


The Microsoft Office clients have been getting smarter for several years: the first version of Editor arrived in Word in 2016, based on Bing’s machine learning, and it’s now been extended to include the promised Ideas feature with extra capabilities. More and more of the new Office features in the various Microsoft 365 subscriptions are underpinned by machine learning.
You get the basic spelling and grammar checking in any version of Word. But if you have a subscription, Word, Outlook and a new Microsoft Editor browser extension will be able to warn you if you’re phrasing something badly, using gendered idioms so common that you may not notice who they exclude, hewing so closely to the way your research sources phrased something that you need to either write it in your own words or enter a citation, or just not sticking to your chosen punctuation rules.
SEE: Choosing your Windows 7 exit strategy: Four options (TechRepublic Premium)
Must-read Windows coverage
- CrowdStrike Outage Disrupts Microsoft Systems Worldwide
- 10 Best Project Management Software for Windows in 2024
- Windows 10 Extended Security Updates Promised for Small Businesses and Home Users
- Securing Windows Policy
Word can use the real-world number comparisons that Bing has had for a while to make large numbers more comprehensible. It can also translate the acronyms you use inside your organization — and distinguish them from what someone in another industry would mean by them. It can even recognise that those few words in bold are a heading and ask if you want to switch to a heading style so they show up in the table of contents.
Outlook on iOS uses machine learning to turn the timestamp on an email to a friendlier ‘half an hour ago’ when you have it read out your messages. Mobile and web Outlook use machine learning and natural-language processing to suggest three quick replies for some messages, which might include scheduling a meeting.
Excel has the same natural-language queries for spreadsheets as Power BI, letting you ask questions about your data. PowerPoint Designer can automatically crop pictures, put them in the right place on the slide and suggest a layout and design; it uses machine learning for text and slide structure analysis, image categorisation, recommending content to include and ranking the layout suggestions it makes. The Presenter Coach tells you if you’re slouching, talking in a monotone or staring down at your screen all the time while you’re talking, using machine learning to analyse your voice and posture from your webcam.
Machine learning anyone can use
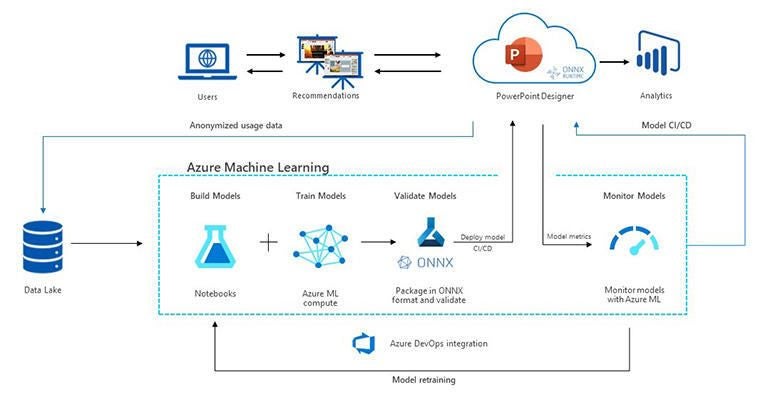
Many of these features are built using the Azure Machine Learning service, Erez Barak, partner group program manager for AI Platform Management, told TechRepublic. At the other extreme, some call the pre-built Azure Cognitive Services APIs for things like speech recognition in the presentation coach, as well as captioning PowerPoint presentations in real-time and live translation into 60-plus languages (and those APIs are themselves built using AML).
Other features are based on customising pre-trained models like Turing Neural Language Generation, a seventeen-billion parameter deep-learning language model that can answer questions, complete sentences and summarize text — useful for suggesting alternative phrases in Editor or email replies in Outlook. “We use those models in Office after applying some transfer learning to customise them,” Barak explained. “We leverage a lot of data, not directly but by the transfer learning we do; that’s based on big data to give us a strong natural-language understanding base. For everything we do in Office requires that context; we try to leverage the data we have from big models — from the Turing model especially given its size and its leadership position in the market — in order to solve for specific Office problems.”
AML is a machine-learning platform for both Microsoft product teams and customers to build intelligent features that can plug into business processes. It provides automated pipelines that take large amounts of data stored in Azure Data Lake, merge and pre-process the raw data, and feed them into distributed training running in parallel across multiple VMs and GPUs. The machine-learning version of the automated deployment common in DevOps is known as MLOps. Office machine-learning models are often built using frameworks like PyTorch or TensorFlow; the PowerPoint team uses a lot of Python and Jupiter notebooks.
The Office data scientists experiment with multiple different models and variations; the best model then gets stored back into Azure Data Lake and downloaded into AML using the ONNX Runtime (open-sourced by Microsoft) to run in production without having to be rebuilt. “Packaging the models in the ONNX Runtime, especially for PowerPoint Designer, helps us to normalise the models, which is great for MLOps; as you tie these into pipelines, the more normalised assets you have, the easier, simpler and more productive that process becomes,” said Barak.
ONNX also helps with performance when it comes to running the models in Office, especially for Designer. “If you think about the number of inference calls or scoring calls happening, performance is key: every small percentage and sub-percentage point matters,” Barak pointed out.
A tool like Designer that’s suggesting background images and videos to use as content needs a lot of compute and GPU to be fast enough. Some of the Turing models are so large that they run on the FPGA-powered Brainwave hardware inside Azure because otherwise they’d be too slow for workloads like answering questions in Bing searches. Office uses the AML compute layer for training and production which, Barak said, “provides normalised access to different types of compute, different types of machines, and also provides a normalised view into the performance of those machines”.
“Office’s training needs are pretty much bleeding edge: think long-running, GPU-powered, high-bandwidth training jobs that could run for days, sometimes for weeks, across multiple cores, and require a high level of visibility into the end process as well as a high level of reliability,” Barak explained. “We leverage a lot of high-performing GPUs for both training the base models and transfer learning.” Although the size of training data varies between the scenarios, Barak estimates that fine-tuning the Turing base model with six months of data would use 30-50TB of data (on top of the data used to train the original model).
Repeatable, compliant data access
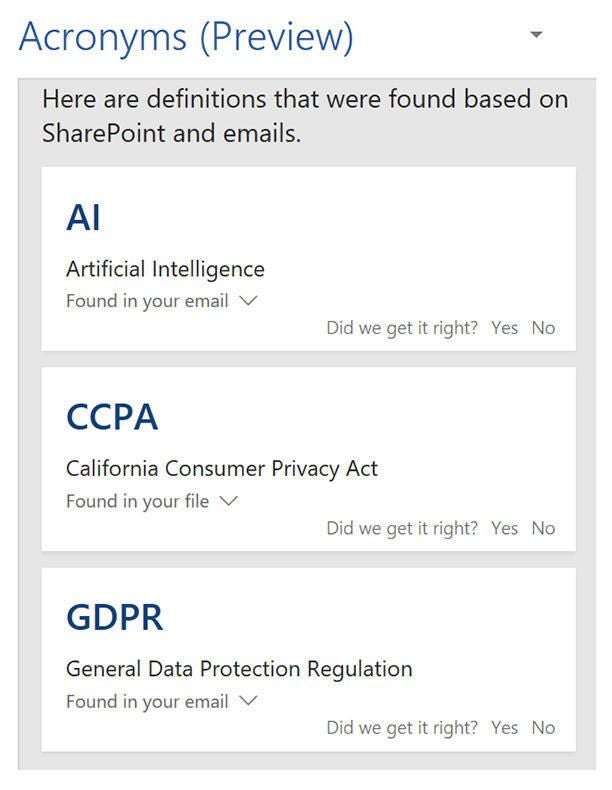
Image: Mary Branscombe/TechRepublic
The data used to train Editor’s rewrite suggestions includes documents written by people with dyslexia, and many of the Office AI features use anonymised usage data from Office 365 usage. Acronyms is one of the few features that specifically uses your own Office 365 data, because it needs to find out which acronyms your organisation uses, but that isn’t shared with any other Office users. Microsoft also uses public data for many features rather than trying to mine that from private Office documents. The similarity checker uses Bing data, and Editor’s sentence rewrite uses public data like Wikipedia as well as public news data to train on.
As the home of so many documents, Office 365 has a wealth of data, but it also has strong compliance policies and processes that Microsoft’s data scientists must follow. Those policies change over time as laws change or Office gets accredited to new standards — “think of it as a moving target of policies and commitments Office has made in the past and will continue to make,” Barak suggested. “In order for us to leverage a subset of the Office data in machine learning, naturally, we adhere to all those compliance promises.”
LEARN MORE: Office 365 Consumer pricing and features
But models like those used in Presentation Designer need frequent retraining (at least every month) to deal with new data, such as which of the millions of slide designs it suggests get accepted and are retained in presentations. That data is anonymised before it’s used for training, and the training is automated with AML pipelines. But it’s important to score retrained models consistently with existing models so you can tell when there’s an improvement, or if an experiment didn’t pan out, so data scientists need repeated access to data.
“People continuously use that, so we continuously have new data around people’s preferences and choices, and we want to continuously retrain. We can’t have a system that needs to be adjusted over and over again, especially in the world of compliance. We need to have a system that’s automatable. That’s reproducible — and frankly, easy enough for those users to use,” Barak said.
“They’re using AML Data Sets, which allow them to access this data while using the right policies and guard rails, so they’re not creating copies of the data — which is a key piece of keeping the compliance and trust promise we make to customers. Think of them as pointers and views into subsets of the data that data scientists want to use for machine learning.
“It’s not just about access; it’s about repeatable access, when the data scientists say ‘let’s bring in that bigger model, let’s do some transfer learning using the data’. It’s very dynamic: there’s new data because there’s more activity or more people [using it]. Then the big models get refreshed on a regular basis. We don’t just have one version of the Turing model and then we’re done with it; we have continuous versions of that model which we want to put in the hands of data scientists with an end-to-end lifecycle.”
Those data sets can be shared without the risk of losing track of the data, which means other data scientists can run experiments on the same data sets. This makes it easier for them to get started developing a new machine-learning model.
Getting AML right for Microsoft product teams also helps enterprises who want to use AML for their own systems. “If we nail the likes and complexities of Office, we enable them to use machine learning in multiple business processes,” Barak said. “And at the same time we learn a lot about automation and requirements around compliance that also very much applies to a lot of our third-party customers.”