


If your data center makes use of Linux machines, one of the administrative tasks you’ll want to undertake is regularly checking the health of the SSD drives used on those machines. Why? Because, even though solid state drives will dramatically outlast rotating platter drives, they do have a finite lifespan. The last thing you want to do is fall victim to that particular end of days.
How do you check the health of those drives? As with everything in Linux, there are options. Although a GUI solution exists (GNOME Disks), I highly recommend going with a command line tool for this task. Why? Most of the time, your Linux servers won’t include a GUI; with the command line, you can easily make use of it by securely shelling into your remote Linux server and running your tests from the terminal.
The tool in question is smartctl. With this command, you can quickly glimpse your SSD health. Of course, how much mileage you get from the command will depend upon the make/model of SSD you employ. Unfortunately, the S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) tools aren’t always up to date with every SSD drive.
Because of this, you cannot be certain of the number of times your SSD chips have been written to. Even with that in mind, you can get a good estimate of the wear and tear on your drives.
Let’s install and use smartctl.
SEE: How to View Your SSH Keys in Linux, macOS, and Windows (TechRepublic)
Installation
I will be demonstrating with the Ubuntu platform. The required package is found on all the standard repositories, so adjust the installation command to fit your particular distribution of choice.
The smartctl utility is a part of the smartmontools package. This can be installed with a single command:
sudo apt install smartmontools
Do note, the above command will also install libgsasl7, libkyotocabinet16v5, libmailutils5, libntlm0, mailutils, mailutils-common, and postfix.
Once the package is installed, you’re ready to go.
SEE: Securing Linux Policy (TechRepublic Premium)
Open source: Must-read coverage
- Debian vs Ubuntu: Which Linux Distro Fits Your Needs Best?
- Ubuntu Server: A Cheat Sheet
- Llama 3 Cheat Sheet: A Complete Guide for 2024
- CISA Report Finds Most Open-Source Projects Contain Memory-Unsafe Code
Usage
To use the smartctl tool, the first thing you will want to do is gather information about the drive, which is done via the command:
sudo smartctl -i /dev/sdX
Where sdX is the name of the drive to be tested.
The above command will print out the details associated with your drive.
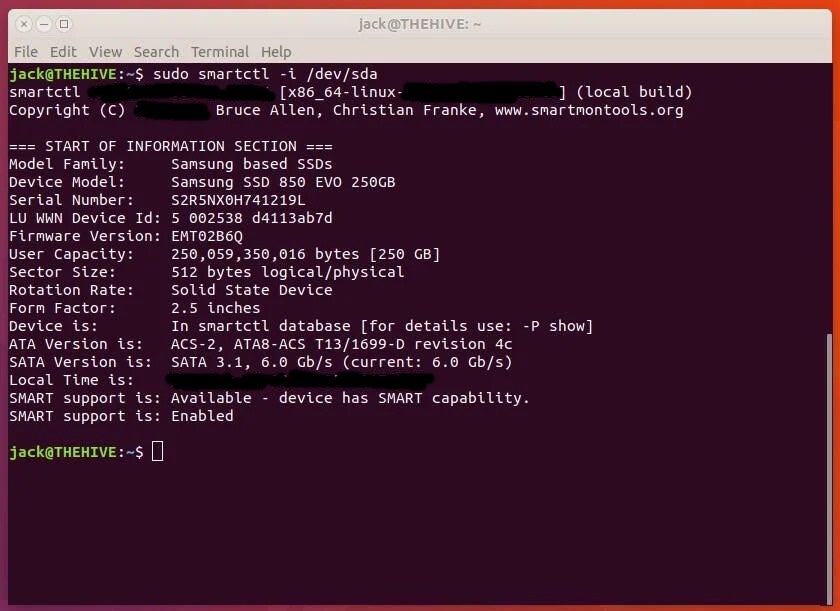
As you can see, the drive in question is in the smartctl database, so information should be up-to-date.
Let’s run a short test on the drive. These tests will actually give you the most accurate data on your drive (so it’s important to use these included tools). Issue the command:
sudo smartctl -t short -a /dev/sdX
This will immediately report some bits of information.
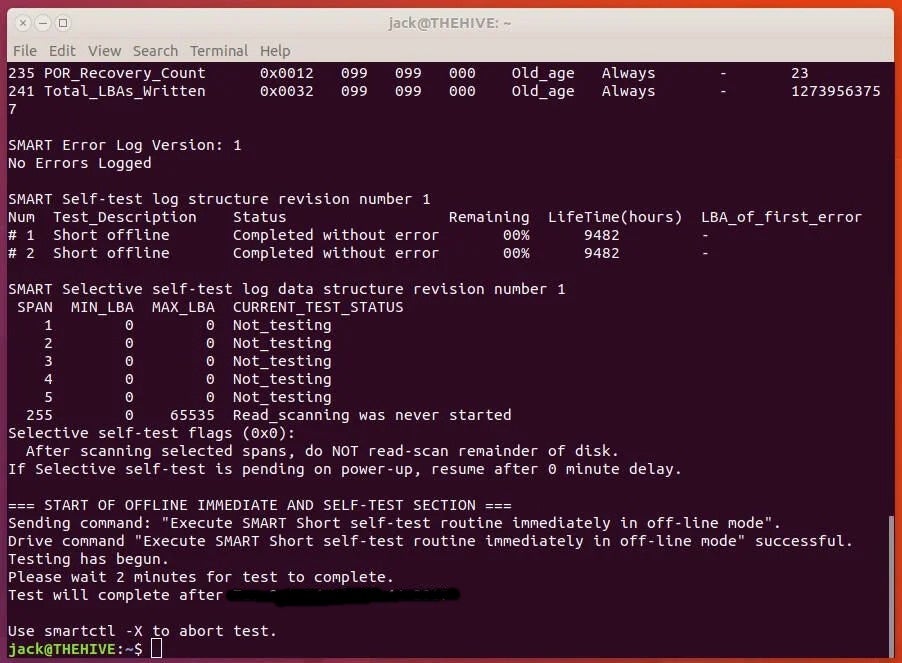
I recommend you run a short and a long test weekly or (monthly) on your drives. To run a long test, the command is:
sudo smartctl -t long -a /dev/sdX
One of the first things you should see is the results of the SMART overall health self-assessment test. That should say PASSED. If not, you know, right away there’s something wrong with your SSD.
The short test will examine the following:
- Electrical properties: The controller tests its own electronics, which differs for each manufacturer.
- Mechanical properties: Servos and positioning mechanisms are tested (also specific to each manufacturer).
- Read/verify: A certain disk area will be read to verify certain data (the size and position of the region read is unique to each manufacturer).
The long test runs everything included with the short test, while adding:
- No time restriction and in the read/verify segment.
- The entire disk is checked (as opposed to just a section).
The short test takes approximately two minutes to complete, whereas the long test will require between 20-60 minutes (depending upon your hardware). To view the results of the test, issue the command sudo smartctl -a /dev/sdX (Where sdX is the name of the drive tested).
The command will print out the test results and all of the information you need to verify the health of your SSD.
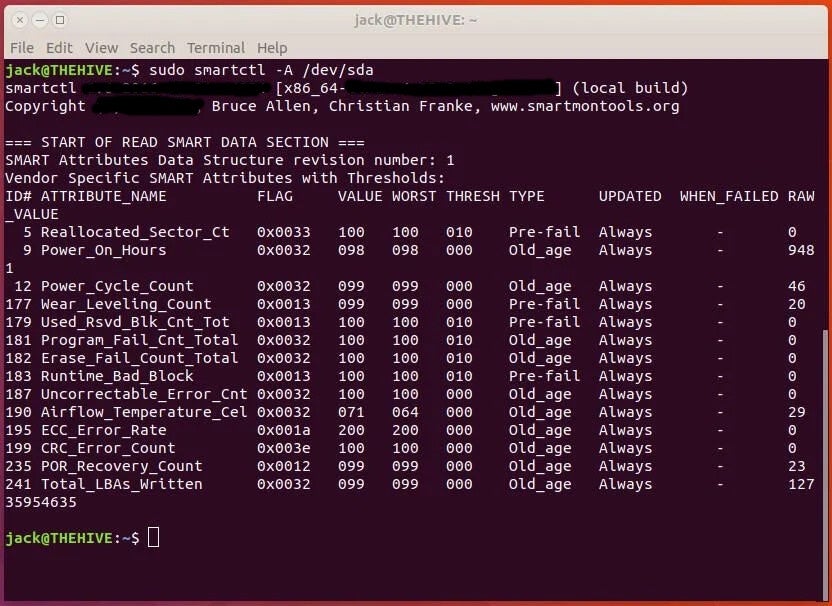
Beyond the self-test log, there are two values in the output to be examined:
- Power_On_Hours — how many hours the drive has been powered on. Each make/model of drive has a recommended “shelf life” of hours it can be used. Most modern SSDs have fairly incredible lifespans, so chances are you’re not going to bump into the end of life. If you’re using an older drive, this can be an issue.
- Wear_Leveling_Count — Stands for the remaining endurance of the drive in percentage (starting from 100 and decreasing linearly as the drive is written to).
It is important to look at the value and worst value columns. As you can see, my Samsung SSD is currently at a 99 for Wear_Leveling_Count, which is a very healthy drive.
One thing to keep in mind is that different manufacturers will report different data with smartctl. For example, I have an older Intel and Kingston SSD drives attached to the same machine. Both of these drives report similar (and more comprehensive) data. However, neither report the Wear_Leveling_Count. Why? These are both older drives and do not report ID 177 (Wear_Leveling_Count). Instead, your best bet is to run both the short and long tests and verify the health of your drives via those reports.
SEE: How to Connect to Linux Samba Shares from Windows (TechRepublic)
The obvious caveats
There are two caveats with smartctl.
First off, it’s easy to misinterpret the reported data. Because of this, you must know the make and model of the drive you are testing. Once you have that information in hand, you can research any anomalies with reported data.
Second, it is crucial to make use of the testing tools. Although you can run a command like smartctl -A /dev/sdX, you don’t get the added benefit of the testing results. Make sure to regularly run the short and long tests, to get the most up-to-date information on your SSD drives as you can.
This article was originally published in October 2017. It was updated by Antony Peyton in December 2024 to add new links and images.