



Apache Druid is a real-time analytics database that was designed for lighting quick slice-and-dice analytics on massive sets of data. You can easily run Apache Druid from a desktop version of Linux – or a Linux server with a GUI – and then load data to begin to parse.
Apache Druid includes features such as:
- Column-oriented storage
- Native search indexes
- Streaming and batch ingest
- Flexible schemas
- Time-optimized partitioning
- SQL support
- Horizontal scalability
- Easy operation
Apache Druid is a great option for use cases that require real-time ingestion, fast queries and high uptime.
I’m going to walk you through the process of getting Apache Druid running on Pop!_OS Linux (though it can be run on any Linux distribution) and then show you how to load sample data.
SEE: Hiring Kit: Database engineer (TechRepublic Premium)
What you’ll need
The only things you’ll need to make this work are a running instance of Linux complete with a desktop environment and a user with sudo privileges.
That’s it. Let’s make some database magic.
How to install Java 8
At the moment, Apache Druid only supports Java 8, so we have to make sure it’s installed and set as the default. To install Java 8 on a Ubuntu-based desktop distribution, log into the machine, open a terminal window, and issue the command:
sudo apt install openjdk-8-jdk -y
After the installation completes, you then need to set Java 8 as the default. Do this with the command:
sudo update-alternatives --config java
You should see a list of all Java versions that are currently installed on the machine. Make sure to select the number that corresponds to Java 8.
A word on Apache Druid services
What we’re going to launch is a micro instance of Apache Druid, which requires 4 CPUs and 16GB of RAM. There are 6 different service configurations for Apache Druid, which are:
- Nano-Quickstart: 1 CPU, 4GB RAM
- Micro-Quickstart: 4 CPU, 16GB RAM
- Small: 8 CPU, 64GB RAM
- Medium: 16 CPU, 128GB RAM
- Large: 32 CPU, 256GB RAM
- X-Large: 64 CPU, 512GB RAM
Depending on the size of your data and needs. When you get into massive troves of data, it’s recommended that Apache Druid be deployed as a cluster. However, since we’re just getting introduced to Apache Druid, the micro instance will be just fine.
Must-read developer coverage
- What Powers Your Databases? Take This DZone Survey Today!
- Microsoft’s Historic 6502 BASIC Code is Now Open Source
- TIOBE Index: Top 10 Most Popular Programming Languages
- TechRepublic Exclusive: AWS Says Entry-Level Workers Need ‘Curiosity’ In the Age of AI
How to download and unpack Apache Druid
With Java installed, it’s time to download and unpack Apache Druid. Back at the terminal window, download the latest version (make sure to check the Apache Druid download page to verify this is the latest release) with the command:
wget https://dlcdn.apache.org/druid/0.22.1/apache-druid-0.22.1-bin.tar.gz
Unpack the downloaded file with:
tar xvfz apache-druid-0.22.1-bin.tar.gz
Change into the newly-created directory with:
cd apache-druid-0.22.1
Start the service with:
./bin/start-micro-quickstart
The Apache Druid service should launch without a problem. Do note, that you will not get your terminal back as the service runs until you cancel it with CTRL + C.
How to access the Apache Druid console
On the same machine that’s running Apache Druid, open a web browser and point it to http://localhost:8888. Unfortunately, Apache Druid is set up such that you cannot reach it from a remote machine, which is why we install it on a desktop machine.
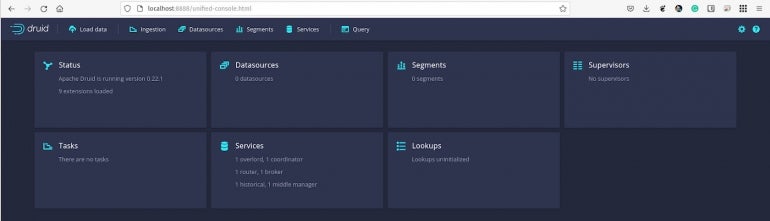
The Apache Druid console will greet you (Figure A).
Figure A
How to load data
We’re going to load up a predefined sample of data, found in the quickstart/tutorial/directory. The sample is called wikiticker-2015-09-12-sampled.json.gz.
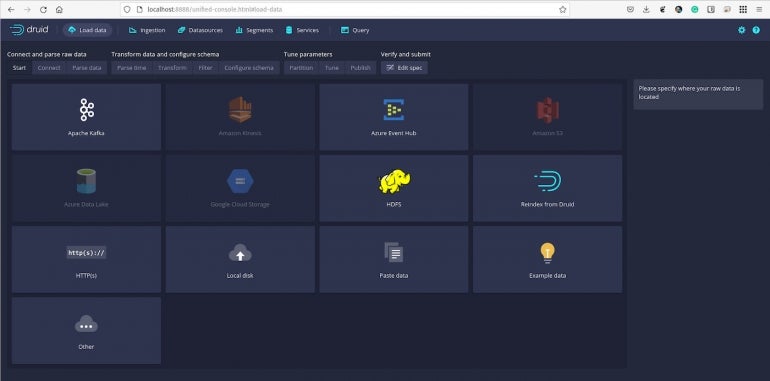
Figure B
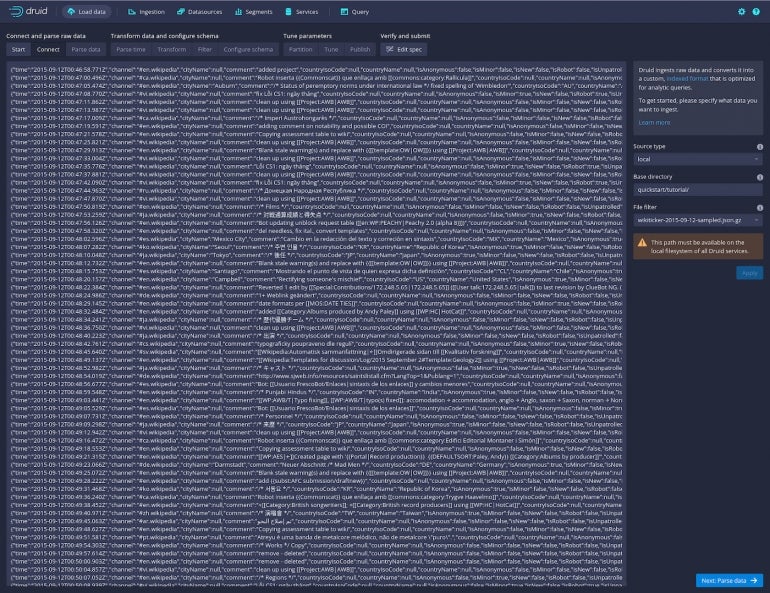
Click Connect Data (on the right side of the window) and then, in the resulting sidebar (Figure C), type quickstart/tutorial as the base directory and wikiticker-2015-09-12-sampled.json.gz in the File Filter section.
Figure C

Click Apply and you should see a fairly large amount of data appear in the main window (Figure D).
Figure D
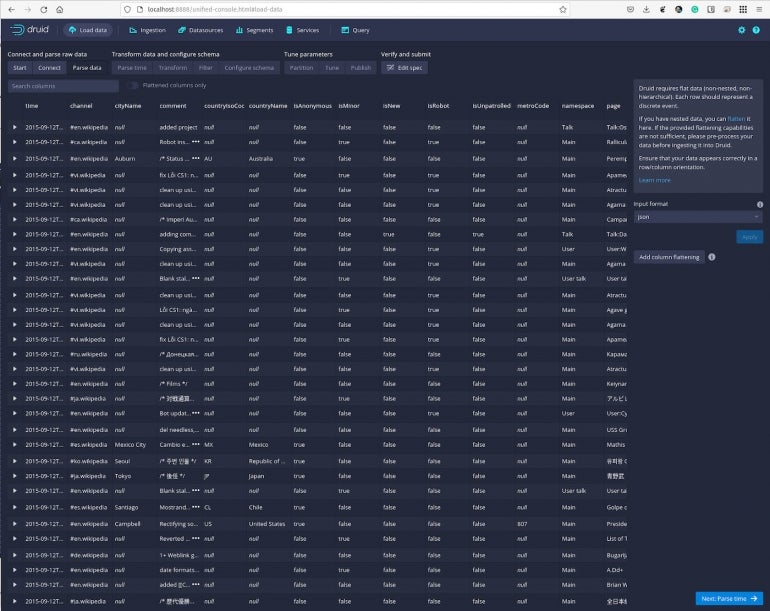
Click Next: Parse Data at the bottom right and you’ll be presented with a listing of the data in a more readable format (Figure E).
Figure E
Click Next: Parse Time and you can view the data against particular timestamps (Figure F).
Figure F
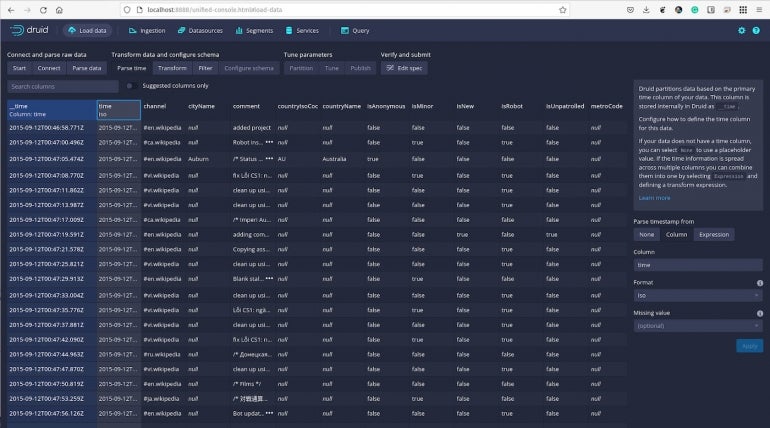
Click Next: Transform and you can then perform per-row transforms of the column values to either create new columns or alter those that already exist.
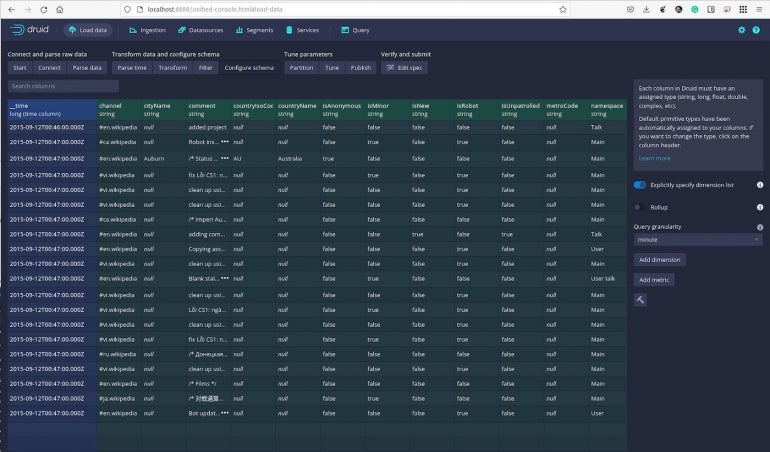
Keep clicking through the data and, at any point, you can run queries and filter data as needed. In the Configure Schema section (Figure G), you can even specify the granularity of your queries and add dimensions and metrics.
Figure G
And that’s pretty much the basics of Apache Druid. Although we’ve only skimmed the surface of what this powerful data analytics platform can do, you should be able to get a pretty good feel of how it works by playing around with the sample data.
When you’re finished working, make sure to go back to the terminal window and stop the Apache Druid service with CTRL + C.
Interested in Ubuntu? Check out The Mastering Linux Development Bundle from TechRepublic Academy.
Subscribe to TechRepublic’s How To Make Tech Work on YouTube for all the latest tech advice for business pros from Jack Wallen.