


When you run commands on Linux, be they one at a time at the prompt or from a bash script, those commands run in sequence. The first command runs, followed by the second, followed by the third. Granted, the time between commands is so minuscule, the naked eye wouldn’t notice. For some instances, that may not be the most efficient means of running commands. If you find yourself in a situation where you need multiple commands to be run at exactly the same time (say on your data center Linux servers), what do you do?
More about data centers
- Stargate Norway: OpenAI’s First AI Data Center in Europe
- AI Data Centers’ Soaring Energy Use: Who Pays for Higher Utilities Costs?
- China’s Submerged AI Data Center Could ‘Influence Global Sustainable Computing’
- Google to Power Data Centers With Nuclear Energy by 2030 in First-Of-A-Kind’ Agreement
You turn to GNU Parallel.
What is GNU Parallel?
GNU Parallel is a shell tool that enables the execution of jobs in parallel using one or more computers. A job can be a single command or input from a file containing such things as a list of commands, a list of files, a list of hosts, a list of users, a list of URLs, or a list of tables. GNU Parallel can also take information from a piped command.
I want to show you how to install GNU Parallel and then the basics of its usage.
Installation
I will be demonstrating on a Ubuntu Server 16.04. GNU Parallel can be installed on nearly any Linux distribution, so if you’re using a distribution other than Ubuntu, you’ll need to modify the installation command to fit your platform.
Since GNU Parallel is found in the standard repository, installation is simple. Open up a terminal window and issue the command:
sudo apt install parallel
Once installation is complete, you’ll want to silence the citation banner. This is put in place to ensure anyone using GNU Parallel for publican cites the developers.
To silence the citation banner, issue the command parallel –bibtex. You will then be given the citation information and prompted to type will cite (Figure A).
Figure A
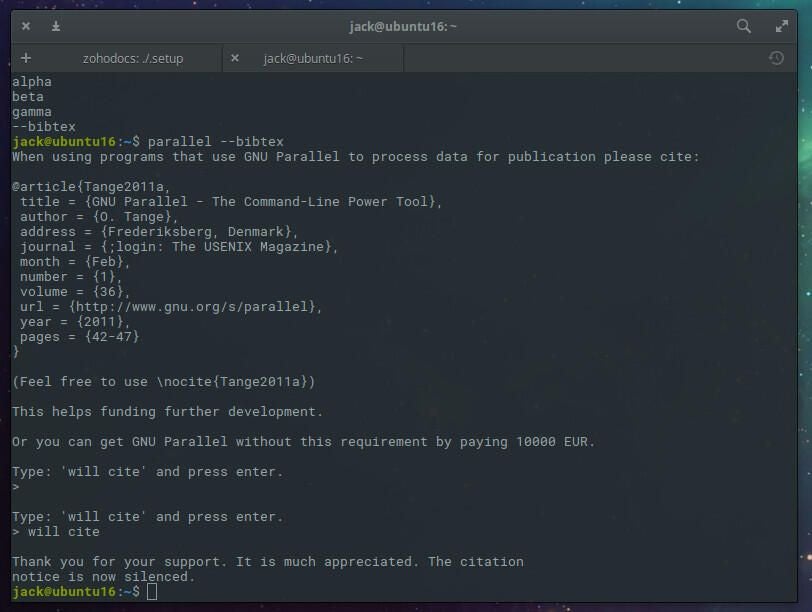
You’re now ready to use GNU Parallel.
SEE: How to find files in Linux with grep: 10 examples (free PDF) (TechRepublic)
Usage
The simplest way to demonstrate GNU Parallel is using the echo command. Let’s say we want to use the echo command to print out one two three four. The command for this would be:
echo "one two three four"
The output would look like that in Figure B.
Figure B
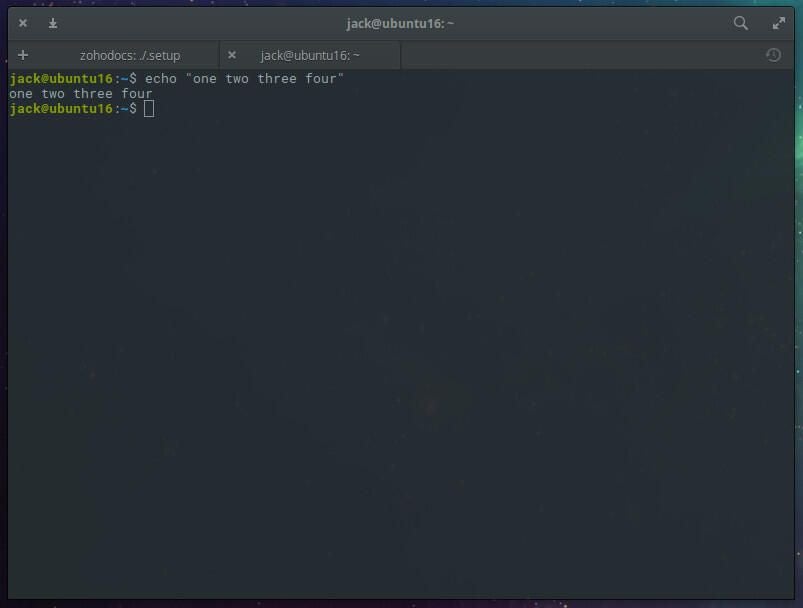
That same command, using parallel would be:
parallel echo ::: one two three four
The output for the above would look like that in Figure C.
Figure C
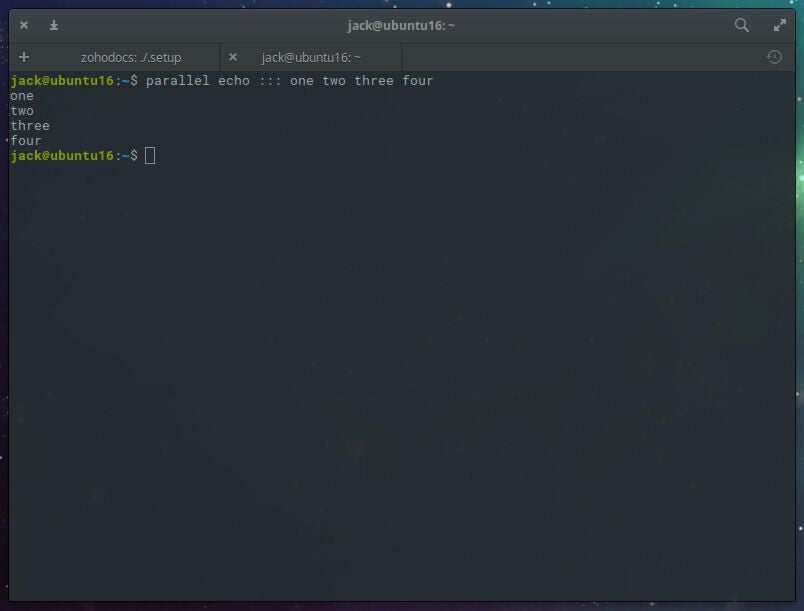
We could also give two pieces of input data like so:
parallel echo ::: 1 2 3 4 ::: A B C D
The output for the above command would look like that shown in Figure D.
Figure D
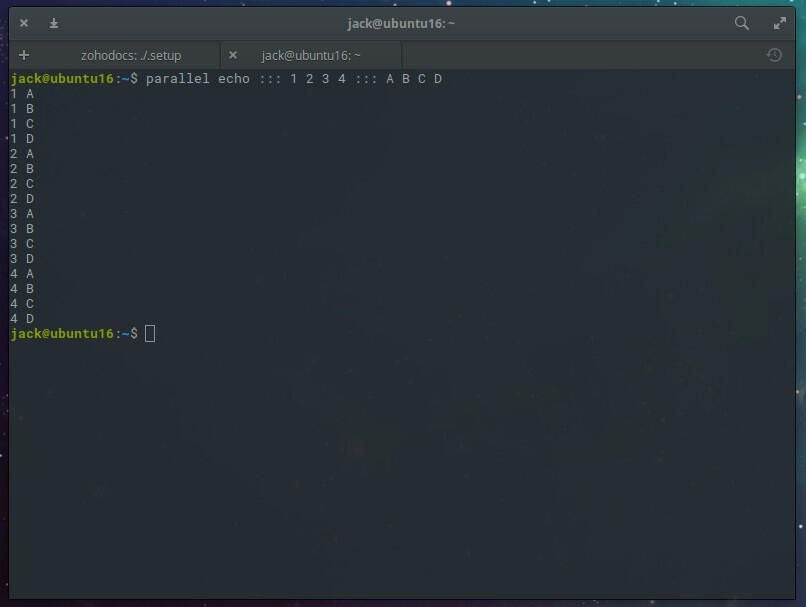
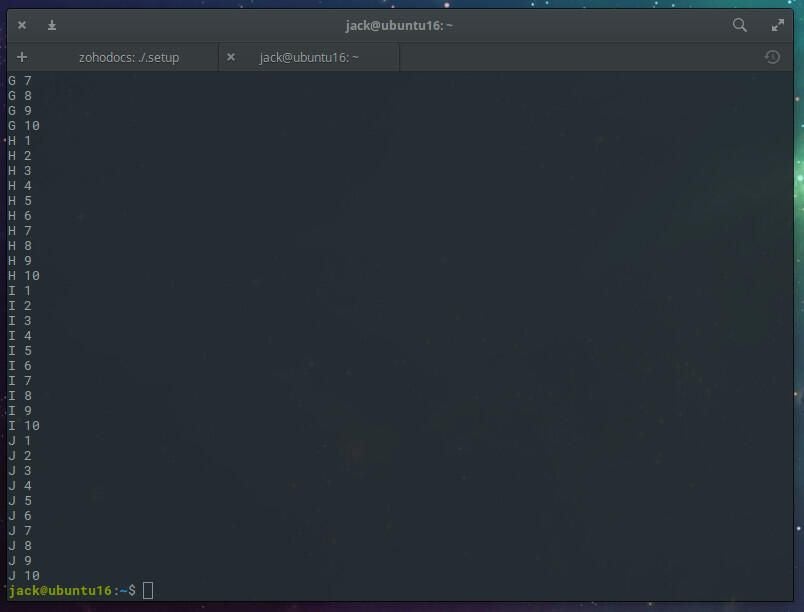
As you can see, we delineate the command from the input variables with the ::: characters. You can also use files as input for the command. Let me demonstrate. Create two files. The first, named abc-file with the contents:
A
B
C
D
E
F
G
H
I
K
The second file, named 123-file, will have the contents:
1
2
3
4
5
6
7
8
9
10
Now we use those two files to generate output. The command for this might look like:
parallel -a abc-file -a 123-file echo
The output would look like that shown in Figure E.
Figure E
If your input files aren’t the same length, what do you do? GNU Parallel will wrap the output of the shorter file, so it will match up with the longer file. The output will be similar to that in Figure E (above). However, what if we want to gain a bit more control of that output. Instead of GNU Parallel repeating (In order to match the inputs):
1 A
1 A
1 A
1 A
1 A
2 B
2 B
2 B
2 B
2 B
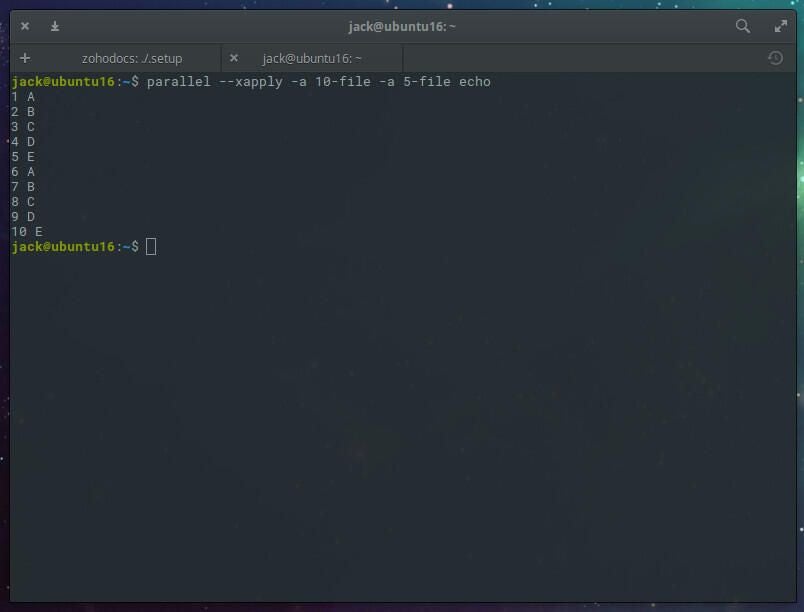
It is possible to make use of the -xapply argument. Say we have the 10-file with 10 lines of input (12345678910 — one number per line) and the 5-file with five lines of input (ABCDE — one number per line). Issue the command:
parallel --xapply -a 10-file -a 5-file echo
You will see that GNU Parallel will only print out the contents of 10-file once, but will repeat the contents of 5-file until it matches the length of 10-file ( Figure F).
Figure F
Usage with commands
So far we’ve just been using the echo command to output characters. Let’s see an example that actually uses commands. Say we have a directory called TEST. Inside that folder is a file called test and a subdirectory called 1 which contains the files test and test2. Let’s say we want to rename test to test1, rename test1 to test2, tar the 1 directory, and then rename the tarred directory. We could create a file with the following contents:
mv test test1
mv test1 test2
tar cfz 1.tar.gz 1
mv 1.tar.gz 2.tar.gz
Save and close that file, naming it jobs. Now we take input from jobs with the parallel command, like so:
parallel --jobs 4 < jobs
The –jobs option instructs GNU Parallel how many commands are allowed be to run. In our case, we have 4 commands. If there were more commands than allowed jobs, the remaining commands would be placed in a queue. Generally speaking, it’s safe to allow more jobs than you have commands. So issuing the command:
parallel --jobs 6 < jobs
Would be fine.
There will be no output from the command. If you change into the TEST directory, you’ll see that everything has changed, according to our input file of commands.
Scratching the surface
We’ve only just scratched the surface of GNU Parallel. I highly recommend you give the official GNU Parallel tutorial a read, and watch this video tutorial series on Yutube, so you can understand the complexities of the tool (of which there are many). But this will get you started on a path to helping your data center Linux servers use commands with more efficiency.
