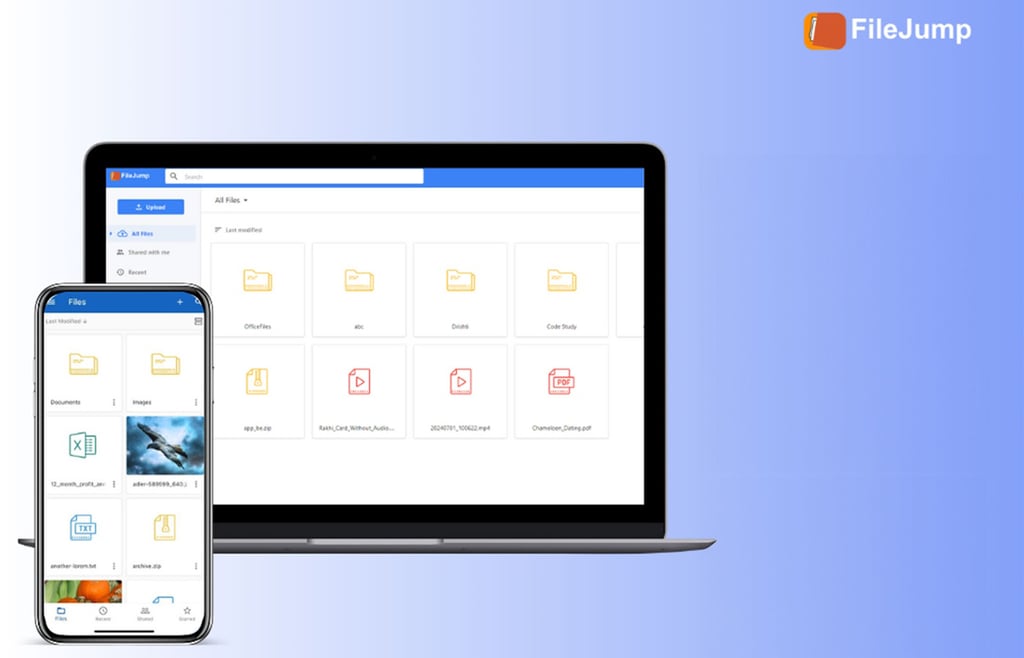
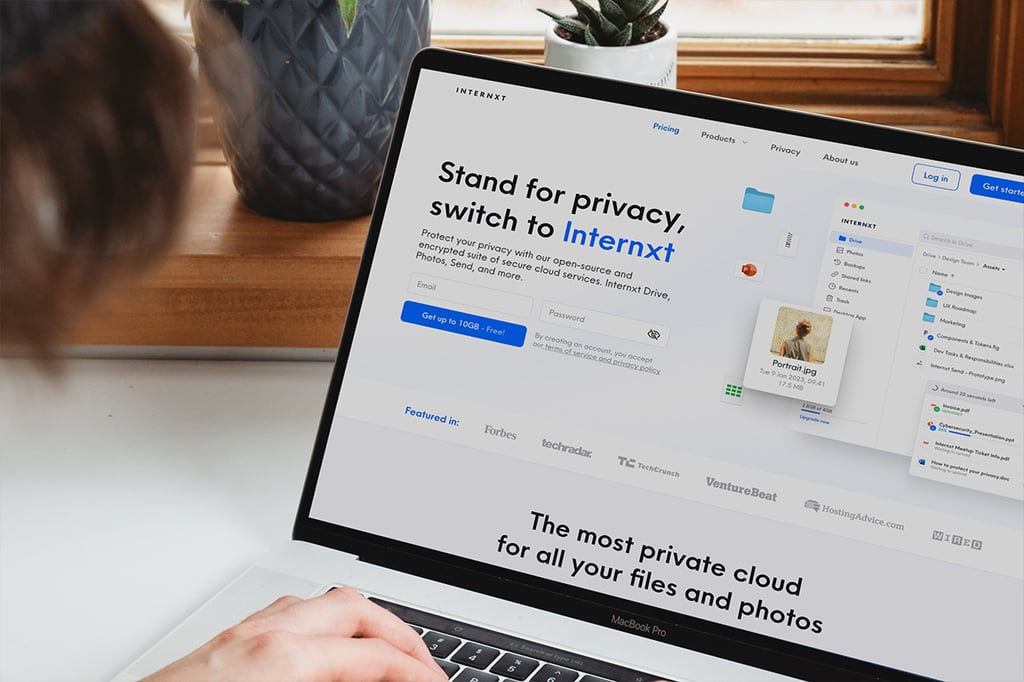
Instead of paying iCloud or Dropbox more every month, get a 20TB cloud storage that stays with you for life.