


Between them, they’d racked up over $5 million in winnings on the television quiz show Jeopardy. They were the best players the show had produced over its decades-long lifetime: Ken Jennings had the longest unbeaten run at 74 winning appearances, while Brad Rutter had earned the biggest prize pot with a total of $3.25 million.
Rutter and Jennings were Jeopardy-winning machines. And in early 2011, they agreed to an exhibition match against an opponent who’d never even stood behind a Jeopardy podium before.
But this Jeopardy unknown had spent years preparing to take on the two giants in the $1m match, playing 100 games against past winners in an effort to improve his chances of winning.
That opponent didn’t smile, offered all his answers in the same emotionless tone, and wouldn’t sit in the same room as his fellow contestants. He had to work too hard at keeping his cool and was so noisy, it was thought he was too disruptive to take the podium in person. He was kept in a back room, his answers piped into the studio.
You wouldn’t know by looking at him what he was thinking – maybe you’d spot just a tinge of colour when he was puzzling over a particularly hard question.
The contender started out with a run of winning answers – he knew his Beatles songs, Olympic history, literary criminals. Sure, he wasn’t too familiar with his Harry Potter, but he stretched out a lead nonetheless, leaving Rutter and Jennings trailing thousands of dollars behind.
But questions on decades tripped him up, and Rutter fought back, piling up enough cash to unsettle anyone who’d bet on the outcome of the match. By the end of the first of the special exhibition match shows, you’d have been hard pushed to work out which was safest with your money.
But then Double Jeopardy happened. The upstart powered through the big questions, winning even with guesses he was far from convinced about, and placing odd bets that came good.
By the end of the second episode, the unknown had $25,000 more than his closest opponent, Rutter. Rutter and Jennings looked increasingly uncomfortable as it begun to look like they’d get a pasting from the new boy, bobbing in frustration as their opponent buzzed in before them time and time again.
Jennings managed a late fightback in the third episode, but the new opponent gradually clawed back enough money to make it a close run.
All three correctly answered the last question ‘William Wilkinson’s ‘An account of the principalities of Wallachia and Moldavia’ inspired this author’s most famous novel’ with ‘who is Bram Stoker?’ but Jennings appended his response with: “I for one welcome our new computer overlords”.
He, and Rutter, had lost to Watson – a room-sized beast of a machine made by IBM and named after the company’s founder Thomas J Watson.
Watson, consisting of ten racks of ten Power 750 servers, had to be kept apart from the human contestants because of the roar of its cooling system and was represented at the podium by an avatar of IBM’s Smarter Planet logo, whose moving lines would go green when Watson had cracked a thorny problem, orange when the answer was wrong.
While Watson had the questions delivered in text rather than by listening to the quizmaster, he played the game like his human counterparts: puzzle over the question, buzz in, give the answer that’s most likely to be right, tot up some prize money.
And Watson was right a lot of the time. He won the game with $77,147 leaving Rutter and Jennings in the dust with $21,600 and $24,000 respectively.
It turned out that the real Jeopardy winning machine was, well, a machine.
Three nights, two people, one machine and $1 million: the victory of IBM’s Watson over two human contestants on Jeopardy was the first, and possibly only, time the machine impressed itself on the general public’s consciousness.

But even before Watson secured its now-famous win, IBM was working on how to turn the cute quiz show-dominating machine into a serious business contender.
Watson began life five years before its TV appearance, when IBM Research execs were searching for the next “Grand Challenge” for the company. IBM periodically runs these Grand Challenges, selected projects that pit man against machine, have international appeal, are easy to grasp and attract people into working in science and maths fields. Along with Watson, the Grand Challenges have spawned Deep Blue, the machine that famously beat grand master Garry Kasparov at chess, and the Blue Gene supercomputer.
In the mid-2000s, IBM was on the lookout for its next Grand Challenge. Paul Horn, then director of IBM Research, was in favour of trying to develop a machine that could win the Turing Test, a way to measure machine intelligence by having a system attempt to fool a human into thinking that they’re having a conversation with another person.
As challenging as passing the Turing Test is – no machine has yet done it – it was felt that it wouldn’t perhaps light up the public’s imagination as other projects had. But were there any related challenges that could still bring those elements of competing against humans and understanding human speech together?
“Beating a human in Jeopardy is a step in that direction – the questions are complicated and nuanced, and it takes a unique type of computer to have a chance of beating a human by answering those type of questions. I was running the research division and I was bugging people in the organisation, in particular [former EVP in IBM’s software group] Charles Lickel,” Horn said.
Lickel was inspired to take on the challenge of building a Jeopardy-winning computer after having dinner with his team. “We were at a steak house in Fishtail, New York. In the middle of dinner, all of a sudden the entire restaurant cleared out to the bar – I turned to my team and asked ‘what’s going on?’. It was very odd. I hadn’t really been following Jeopardy, but it turned out it was when Ken Jennings was having his long winning streak, and everyone wanted to find out if he would win again that night, and they’d gone to the bar to see,” Lickel said. Jennings won once again that night, and still holds the longest unbeaten run on Jeopardy with 74 appearances undefeated.
The idea of a quiz champion machine didn’t immediately win his team around, with many of Lickel’s best staff saying they didn’t believe a machine could compete with, let alone beat, flesh and blood champions.
“They initially said no, it’s a silly project to work on, it’s too gimmicky, it’s not a real computer science test, and we probably can’t do it anyway,” said Horn.
Nonetheless, a team sufficiently adventuresome to take on the challenge of building a Jeopardy winner was found.
It was still a small project and thoughts of commercialisation weren’t uppermost in anyone’s mind – Grand Challenges were demonstration projects, whose return for the company was more in the buzz they created than in a contribution to the bottom line. If commercialisation happened, great – but for now, Watson was just a bit of a moonshot for IBM.
Due to the initial size of the effort, it was funded from the research group’s everyday budget and didn’t require sign-off from Big Blue’s higher-ups, meaning it could operate free of the commercial pressures of most projects.
Jeopardy’s quirk is that instead of the quizmaster setting questions and contestants providing the answer, the quizmaster provides the answers, known as ‘clues’ in Jeopardy-speak, to which contestants provide a question. Not only would the machine need to be able to produce questions for the possible clues that might come its way on Jeopardy, it would need to be able to first pull apart Jeopardy’s tricksy clues – work out what was being asked – before it could even provide the right response.

For that, IBM developed DeepQA, a massively parallel software architecture that examined natural language content in both the clues set by Jeopardy and in Watson’s own stored data, along with looking into the structured information it holds. The component-based system, built on a series of pluggable components for searching and weighting information, took about 20 researchers three years to reach a level where it could tackle a quiz show performance and come out looking better than its human opponents.
First up, DeepQA works out what the question is asking, then works out some possible answers based on the information it has to hand, creating a thread for each. Every thread uses hundreds of algorithms to study the evidence, looking at factors including what the information says, what type of information it is, its reliability, and how likely it is to be relevant, then creating an individual weighting based on what Watson has previously learned about how likely they are to be right. It then generated a ranked list of answers, with evidence for each of its options.
The information that DeepQA would eventually be able to query for Jeopardy was 200 million pages of information, from a variety of sources. All the information had to be locally stored – Watson wasn’t allowed to connect to the Internet during the quiz – and understood, queried and processed at a fair clip: in a Jeopardy’s case, Watson had to spit out an answers in a matter of seconds to make sure it was first to the buzzer.
“When I left IBM in end of 2007, Watson was an embryonic project,” said Horn. “It had three people in Charles Lickel’s area that got the data from the old Jeopardy programmes and were starting to train the machine. It could barely beat a five year old at that time. The projection was ‘god knows how long it would take to beat an adult, let alone a grand champion’. Then over time when it looked like they started to have a chance, Dave under the leadership of John Kelly grew the project into something substantial,” said Horn.
While there’s still debate over exactly when the idea of making Watson pay its way finally took shape at IBM, when Watson took to the stage for its Jeopardy-winning performance, the show featured IBM execs talking about possible uses for the system in healthcare, and moves to establish a Watson business unit began not long after the Jeopardy show aired.
IBM’s then-CEO Sam Palmisano and its current CEO Ginni Rometty, under whose remit Watson fell at the time, began discussions in the weeks after the win, and the project was moved from under the wing of IBM Research and into the IBM Software group.
In August of 2011, the Watson business unit proper came into being, headed up by Manoj Saxena, who’d joined IBM some years earlier when the company he worked for, Webify, was acquired by IBM.
Saxena was the unit’s employee number one. Within three months, he had been joined by 107 new Watson staffers, mostly technologists in the fields of natural language processing and machine learning.
Healthcare had already been suggested as the first industry Watson should target for commercial offerings, but there were no plans to confine it just to medicine. Any information-intensive industry was fair game, anywhere were there were huge volumes of unstructured and semi-structured data that Watson could ingest, understand and process quicker than its human counterparts. Healthcare might be a starting point, but banking, insurance, and telecoms were all in the firing line.
But how do you turn a quiz show winner into something more business-like? First job for the Watson team was to get to grips with the machine they’d inherited from IBM Research, understand the 41 separate subsystems that went into Watson, and work out what needed to be fixed up before Watson could put on its suit and tie.
In the Watson unit’s first year, the system got sped up and slimmed down. “We serialised the threads and how the software worked and drove up the performance,” Saxena said. “The system today compared to the Jeopardy system is approximately 240 percent faster and it is one-sixteenth the size. The system that was the size of a master bedroom will now run in a system the size of the vegetable drawer in your double-drawer refrigerator.”
Another way of looking at it: a single Power 750 server, measuring nine inches high, 18 inches wide and 36 inches deep, and weighing in at around 100 pounds. Having got the system to a more manageable size for businesses, it set about finding customers to take it on.
IBM had healthcare pegged as its first vertical for Watson from the time of the Jeopardy win. However, while Jeopardy Watson and healthcare Watson share a common heritage, they’re distinct entities: IBM forked the Watson code for its commercial incarnation.
Jeopardy Watson had one task – get an answer, understand it, and find the question that went with it. It was a single user system – had three quizmasters put three answers to it, it would have thrown the machine into a spin. Watson had to be retooled for a scenario where tens, hundreds, however many, clinicians would be asking questions at once, and not single questions either – complex conversation with several related queries one after the other, all asked in non-standard formats. And, of course, there was the English language itself with all its messy complexity.
“There were fundamental areas of innovation that had to be done to go beyond Jeopardy – there was a tremendous amount of pre-processing, post-processing and tooling that we have added around the core engines,” added Saxena. “It’s the equivalent of getting a Ferrari engine then trying to build a whole race car around it. What we inherited was the core engine, and we said ‘Okay, let’s build a new thing that does all sort of things the original Jeopardy system wasn’t required to do’.”
To get Watson from Jeopardy to oncology, there were three processes that the Watson team went through: content adaptation, training adaptation, and functional adaptation – or, to put it another way, feeding it medical information and having it weighted appropriately; testing it out with some practice questions; then making any technical adjustments needed – tweaking taxonomies, for example.
The content adaptation for healthcare followed the same path as getting Watson up to speed for the quiz show: feed it information, show it what right looks like, then let it guess what right looks like and correct it if it’s wrong. In Jeopardy, that meant feeding it with thousands of question and answer pairs from the show, and then demonstrating what a right response looked like. Then it was given just the answers, and asked to come up with the questions. When it went wrong, it was corrected. Through machine learning, it would begin to get a handle on this answer-question thing, and modify its algorithms accordingly.

“It would be fed many cases where the history was known and proper treatment was known, and then, analogous to training for Jeopardy, it’s been given cases and then it suggests therapies,” Kohn said.
Some data came from what IBM describes as a Jeopardy-like game called Doctor’s Dilemma, whose questions include ‘the syndrome characterized by joint pain, abdominal pain, palpable purpura, and a nephritic sediment?’. (The answer, of course, is Henoch-Schönlein purpura.)
The training, says Kohn, “is an ongoing process, and Watson is rapidly improving its ability to make reasonable recommendations the oncologists think are helpful.”
By 2012, there were two healthcare organisations that had started piloting Watson.
Wellpoint, one of the US biggest insurers, was one of the pair of companies that helped define the application of Watson in health. The other was Memorial Sloan-Kettering Cancer Center (MSKCC), an organisation IBM already had a relationship with and which is located not far from both IBM’s own Armonk headquarters and the research laboratories in York Heights, New York that still house the first Watson.
And it was this relationship that helped spur Watson’s first commercial move into working in the field of cancer therapies. While using Watson as a diagnosis tool might be its most obvious application in healthcare, using it to assist in choosing the right therapy for a cancer patient made even more sense. MSKCC was a tertiary referral centre – by the time patients arrived, they already had their diagnosis.
So Watson was destined first to be an oncologist’s assistant, digesting reams of data – MSKCC’s own, medical journals, articles, patients notes and more – along with patients’ preferences to come up with suggestions for treatment options. Each would be weighted accordingly, depending on how relevant Watson calculated they were.
Unlike its Jeopardy counterpart, healthcare Watson also has the ability to go online – not all its data has to be stored. And while Watson had two million pages of medical data from 600,000 sources to swallow, it could still make use of the general knowledge garnered for Jeopardy – details from Wikipedia, for example. (What it doesn’t use, however, is the Urban Dictionary. Fed into Watson late last year, it was reportedly removed after answering a researcher’s query with the word “bullshit”. “We did find some interesting responses, so we had to shut that down,” Saxena said diplomatically. “That is not to be repeated, because it would be seen as very improper in certain cases, and we had to teach Watson the right business behaviour.”)

As such, the sources are now medical publications like Nature and the British Medical Journal. And there are other safety nets too.
“In the teaching phase, a doctor – a cancer care specialist in this case – sits down and asks questions of Watson and corrects the machine learning. The doctor and a data scientist are sitting next to each other, correcting Watson. Spurious material, or conflicted material or something from a pharmaceutical company that the doctor feels may be biased – that is caught during the training cycle,” added Saxena.
WellPoint and MSKCC used Watson as the basis for systems that could read and understand volumes of medical literature and other information – patients’ treatment and family histories, for example, as well as clinical trials and articles in medical journals – to assist oncologists by recommending courses of treatment.
A year of working with both organisations has produced commercial products: Interactive Care Insights for Oncology, and the WellPoint Interactive Care Guide and Interactive Care Reviewer. Interactive Care Insights for Oncology provides suggestions for treatment plans for lung cancer patients, while New WellPoint Interactive Care Guide and Interactive Care Reviewer reviews clinicians’ suggested treatments against their patients’ plans and is expected to be in use at 1,600 healthcare providers this year.
Watson has bigger ambitions than a clinician’s assistant, however. Its medical knowledge is around that of a first year medical student, according to IBM, and the company hopes to have Watson pass the general medical licensing board exams in the not too distant future.
“Our work today is in the very early stages around practice of medicine, around chronic care diseases. We’re starting with cancer and we will soon add diabetes, cardiology, mental health, other chronic diseases. And then our work is on the payment side, where we are streamlining the authorisation and approval process between hospitals, clinics and insurance companies,” Saxena said.
The ultimate aim for Watson is to be an aid to diagnosis – rather than just suggesting treatments for cancer, as it does today, it could assist doctors in identifying the diseases that bring people to the clinics in the first place.
Before then, there is work to be done. While big data vendors often trumpet the growth of unstructured data and the abandoning of relational databases, for Watson, it’s these older sources of data that present more of a problem.
“Watson works specifically with natural language – free text or text-like information – and that’s approximately 80 percent of the huge volumes of healthcare information available to us,” said Kohn. “Then there’s the 20 percent that is structured data – basically, numerical data – or images, like MRIs, CAT scans, and so on. Watson does not process structured data directly and it doesn’t interpret images. It can interpret the report attached to an image, but not the image itself.”
In addition, IBM is working on creating a broader healthcare offering that will take it beyond its oncology roots.
“Even though Watson is working with these two organisations, what the designers and computer scientists are focusing on [is] that whatever they develop is generalisable, it’s not just niche for cancer therapy and especially for the several cancers we’re working with. We’re using it as a learning process to create algorithms and methodologies that would be readily generalisable to any area of healthcare. They don’t have to have to say, right, we have oncology under control, now let’s start again with family practice or cardiology,” Kohn said.

Watson has also already found some interest in banking. Citi is using Watson to improve customer experience with the bank and create new services. It’s easy to see how Watson could be put to use, say, deciding whether a borderline-risk business customer is likely to repay the loan they’ve applied for, or used to pick out cases of fraud or identity theft before customers may be aware they’re happening.
Citi is still early in its Watson experiments. A spokeswoman said the company is currently just “exploring use cases”.
From here on in, rather than being standalone products, the next Watson offerings to hit the market will be embedded into products in the IBM Smarter Planet product line. They’re expected to appear in the second half of the year.
The first such Smarter Planet product appeared in May: IBM Engagement Advisor. The idea behind the Engagement Advisor, aimed at contact centres, is that customer service agents can query their employers’ databases and other information sources using natural language while they’re conducting helpline conversations with their clients. One of the companies testing out the service is Australia’s ANZ bank, where it will be assisting call centre staff with making financial services recommendations to people who ring up.
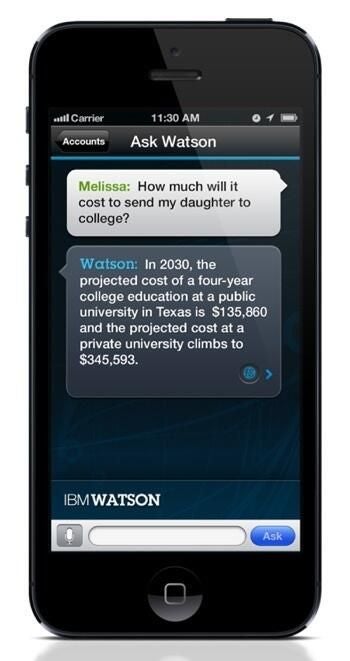
Watson could presumably one day scour available evidence for the best time to find someone able to talk and decide the communication channel most likely to generate a positive response, or pore over social media for disgruntled customers and provide answers to their problems in natural language.
There are also plans to change how Watson’s delivered, too. Instead of just interacting with it via a call centre worker, customers will soon be able to get to grips with the Engagement Advisor. Rather than have some call centre agent read out Watson generated information to a customer with, say, a fault with their new washing machine or a stock-trader wanting advice on updating their portfolio, the consumer and trader could just quiz Watson directly from their phone or tablet, by typing their query straight into a business’ app. Apps with Watson under the hood should be out in the latter half of this year, according to Forbes.
IBM execs have also previously suggested that Watson could end up a supercharged version of Siri, where people will be able to speak directly into their phone and pose a complex question for Watson to answer – a farmer holding up his smartphone to take video of his fields, and asking Watson when to plant corn, for example.
IBM is keen to spell out the differences between Watson and Siri. “Watson knows what it knows – and by listening, learning and using human-like thinking capabilities uncovers insights from Big Data, Watson also quickly ascertains what it doesn’t know. Siri, on the other hand, simply looks for keywords to search the web for lists of options that it chooses one from,” the company says. But, the comparison holds: Watson could certainly have a future as your infinitely knowledgeable personal assistant.
While adding voice-recognition capabilities to Watson should be no great shakes for IBM given its existing partnerships, such a move would require Watson to be able to recognise images (something IBM’s already working on) that would require Watson to query all sorts of sources of information including newspapers, books, photos, repositories of data that have been made publicly available, social media and the internet at large. That Watson should take on such a role in the coming years, especially if the processing goes on in an IBM datacentre and not on the mobile itself, as you would expect, is certainly within the realms of the possible.
As IBM seeks to embed Watson’s capabilities into more and more products, how far does the company think Watson will spread in the coming years? It will only say gnomically, “as we continue to scale our capabilities, we intend to make Watson available as a set of services in many industries.” Want a better answer? Better ask Watson.