



Image: BEST-BACKGROUNDS/Shutterstock
Must-read developer coverage
- What Powers Your Databases? Take This DZone Survey Today!
- Microsoft’s Historic 6502 BASIC Code is Now Open Source
- TIOBE Index: Top 10 Most Popular Programming Languages
- TechRepublic Exclusive: AWS Says Entry-Level Workers Need ‘Curiosity’ In the Age of AI
CSV files are often imported into Excel or LibreOffice software before being used and analyzed. It is very convenient and comfortable, as long as the files are not too big. But some log files might contain billions of lines, which makes it impossible to import it into spreadsheets. Or you might need to analyze files remotely on headless servers without any ability to use a graphical user interface.
SEE: Hiring Kit: JavaScript Developer (TechRepublic Premium)
Luckily, an easy solution is available on all Linux operating systems: the csvkit software.
How to install csvkit
With the tool being available in the standard repositories, it is extremely easy to install. In this article, we’ll use an Ubuntu-based operating system.
Let’s issue the installation in a command-line shell by executing:
sudo apt install csvkit
That’s it. The system now installs the tool and all the necessary dependencies.
How to work on a CSV file
To illustrate our point, we’ll work on a CSV file from SimpleMaps.com containing a list of cities and information about them: country, longitude, latitude, population and more.
The first line of the CSV file shows the different column names, as is often the case with CSV files. We can see it with the “head” command, which by default shows the first 10 lines of a file (Figure A).
Figure A

How to figure out the columns of the file
Now let’s start using csvcut from the command-line, one of the tools embedded in the csvkit. Launching the next command will automatically show the named columns and the indices (Figure B):
csvcut -n
Figure B
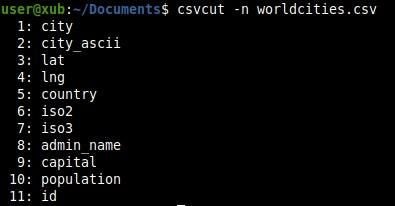
We might then use either the indices or the column names to address it.
How to output selected columns
One of the most common operations when dealing with CSV files consists of selecting just a few columns, or reorganizing columns.
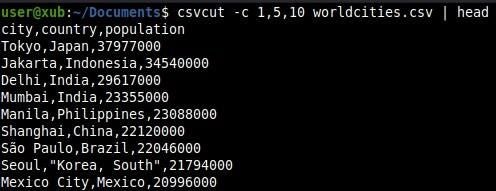
To output just a few columns, let’s once again use the csvcut command with the -c option. Both command lines work, to show how to use both the indices or the column name. In our example, we’ll once again use the head command with a pipe, just to show the first lines of the results (Figure C).
csvcut -c 1,5,10
csvcut -c city,country,population
Figure C
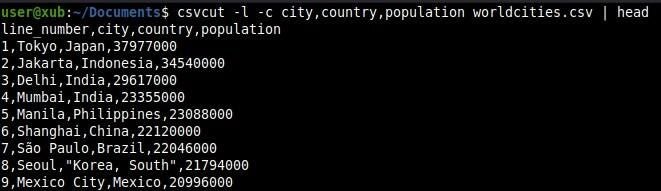
Should we want line numbers added to the output, option -l comes to rescue and adds a new column named line_number to our output (Figure D).
Figure D
Output can of course be redirected to a new file. To do this, we redirect the output to a file by using the > character. From our previous example:
csvcut -l -c city,country,population worldcities.csv > newfile.csv
How to change the column order
Using csvcut we can also create an output that reorders the columns. All we need is to specify the columns, and the tool will display it accordingly (Figure E).
Figure E
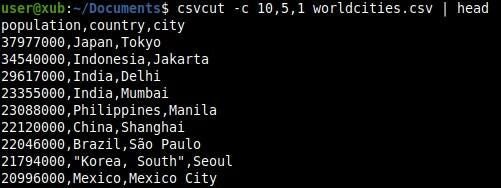
How to sort the data with csvsort
It is possible to sort data using the csvsort command. Similar to csvcut, csvsort allows the use of option -n to list columns, and -c to use either the column index or the column name.
By default, csvsort works in ascending mode, but it is possible to use the -r option to sort in descending mode.
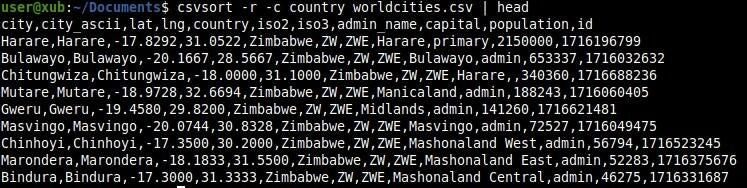
Let’s sort our file by country name, in descending order (Figure F):
csvsort -r -c country worldwities.csv
Figure F
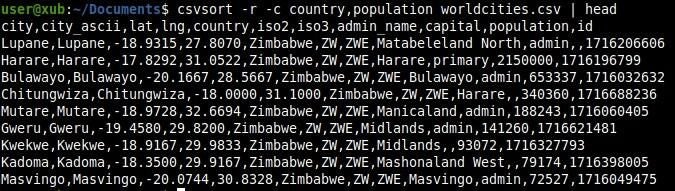
It is possible to sort multiple columns: All you need is to use them with the -c option (Figure G). The next line will sort our data in descending mode by country and by population:
csvsort -r -c country,population worldcities.csv
Figure G
How to combine csvcut and csvsort
Csvsort is powerful but it always outputs all the columns. By combining csvcut and csvsort, we can achieve any kind of outputting or sorting.
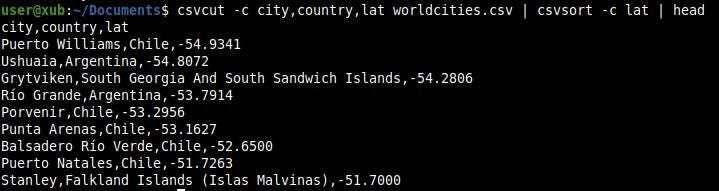
As an example, let’s extract only the city name, country name, latitude, longitude, and sort those columns by latitude (Figure H).
csvcut -c city,country,lat worldcities.csv | csvsort -c lat
Figure H
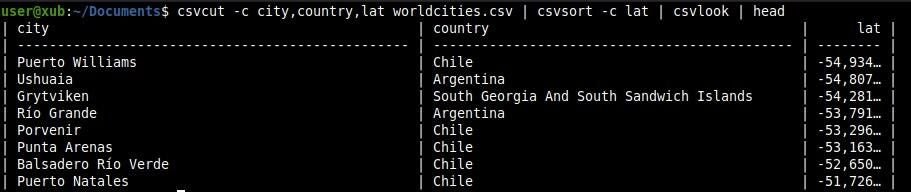
How to get a nicer output
Should you want a nicer output, command csvlook allows you to render the CSV output in a Markdown-compatible, fixed-width format.
From our previous example, we just pipe the csvlook command to the end of our line (Figure I):
csvcut -c city,country,lat worldcities.csv | csvsort -c lat | csvlook
Figure I
How to get statistics with csvstat
The csvstat command allows you to get different statistics on the CSV file.
Run without arguments except the filename, it provides detailed statistics for each column. It is also possible to use the -c option to output selected columns (Figure J).
csvstat -c country
Figure J
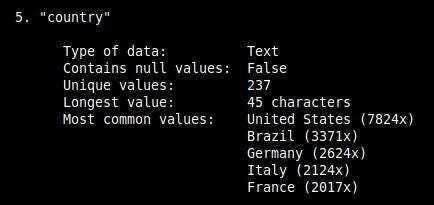
It is possible to tune the output of the command by using different options.
To extract the unique values of the country column, we may use the –unique option (Figure K).
Figure K

For a list of all options of csvstat, please type the following command:
csvstat -h
Csvkit contains several different command-line tools that allow IT specialists and people who need to work on large CSV files to do it easily in the command-line. The ability to combine these tools, especially csvcut and csvsort, makes it very powerful and should suit all needs of professionals.
Additionally, it is also possible to use csvkit for converting XLS and JSON files to CSV before analyzing or using them with the command-line tools.
Disclosure: I work for Trend Micro, but the views expressed in this article are mine.