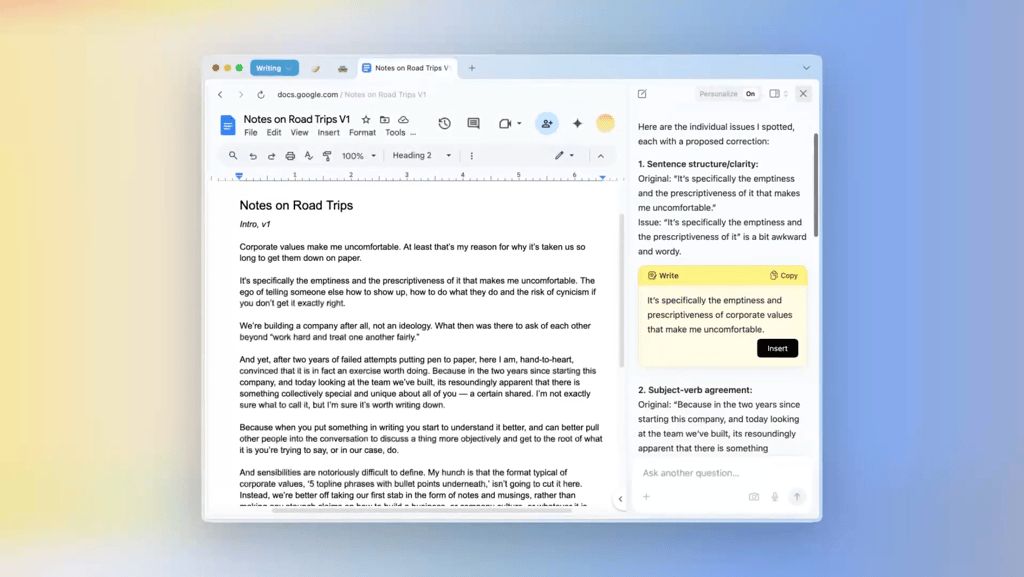
Researchers found that seven of nine tested Hugging Face image-editing tools produced sexualized alterations, highlighting gaps in model oversight, provenance, and enterprise vendor controls.