, HOWEVER, adding a small chunk of business logic might enforce you to RE-design the project architecture and include the business logic service layer. Even the simple CRUD operations require some business logic sometimes, I will state 2 simple examples:
1. Editing & updating user email : In this case we need to make sure that the submitted email has not been used by other user but it might be already assigned to the same user, in that case we need a business process to validate this condition, then we can throw EmailHasBeenUsedException from the Business layer to the struts action.
2. Deleting an Item which has spareparts children (parent-child relationship): this is a delete operation, and we need to make sure that the deleted item has no children dependant on it, in that case the Business logic layer can fit in this simple daily-used requirement.
Conculsion: Adding a business service layer is, in my opinion, a very good practice. Using the Refractor menu (which is available in most of the IDEs such Eclipse and NetBeans) can simplify the process of adding this layer.
Regards,
Zaid Omar
-
June 28, 2006 at 8:17 am #3110692
Spring Vs EJB
by narendrn · about 17 years, 9 months ago
In reply to Naren Cool Geek – Tips on .NET and Java development.
In quite a few design brainstorming sessions, the debate between Spring and EJB results in a deadlock. There are developers who are damn passionate about Spring and hate EJBs. Let?s have a look at the main important differences between the two:1) Distributed Computing ? If components in your web-container need to access remote components, then EJB provides in-build support for remote method calls. The EJB container manages all RMI-IIOP connections. Spring provides support for proxying remote calls via RMI, JAX-RPC etc.
2) Transaction Support ? EJB by default uses the JTA manager provided by the EJB container and hence can support XA or distributed transactions. Spring does not have default support for distributed transactions, but it can plug in a JTA Transaction manager. Both EJB and Spring allows for declarative transaction demarcation. EJB uses deployment descriptor and Spring uses AOP.
3) Persistance ? Entity Beans provide CMP and BMP strategies, but my personal experience with these options has been devastating. Entity Beans are too slow!!!..They just suck..
Spring integrates with Hibernate, IBatis and also has good JDBC wrapper components (JdbcTemplate).
4) Security ? EJB provides support for declarative security through the deployment descriptor. But again, this incurs a heavy performance penalty and I have rarely seen projects using EJB-container managed security.-
June 29, 2006 at 5:41 am #3113369
Spring Vs EJB
by pkrouse · about 17 years, 9 months ago
In reply to Spring Vs EJB
You should revisit entity beans in an EJB3 environment such as JBoss. Orders of magnitude faster.
As for these two technologies in general, I don’t consider it an either/or proposition. I consider Spring and EJB as tools to use. I will pick up the one that makes the most sense for the project at hand.
–PK
-
June 29, 2006 at 8:26 am #3113316
Spring Vs EJB
by ivank2139 · about 17 years, 9 months ago
In reply to Spring Vs EJB
I find that Spring makes it much easier to use POJO’s and to test more
of the application with JUnit. Our Junit tests have been a big
selling point for our project when compared to other projects.
And the unit testing allows us to confront some problems earlier.In general, Spring has allowed us to write slightly more verbose but
simpler code. This is important since many of our developers are
junior level.2 years ago when we started the J2EE hosting service at Florida
Department of Environmental Protection I specifically discouraged the
use of EJB’s in favor of simpler JDBC methods. This had its own
problems, namely the proliferation of varieties of DAO’s in use.
Now that EJB3 is out we are considering it again. Along the way
though, since this is an Oracle shop, TopLink has become our preferred
persistence layer. It works fine, is simple to use, test, and
easy to understand.Ivan S Kirkpatrick
System Architect FDEP -
July 31, 2006 at 12:35 am #3208404
Spring Vs EJB
by jitrc · about 17 years, 8 months ago
In reply to Spring Vs EJB
As touched upon above, many of the objections against EJBs (e.g., Entity Beans, slow/difficult Unit Testing, etc …)have been addressed in EJB 3. Now, I guess Agile practices like Test Driven Development can also be used with EJBs more effectively (without any need for in-container testing). So, I would say EJBs still remain viable.
-
-
-
AuthorReplies

