



As organizations start to make more extensive use of machine learning, they need to manage not just their data and the machine learning models that use it but the features that organize the raw data into concepts the models can work with.
SEE: Artificial Intelligence Ethics Policy (TechRepublic Premium)
Earlier this year, LinkedIn open sourced Feathr, the feature store it uses internally for hundreds of different machine learning-powered services using petabytes of data, like showing interesting jobs or blog posts that you might want to read. It’s the technology behind the Azure Feature Store service, and it’s now become part of the Linux Foundation AI & Data Foundation to make it more useful to a wider range of development teams.
“Feature stores and Feathr are an important piece of how to do MLOps and how to do to deploy machine learning models efficiently, effectively and compliantly by covering all of the things that the enterprise needs to think about,” David Stein, a senior staff engineer working on Feathr at LinkedIn told TechRepublic.
How the machine learning finds features
In machine learning terms, a feature is a specific data input to a machine learning model — think of it like a column in a database or a variable in code.
“If you’re trying to predict whether a person is going to buy a car, and you have a person and a car as the input to the model, and the prediction is a likelihood of buying or not wanting to buy, features that the model might be designed to use may include things like the person’s income level or their favorite color: Things you know about them and the things about the car,” Stein said. “If you have a giant data set with a billion rows, you would want to pick a set of columns as the starting point and you’re then going to design your model around how to use those features in order to make the prediction.”
Some of the features are right there in the data, like product IDs and dates, but others need to be processed, so it’s more complicated than just pointing at the columns you want in a database.
More must-read AI coverage
- SS&C Intralinks DealCentre AI vs. Datasite: Which platform is built for the future of dealmaking?
- SS&C Intralinks FundCentre AI vs. Juniper Square: Which platform better supports modern private markets fund managers?
- Why Data, Not Models, Determines AI Success
- The Rise of the AI-Native Factory: How Physical AI Is Transforming Manufacturing
“All the other useful features that you’re going to need may need to be computed and joined and aggregated from various other data assets,” Stein explained.
If your machine learning model works with transactions, the average value of transactions in restaurants over the last three months would be that kind of feature. If you’re building a recommendation system, the data is tables of users, items and purchases, and the feature would be something you can use to make recommendations, like what products have been bought over the last week or month, whether someone bought the product on a weekday or weekend, and what the weather was like when they bought it.
Complex machine learning systems have hundreds or thousands of features, and building the pipeline that turns the data into those features is a lot of work. They have to connect to multiple data sources, combine the features with the labeled data while preserving things like “point in time” correctness, save those features into low latency storage and make sure the features are handled the same way when you’re using those models to make predictions.
“At LinkedIn, there are many, many data assets like databases and ETL data stores and different kinds of information about job postings, advertising, feed items, LinkedIn users, companies, skills and jobs, and all these things as well as the LinkedIn economic graph,” Stein said. “There’s a huge number of different entities that may be related to a particular prediction problem.”
Just finding and connecting to all those datasets is a lot of work, before you start choosing and calculating the various features they contain.
“Engineers that would build the machine learning models would have to go to great lengths to find the details of the various data assets that those many signals might need to come from,” Stein said. They also have to spend time normalizing how to access the data: Different data sources may label the same information as user ID, profile ID or UID.
Two people using the same data to train different models can end up creating the same feature for their different projects. That’s wasted effort, and if the feature definitions are slightly different, they might give confusingly different answers. Plus, each team has to build a complex feature engineering pipeline for every project.
Feathr: A platform for features
A feature store is a registry for features that lets you do all that work once. Every project can use the same pipeline, and if you need a feature that another developer has already created, you can just reuse it. This is the function of Feathr (Figure A).
Figure A
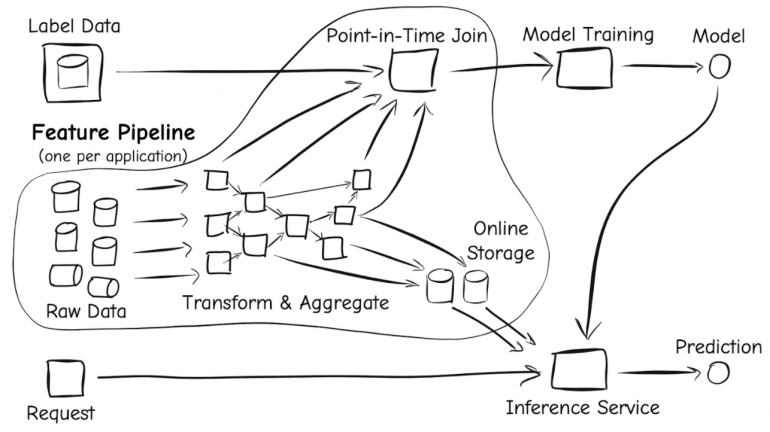
Stein suggests thinking about them rather like package managers.
“Feature stores are about making it simpler and easier to be able to import the data that you need into your machine learning application and machine learning model,” he said. “That can often be a very complex setup, especially for large projects that are run over a range of time, and especially in companies where there are many projects using similar datasets. We want to make it easy for the machine learning engineer to just import their features as their inputs and then write their model code.”
Instead of finding the right dataset and writing the code to aggregate data into features, Stein further explained that “the machine learning engineer would like to be able to say ‘okay, I want the user’s number of years of experience, I want something about their company’ and just have it appear as columns in an input table.” That way, they can spend their time working on the model rather than feature infrastructure.
This means a lot less work for developers on every machine learning project; in one case, thousands of lines of code turned into just ten lines because of Feathr. In another, what would have been weeks of work was finished in a couple of hours because the feature store has built-in operators.
The fewer manual processes there are in any development pipeline, the less fragile it will be, because you’re not asking somebody to do a complicated thing by hand perfectly every time. Having those inbuilt features means more people can use these sophisticated techniques.
“Feathr provides the ability to define sliding window activity signals on raw event data,” Stein said. “That used to be hard to do at all without a platform that knows how to do that properly. Getting it right using more basic tooling was hard enough that many teams wouldn’t even experiment with using signals like that.”
Feathr also does the work of storing features in a low latency cache so they’re ready to use in production.
“When the application is trying to do an inference, it asks for the values of some features so that it can run that through its model to make some prediction,” Stein added. “You want the feature store machinery to answer quickly so that that query can be answered very quickly.”
You don’t need that low latency when you’re training your machine learning model, so that can pull data from other locations like Spark, but with Feathr you don’t have to write different code to do that.
“From the point of view of the machine learning engineer writing the model code, we want those things to look the same,” Stein said.
Accuracy and repeatability matter for machine learning, as so does knowing how models produce their results and what data they’re using. A feature store makes it easier to audit that (the Azure Feature Store has a friendly user interface that shows where data comes from and where it’s used), and can make it easier to understand as well because you see simplified naming rather than all the different data identifiers (Figure B).
Figure B
Even though data access is centralized through a feature store, Feathr uses Role Base Access Control to make sure only people who should have access to a dataset can use it for their model. The open source Feathr uses Azure Purview, which means you can set access controls once and have them applied consistently and securely everywhere.
Effective enterprise machine learning
Because it was built for the technology and configurations that LinkedIn uses internally, open sourcing Feathr also meant making it more generalized, so it would be useful for businesses who use different technologies from those at LinkedIn.
“There’s a growing number of people in the industry that have this kind of problem,” Stein noted. “Each individual organization building feature pipelines needs to figure out how to solve those engineering challenges, how to make sure things are being used in the right way — these are things that you can build once and build well in a platform solution.”
The first step was working with Microsoft to make Feathr work well on Azure. That includes support for more data sources more common in the industry at large than at LinkedIn (Figure C).
Figure C
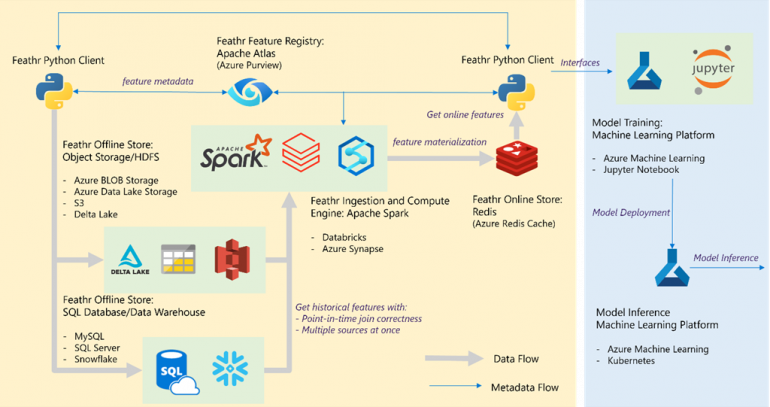
If you’re using Feathr on Azure, you can pull data from Azure Blob Storage, Azure Data Lake Storage, Azure SQL databases and data warehouses. Once the features have been defined, they can be generated using Spark running in Azure Databricks or Azure Synapse Analytics.
Features are stored in an Azure Redis cache for low-latency serving and registered in Azure Purview for sharing between teams. When you want to use features in a machine learning model, they can be called from inside Azure Machine Learning: Deploy the model to an Azure Kubernetes Service cluster and it can retrieve features from the Redis cache.
Bringing the project to the LF AI & Data Foundation is the next step and will take Feathr beyond the Azure ecosystem.
“The collaboration and affiliation improves the network of people working on Feathr,” Stein said. “We have access to resources and opportunities for collaboration with related projects.”
Collaboration and contribution is important because feature stores are a fairly new idea.
“The industry is growing towards a more solid understanding of the details of what these tools need to be and what they need to do, and we’re trying to contribute to that based on what we’ve learned,” he added.
As often happens when open sourcing a project, that work also made Feathr better for LinkedIn itself.
“LinkedIn engineering has a culture of open sourcing our things that we believe are generally useful and would be of interest to the industry,” Stein said.
New users are an opportunity for the people who built the tool to learn more about what makes it useful by seeing how it can be used to solve increasingly diverse problems. It’s also a forcing function for making documentation good enough that a new user can pick up the project and understand how to use it to solve a problem and how it compares to alternatives, he pointed out.
“There are many things that belong in a well-rounded product,” Stein said. “Open sourcing and putting a solution out into the public view is a great opportunity to do those things to make the product great. Bringing Feathr to the open source community and now to the Linux Foundation is part of the process of continuing to evolve this into a better tool that works for a broader variety of machine learning and use cases. It is the path to make it better: Selfishly, for LinkedIn, but also for the community.”