


OpenAI released its video generator Sora to select tiers of ChatGPT users on Dec. 9 as part of the cascade of “shipmas” announcements.
The organization first demonstrated Sora’s capabilities in February 2024. In the intervening months, they’ve built a faster version and explored how to release AI video generators responsibly.
OpenAI’s emphasis on safety around Sora is standard for generative AI nowadays. Still, it also shows the importance of precautions regarding AI that could be used to create convincing fake images, which could, for instance, damage an organization’s reputation.
As of Dec. 10, account creation on Sora was closed due to high demand. Sora was open again as of Dec. 16.
What is Sora?
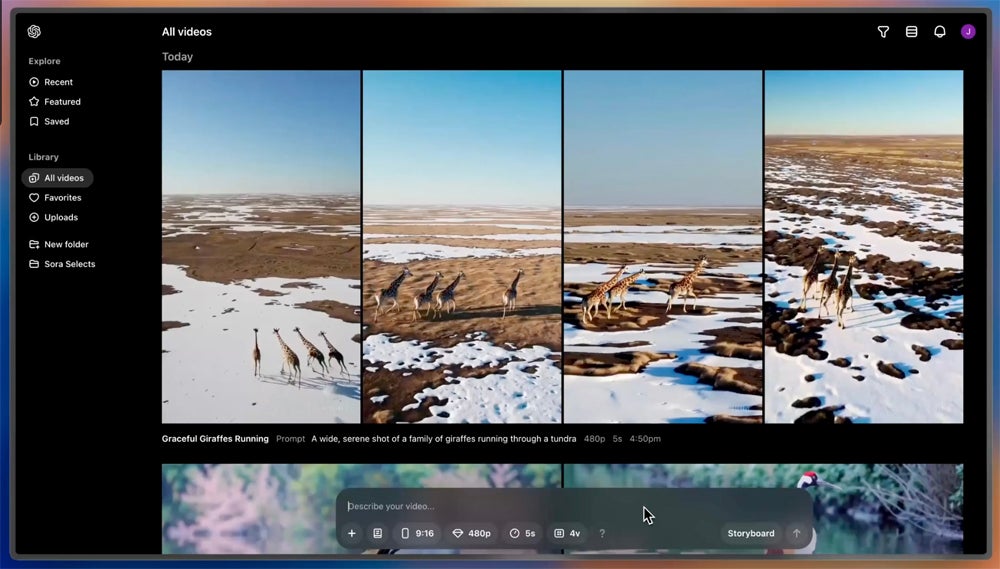
Sora is a generative AI diffusion model. Sora can generate multiple characters, complex backgrounds, and realistic-looking movements in videos up to a minute long. It can also create multiple shots within one video, keeping the characters and visual style consistent and making Sora an effective storytelling tool.
Sora could be used to generate videos to accompany content, promote content or products on social media, or illustrate points in business presentations. While it shouldn’t replace the creative minds of professional video makers, Sora could be used to make some content more quickly and easily.
“Media and entertainment will be the vertical industry that may be early adopters of models like these,’ Gartner Analyst and Distinguished VP Arun Chandrasekaran Chandrasekaran told TechRepublic in an email in February. “Business functions such as marketing and design within technology companies and enterprises could also be early adopters.”
The UK, Switzerland, and parts of Europe won’t get access to Sora for now
Currently, Sora is available in every region with access to ChatGPT except the United Kingdom, Switzerland, and the European Economic Area. The Guardian pointed out that Sora still needs to comply with the European Union’s GDPR and Digital Services Act and the UK’s Online Safety Act. OpenAI said in December it plans to expand access “in the coming months.”
How do I access Sora?
As of December, ChatGPT Plus and Pro users can access Sora at sora.com.
Sora videos can be in 1080p resolution, up to 20 sec long, and in widescreen, vertical, or square aspect ratios. The interface allows users to insert their own content, and the “storyboard” tool helps users organize their prompts in sequence.
More must-read AI coverage
- SS&C Intralinks DealCentre AI vs. Datasite: Which platform is built for the future of dealmaking?
- SS&C Intralinks FundCentre AI vs. Juniper Square: Which platform better supports modern private markets fund managers?
- Why Data, Not Models, Determines AI Success
- The Rise of the AI-Native Factory: How Physical AI Is Transforming Manufacturing
How does Sora work?
Sora is a diffusion model, meaning it gradually refines a nonsense image into a comprehensible one based on the prompt and uses a transformer architecture. The research OpenAI performed to create its DALL-E and GPT models — particularly the recapturing technique from DALL-E — were stepping stones to Sora’s creation.
SEE: Chief AI officers may be key in APAC in 2025.
Sora videos don’t always look realistic
Sora still has trouble telling left from right or following complex descriptions of events that happen over time, such as prompts about a specific camera movement. Videos created with Sora are likely to be spotted through errors in cause-and-effect, OpenAI said in February, such as a person taking a bite out of a cookie but not leaving a bite mark.
For instance, interactions between characters may show blurring (especially around limbs) or uncertainty in terms of numbers (e.g., how many wolves are in the video below at any given time?).
What are OpenAI’s safety precautions around Sora?
With the right prompts and tweaking, Sora’s videos can easily be mistaken for live-action. OpenAI is aware of possible defamation or misinformation problems arising from this technology. The company said in December that it has guardrails in place to prevent “child sexual abuse materials and sexual deepfakes.” Uploads of people in general are “limited.”
If Sora is released to the public, OpenAI plans to watermark content created with Sora with C2PA metadata. The metadata can be viewed by selecting the image and choosing the File Info or Properties menu options. People who create AI-generated images can still remove the metadata on purpose or may do so accidentally.
OpenAI does not currently have anything in place to prevent users of its image generator, DALL-E 3, from removing metadata.
“OpenAI’s decision to delay public access to Sora, despite having the opportunity to release it sooner, is certainly commendable,” said Nana Nwachukwu, AI ethics and governance consultant at Saidot, in an email to TechRepublic.
However, she said, it’s too early to say how effective OpenAI’s mitigation strategies will be or whether it will be released in the EU.
“Governance must evolve alongside the technology to monitor and manage these risks,” said Nwachukwu. “Without continuous oversight and robust industry standards, the promise of innovation risks being overshadowed by the threat of misinformation and harm.”
“It is already [difficult] and increasingly will become impossible to detect AI-generated content by human beings,” Chandrasekaran said in February. “VCs are making investments in startups building deepfake detection tools, and they (deepfake detection tools) can be part of an enterprise’s armor. However, in the future, there is a need for public-private partnerships to identify, often at the point of creation, machine-generated content.”
What are the competitors to Sora?
Sora’s photorealistic videos are quite distinct, but similar services exist. Perhaps the most high-profile among them are Google’s Veo, now in private preview, and Amazon’s upcoming Nova Reels.
Runway provides ready-for-enterprise text-to-video AI generation. Fliki can create limited videos with voice synching for social media narration. Generative AI can now reliably add content to or edit videos taken conventionally as well.
On Feb. 8, Apple researchers revealed a paper about Keyframer’s proposed large language model that can create stylized, animated images.
Editor’s note: This article was originally posted in February and updated in December.