



Image: iStockphoto/Svisio
Not all of the nine zettabytes of data storage that IDC predicts will be needed by 2024 will be holding information that needs to be stored for long periods of time; IoT sensor readings and app performance telemetry may not be useful enough to keep around for decades. But in business and science, there are large datasets that do need to be archived, whether that’s streams of information from the Large Hadron Collider or pension data (which, under UK law, has to be kept for the lifetime of everyone in the pension scheme).
SEE: Metaverse cheat sheet: Everything you need to know (free PDF) (TechRepublic)
More about Innovation
- Sovereign AI Explained
- The Rise of the AI-Native Factory
- Why Data Determines AI Success
- SS&C Intralinks DealCentre AI vs. Datasite: Which platform is built for the future of dealmaking?
In 2020, GitHub deposited 21TB of data in the Arctic Code Vault alongside manuscripts scanned from the Vatican Apostolic Library, using the PIQL digital preservation system that prints QR codes of compressed data onto strips of film that will still be readable in hundreds of years’ time. That’s much longer than the lifespan of tape archives, which need to be rewritten about every 30 years, but if you really want long-term storage, how about the molecule that already stores information for thousands of years–DNA–and could fit more than an exabyte of data into a single cubic inch? Instead of rooms full of tape cartridges, those nine zettabytes (plus the equipment to read and write them) would fit into a data center rack.
We already have equipment for synthesizing, copying and reading DNA for genetic sequencing and scientific research (and we’re not going to stop needing to do that, so the technology to read DNA won’t be obsolete in a few hundred years). “Using DNA enables us to take advantage of an ecosystem that’s already there and will be there for a long time,” said Karin Strauss, senior principal research manager at Microsoft.
Using DNA to store data needs a few extra steps, though, starting with encoding software that turns the usual ones and zeros of a digital file into the four bases (A, C, T and G) found in DNA and a DNA synthesizer that creates DNA chains with the right sequence of bases.
When you’re ready to read the information out, a DNA sequencer transcribes the sequence of bases in that DNA chain and decoding software turns it back into bytes.
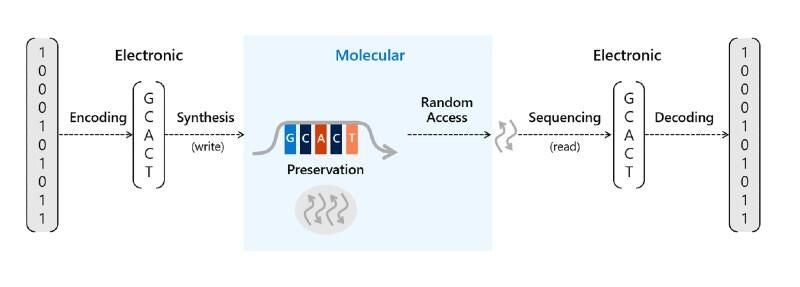
Image: Microsodft
To be able to write data into DNA fast enough to be useful, DNA storage technology needs to cope with at least kilobytes of data per second and ideally megabytes, which means you need to be able to write more than one chain of DNA at a time. As with CPUs, the key to speed–and bringing down the cost–is parallelism that packs more functionality into the same space.
“We can think about the four DNA bases as these little building blocks that you can just add on chemically,” said Bichlien Nguyen, senior researcher at Microsoft. “In DNA synthesis there’s a surface that’s an array of spots and those spots are where you add your A’s, C’s, T’s and G’s in specific orders to get them to create that DNA polymer.”
Bringing Moore’s Law to DNA storage
How many spots of DNA synthesis you can pack in without them interfering with each other dictates how many chains of DNA you can build at the same time (and you need to make multiple copies of each chain for redundancy). To put a new base onto the DNA chain, you first add the base and then use acid to get the chain ready for the next base, and you don’t want the base or the acid to get into the wrong spot.
Previous approaches have used tiny mirrors or patterns of light (called photomasks) instead of acid or sprayed tiny drops of acid on like ink from an inkjet printer. Taking another lesson from CPUs, Microsoft Research (working with the University of Washington) is using an array of electrodes in tiny glass wells, each surrounded by cathodes, to create the spots that DNA grows in and pack them a thousand times more closely together.
“What is really important is the distance—or the pitch—between those spots, and then also the size of those spots,” Nguyen said. “We have really shrunk down both the size of the spots going from about 20 microns down to 650 nanometers. And we’ve also shrunk down the pitch between them to two microns. And that allows us to pack in as many different spots on which we can grow different, unique DNA strands.”
Applying a voltage generates acid at the anode to get the DNA chain ready to attach the next base and also releases the right base to add to the chain at the cathode. If any acid does spill out of one glass well, it will flow into the base generated by the cathode and not be able to reach a different well.
SEE: Artificial Intelligence Ethics Policy (TechRepublic Premium)
That’s essentially a molecular controller and DNA writer on a chip, complete with a PCIe interface. Microsoft has it working, although it’s currently a proof of concept and used it to build four strands of synthetic DNA at once, storing a version of the company mission statement: “Empowering each person to store more!”
As a proof of concept rather than finished hardware, the tiny DNA writing mechanism is now producing strands that are 100 bases long. Longer strands showed more errors, but that can be improved as the hardware develops, perhaps by making the way the reagent fluids are delivered more sophisticated.
DNA data storage doesn’t need to be completely error free, any more than current storage systems are. There are multiple levels of redundancy built in, starting with growing multiple copies of the DNA, which Strauss calls physical redundancy: “We’re making many molecules that encode the same information.” There’s also error correction built in, using logical redundancy, which she said incurs roughly the same overhead as error-correcting memory: “For example, if all of the copies of the DNA that are being made in the same spot have an error, then you can correct it.”
“This work is about making the spot smaller, and the smaller you make the spot, the fewer copies you have. However, we’re still at the size where we have many, many copies of the DNA and so this is not a concern. In the future, you may end up with only a few copies of the DNA but we think there’s still quite a bit of room to reduce the size of this part and still maintain the minimum redundancy.”
With the proof-of-concept hardware, the write speed is the equivalent of 2KB/second. “We could scale that up by creating either more of those arrays or we could further shrink down the pitch and the size,” Nguyen said.
In future, Microsoft plans to add logic to control millions of electrode spots, using the same 130nm process node used to build this system. That’s what chip builders were using 20 years ago and moving to smaller, more modern processes will mean arrays can scale up to billions of electrodes and megabytes per second of data storage; closer to tape storage in both performance and cost.
“The more chunks of the same size that we can make the higher the write throughput,” Strauss added. “In order to do that, either you make smaller spots and you put more of them in the same area, or you increase the area, and area is proportional to cost. So the more you pack in, the lower the cost. You’re essentially amortising all the cost, over the higher number of DNA pieces.”
Throughput matters more than write speed
So far Microsoft has been optimising the bandwidth of writing DNA data, which she said is the more important measure, but there are also plans to improve the latency for reading.
“We think of DNA storage as something that’s going to be good for archival storage and in the cloud, at least initially. For writes, the latency is not as important because you could buffer the information in an electronic system and then write in batches, as we do here, and it doesn’t matter how long it takes to write as long as the throughput can keep up with the amount of information you’re storing.”
When you’re reading back DNA, latency will affect how long you have to wait to get the information, and current DNA sequencing techniques are also based on reading DNA in batches. “That has high latency but we’re seeing development of nanopore readers that are real time,” Strauss said, which will speed the process up.
Microsoft also plans to work on the chemistry of the solvents and reagents used with the DNA, which are now fossil-based. Switching to enzymes (which is the way DNA is built and read in animals and plants) will be more environmentally sustainable and it will also speed up the chemical reactions that actually build the DNA chain. “Enzyme reactions occur at much faster timescales than what could be achieved right now with chemical processes,” Nguyen said.
Being able to use electronics to control molecules like this is an exciting technology that could also be useful in many other areas beyond storage—everything from screening new drug treatments and finding disease biomarkers to detecting environmental pollutants—and having multiple uses would likely bring the cost down through economies of scale.
There are more than 40 companies in the DNA Data Storage Alliance, including familiar drive manufacturers like Seagate and Western Digital and tape experts like Quantum and Spectra Logic alongside bioscience organizations. Production systems for DNA storage are still some way off, Strauss cautioned. “There’s quite a bit of engineering that still needs to go into a commercial system, to get lower error rates, to make the system more automatic and integrated and so forth.”
But the research Microsoft is publishing here shows that large scale commercial DNA data archives are looking quite feasible.