
Apache Spark and Apache Hadoop are both popular, open-source data science tools offered by the Apache Software Foundation. Developed and supported by the community, they continue to grow in popularity and features.
Apache Spark is designed as an interface for large-scale processing, while Apache Hadoop provides a broader software framework for the distributed storage and processing of big data. Both can be used either together or as stand-alone services.
Jump to:
- What is Spark?
- What is Hadoop?
- Apache Spark vs. Apache Hadoop: Comparison table
- Apache Spark and Apache Hadoop pricing
- Feature comparison: Apache Spark vs. Apache Hadoop
- Spark pros and cons
- Hadoop pros and cons
- Review methodology
- Should your organization use Spark or Hadoop?
What is Apache Spark?
Apache Spark is an open-source data processing engine built for efficient, large-scale data analysis. A robust unified analytics engine, Apache Spark is frequently used by data scientists to support machine learning algorithms and complex data analytics. It can be run either standalone or as a software package on top of Apache Hadoop.
What is Apache Hadoop?
Apache Hadoop is a collection of open-source modules and utilities intended to make the process of storing, managing and analyzing big data easier. Its modules include Hadoop YARN, Hadoop MapReduce and Hadoop Ozone, but it also supports many optional data science software packages. Apache Hadoop may be used interchangeably to refer to Apache Spark and other data science tools.
SEE: For more clarity on how to approach Hadoop, check out our Hadoop cheat sheet.
Apache Spark vs. Apache Hadoop: Comparison table
| Features | Apache Spark | Apache Hadoop |
|---|---|---|
| Batch processing | Yes | Yes |
| Streaming | Yes | No |
| Easy to use | Yes | No |
| Caching | Yes | No |
| Visit Apache Spark | Visit Apache Hadoop |
Spark and Hadoop pricing
It’s important to note that while Apache Spark itself is free and open-source, the total cost of ownership can increase significantly when you factor in the cost of cloud resources, especially for large-scale data processing tasks. Additionally, if you require professional support, you may need to invest in a commercial distribution of Spark, which comes at an additional cost.
Like Spark, Apache Hadoop is an open-source project and free to use. However, if you want to use Hadoop in the cloud or opt for a distribution of Hadoop like Cloudera or Hortonworks, there will be costs associated with it. Similar to Spark, the costs can add up when you consider cloud resources and professional support. Plus, some distributions of Hadoop may come with additional features that are not available in the open-source version.
Feature comparison: Spark vs. Hadoop
Batch processing
Must-read big data coverage
- What Powers Your Databases? Take This DZone Survey Today!
- New AI Data ‘Universal Translator’ From Salesforce, Snowflake, Others
- Top Tech Conferences & Events to Add to Your Calendar in 2025
- Google Releases Data Commons MCP Server to Supercharge AI Agents
Spark’s batch processing is highly efficient due to its in-memory computation capabilities. This makes Spark an excellent choice for tasks that require multiple operations on the same dataset as it can perform these operations in memory, significantly reducing the time required. However, this high-speed processing can come at the cost of higher memory usage.
Hadoop, on the other hand, is designed for high-throughput batch processing. It excels at storing and processing large datasets across clusters of computers using simple programming models. Although Hadoop can be slower than Spark’s in-memory processing, its batch processing is highly scalable and reliable, making it a good choice for tasks that require the processing of very large datasets.
Streaming
Spark Streaming (Figure A) is an extension of the core Spark API that allows real-time data processing. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data. However, because it processes data in mini-batches, there can be a slight delay, meaning it’s not truly real-time.
Figure A
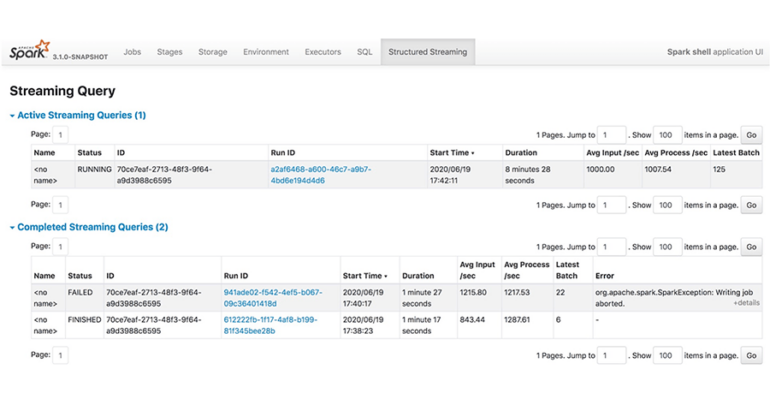
Hadoop itself does not support real-time data processing. However, real-time processing can be achieved with additional components like Apache Storm or Apache Flink, though integrating these additional components can add complexity to the Hadoop ecosystem.
Ease of use
Due to its narrower focus compared to Hadoop, Spark is easier to learn. Apache Spark has a handful of core modules and provides a clean, simple interface (Figure B) for the manipulation and analysis of data. As Apache Spark is a fairly simple product, the learning curve is slight.
Figure B
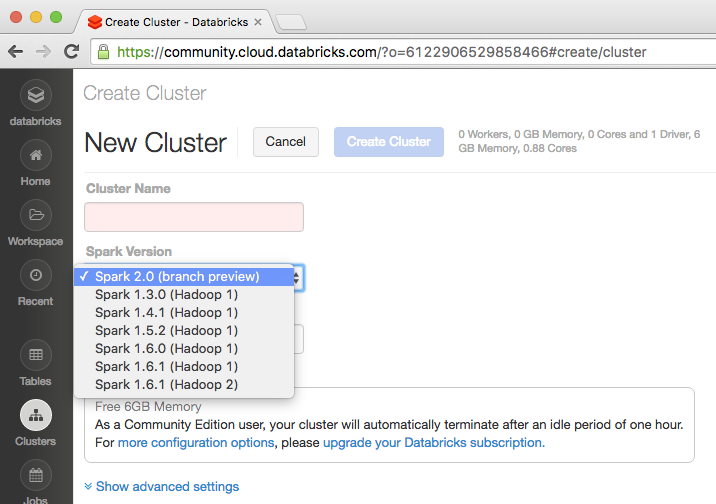
Apache Hadoop is far more complex. The difficulty of engagement will depend on how a developer installs and configures Apache Hadoop and which software packages the developer chooses to include. Regardless, Apache Hadoop has a far more significant learning curve, even out of the box.
Speed
For most implementations, Apache Spark will be significantly faster than Apache Hadoop. Built for speed, Apache Spark may outcompete Apache Hadoop by nearly 100 times the speed. However, this is because Apache Spark is an order of magnitude simpler and more lightweight.
By default, Apache Hadoop will not be as fast as Apache Spark. However, its performance may vary depending on the software packages installed and the data storage, maintenance and analysis work involved.
Security and fault tolerance
When installed as a stand-alone product, Apache Spark has fewer out-of-the-box security and fault-tolerance features than Apache Hadoop. However, Apache Spark has access to many of the same security utilities as Apache Hadoop, such as Kerberos Authentication — they just need to be installed and configured.
SEE: Use TechRepublic Premium’s database engineer hiring kit for your next job listing.
By comparison, Apache Hadoop has a broader native security model and is extensively fault-tolerant by design. Like Apache Spark, its security can be further improved through other Apache utilities.
Programming languages
Apache Spark supports Scala, Java, SQL, Python, R, C# and F#. It was initially developed in Scala but has since implemented support for nearly all of the popular languages data scientists use.
Apache Hadoop is written in Java, with portions written in C. Apache Hadoop utilities support other languages, making it suitable for data scientists of all skill sets.
Spark pros and cons
Pros of Spark
- Spark’s in-memory processing capabilities make it faster than Hadoop for many data processing tasks.
- Spark provides high-level APIs, which make it easier to use than Hadoop.
- Unlike Hadoop, Spark supports real-time data processing.
Cons of Spark
- Spark’s in-memory processing can consume a lot of memory, which can be a limitation for tasks with large data sets.
- Although Spark is growing rapidly, its ecosystem is not as mature as Hadoop’s.
- While Spark itself is free, the costs associated with cloud resources and commercial distributions can be high.
Hadoop pros and cons
Pros of Hadoop
- Hadoop is highly scalable and can handle large volumes of data across many servers.
- Hadoop is fault-tolerant, meaning that it is designed to operate even when some servers fail.
- Hadoop can handle structured and unstructured data, making it versatile for various data processing tasks.
Cons of Hadoop
- Hadoop can be complex to set up and manage, particularly for beginners.
- Its batch-processing model can be slower than Spark’s in-memory processing for certain tasks.
- Hadoop doesn’t support real-time data processing, which can be a limitation for some use cases.
Review methodology
We thoroughly analyzed each product’s features, pricing, ease of use, community support and performance. We also took into account verified user reviews and the reputation of both products in the industry to provide a balanced and unbiased comparison.
Should your organization use Spark or Hadoop?
If you are a data scientist working primarily in machine learning algorithms and large-scale data processing, choose Apache Spark as it:
- Runs as a stand-alone utility without Apache Hadoop.
- Provides distributed task dispatching, I/O functions and scheduling.
- Supports multiple languages, including Java, Python and Scala.
- Offers implicit data parallelism and fault tolerance.
If you are a data scientist who requires a large array of data science utilities for the storage and processing of big data, choose Apache Hadoop since it:
- Offers an extensive framework for the storage and processing of big data.
- Provides an incredible array of packages, including Apache Spark.
- Builds upon a distributed, scalable and portable file system.
- Leverages additional applications for data warehousing, machine learning and parallel processing.
If you’re considering a career in data science, our How to become a data scientist: A cheat sheet article might be of interest.