


There are several ways to find duplicates in a Microsoft Excel sheet. You can use functions, conditional formatting, filtering and more. Microsoft Excel even offers a built-in feature that will find and delete duplicates for you. If you’re working with a large amount of data or importing data into Power BI, you might want to consider using Power Query to denote duplicates, without deleting them.
In this tutorial, I’ll show you how to use Microsoft Power Query to find duplicates in Excel data. The benefit is that the process requires no special knowledge of functions or conditional formatting. You can download the demo for this Power Query tutorial.
SEE: Feature comparison: Time tracking software and systems (TechRepublic Premium)
I’m using Microsoft 365 on a Windows 10 64-bit system, but you can use earlier versions through Excel 2010.
How to connect to Power Query
The first step to using Power Query with Excel data is to make a connection between the two, which is simple; however, Power Query requires that you format the data as a Table object. You don’t have to worry about it though because when you start the process, Excel will prompt you to convert a data range into a Table if necessary.
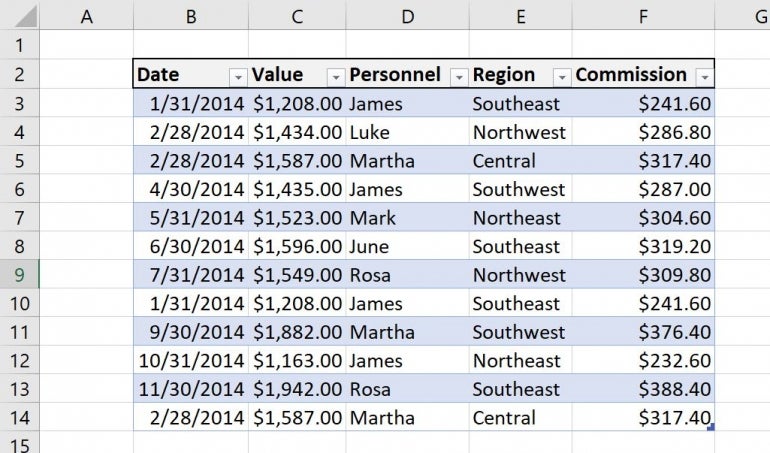
Next, you identify the Excel data, which contains duplicate records, as shown in Figure A, by doing the following:
- Click anywhere inside the Table or data range and then click the Data tab. If prompted to create a Table, click OK.
- In the Get & Transform Data group, click From Table/Range.
Figure A
That’s it. As you can see in Figure B, the data is now in Power Query.
Figure B
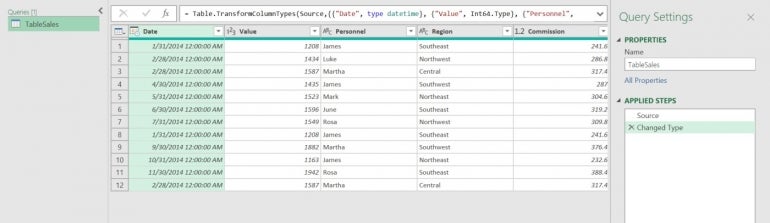
With the data in Power Query, it’s time to find the duplicates. There are two duplicate rows, which you can easily find by sorting, but you don’t have to sort when using Power Query.
How to label duplicates in Power Query
We don’t want to remove the duplicates. Instead, we want to label them in some way. We’ll add a new column that identifies duplicates in some way. This process is simpler than you might think.
First, we need to add an index column, which will make more sense later. For now, do the following:
- Click the Add Column tab.
- From the Index Column dropdown in the General group, choose From Zero.
Figure C
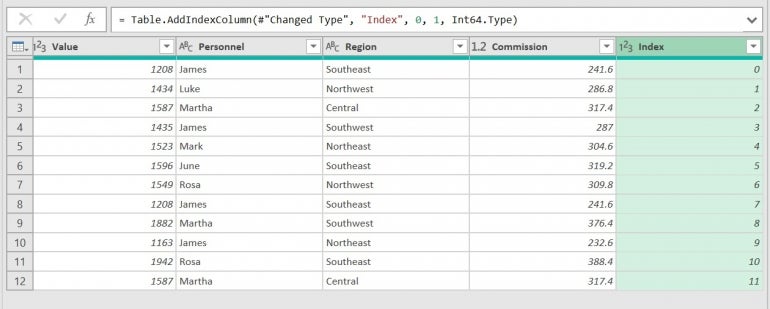
As you can see in Figure C, Power Query added an index column — a column of consecutive values that begin with 0.
Must-read Windows coverage
- CrowdStrike Outage Disrupts Microsoft Systems Worldwide
- 10 Best Project Management Software for Windows in 2024
- Windows 10 Extended Security Updates Promised for Small Businesses and Home Users
- Securing Windows Policy
Before we can identify duplicates, we must determine what constitutes the duplicate. We’ll use an advanced group based on the Date, Value and Personnel columns. The other two columns are irrelevant. Statistically, it isn’t impossible that the same employee might make two sales on the same day of the same value, but it’s not likely. In our simple data set, this is the best we can do because there isn’t a column that uniquely identifies each record, such as an invoice number.
First, we need to create this group:
- Select the Date, Value and Personnel rows by holding down Shift while you click each header.
- Click the Transform tab and then click Group By in the Table group. In the resulting dialog, Power Query populates the first three dropdowns with the selected column names.
- Name the column Find Duplicates and choose Count Rows from the Operation dropdown.
- Click Add Aggregation.
- Name the column Find Duplicates 2 and choose All Rows from the dropdown (Figure D).
- Click OK.
Figure D
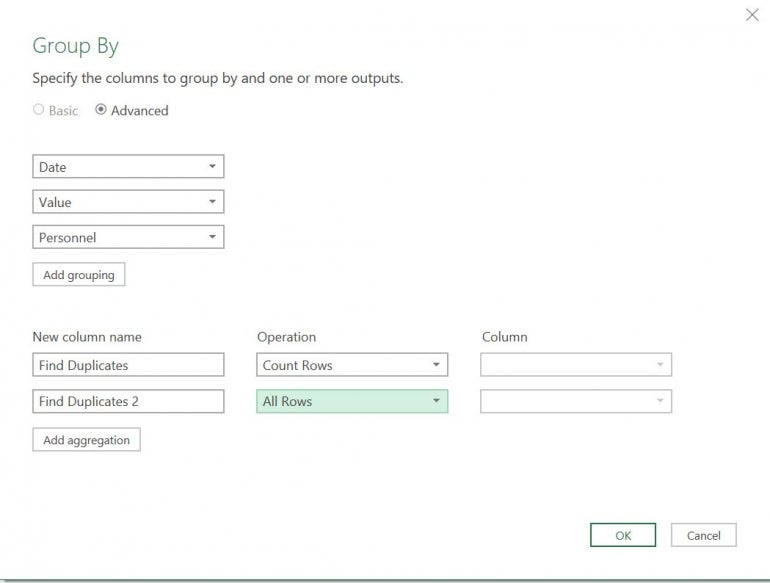
Figure E
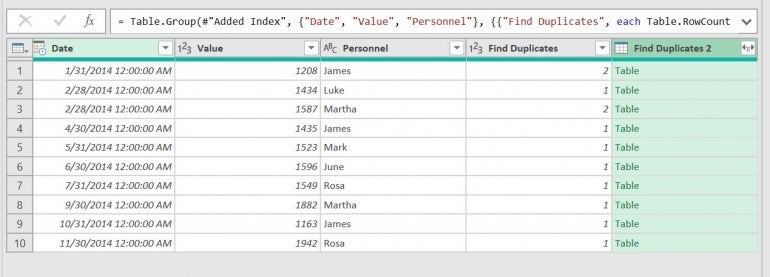
As you can see in Figure E, the Find Duplicates column returns the value 2 if the record has a duplicate. The Find Duplicates 2 column returns the term Table, which we’ll take care of later. What this query doesn’t do is display the duplicate records.
Currently, the table returns only unique records, which isn’t what we want. We want to keep all records, which is a simple task:
- Click the Expand button for the Find Duplicates 2 column.
- Uncheck the columns that make up the group: Date, Value and Personnel.
- Uncheck the Use Original Column Name As Prefix option if necessary (Figure F).
- Click OK.
Figure F
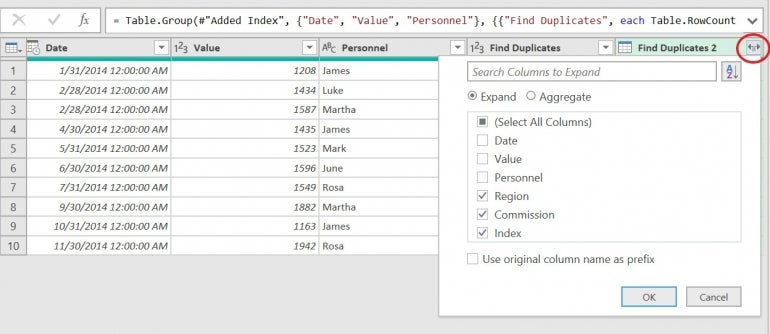
Figure G
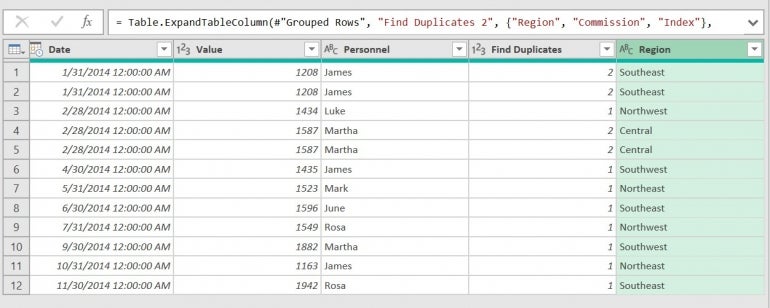
Now you can see all the records, as shown in Figure G. Currently, Power Query identifies duplicates with the value 2 in the Find Duplicates column and displays all duplicates. However, if you scroll to the right, you can see that the Index column is out of order. Obviously, Power Query sorted the records.
Earlier, I mentioned that adding this column would make sense later. This column allows you to maintain the original order, if necessary. Simply resort the Index column by clicking the Index column’s dropdown and choosing Sort Ascending. You can remove the Index column, but I’ll leave it.
With the duplicates identified and all the records visible, you can load the data to Excel.
How to load the data to Excel
Loading the data to Excel is a quick and easy step. On the Home tab, click Close and Load in the Close group. Then click Close and Load from the resulting dropdown. Power Query creates a new sheet based on the Table’s name, which in this case is TableSales, as shown in Figure H.
Figure H
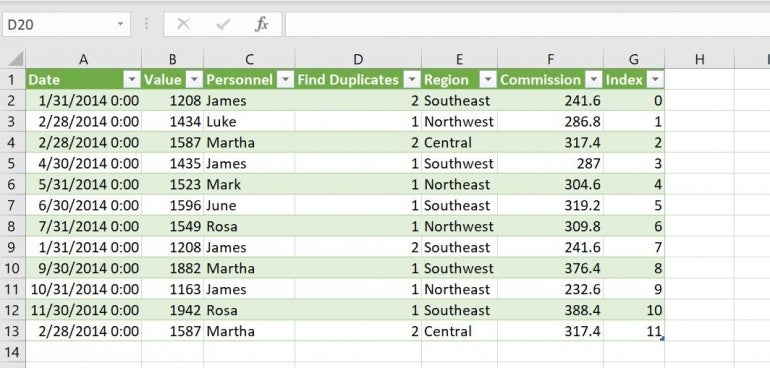
Once the data is back in Excel, you can use it the way you would any other data in Excel. You might want to add a conditional format that highlights the duplicates based on the Find Duplicates values of 1 and 2. The process for labeling the duplicates is easy and gives you the flexibility to display them or not in Excel.