


Must-read Windows coverage
- CrowdStrike Outage Disrupts Microsoft Systems Worldwide
- 10 Best Project Management Software for Windows in 2024
- Windows 10 Extended Security Updates Promised for Small Businesses and Home Users
- Securing Windows Policy
There are a number of ways to highlight duplicate values. Conditional formatting might be the most common method; you can choose a built-in format or use a rule to customize the format. What you’ll find though, is that most methods work directly with the source data. Creating a list of duplicate values that’s separate from the source data is a bit more difficult. Fortunately, thanks to Excel’s FILTER() dynamic array function, creating a list of duplicate values is easier than it once was. In this article, I’ll show you how to use FILTER() to create a list of duplicate values across two columns.
SEE: 83 Excel tips every user should master (TechRepublic)
I’m using Microsoft 365 on a Windows 10 64-bit system. (I recommend that you not upgrade to Windows 11 until all the kinks have been worked out unless you have a specific reason for doing so.) FILTER() is available only in Microsoft 365. For your convenience, you can download the .xlsx demonstration file.
About FILTER() in Excel
Displaying a filtered set in another location makes for easy reporting and works especially well in a dashboard setup. Until FILTER() was introduced, getting a filtered set in another location required a bit of effort and skill.
FILTER() is one of Microsoft 365’s new dynamic array functions. It supports what’s known as a spill range, which is the result of a dynamic array formula that returns multiple values—its output spills beyond the input cell. In short, a spill range is a range of calculated results from one function or expression. When you select any cell in a spill range, Excel highlights the entire range with a blue border. You will always find the formula in the topmost cell of that range.
This function uses the syntax
FILTER(array, include, [if_empty])
where array identifies the source data, include identifies the value(s) you want to see in the filtered data set, and the optional if_empty specifies the value to display when the result is an empty set.
As you’ll see, FILTER() is extremely flexible.
FILTER() across two columns for repeated values in Excel
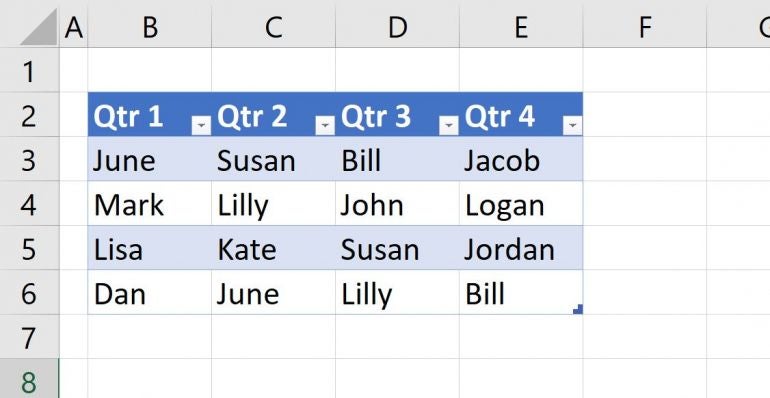
The simple Table object in Figure A duplicates a few names across four columns. Our task is to create a single list of values repeated across any two columns. We’ll start with quarters 1 and 2. With a quick glance, we can easily see that June is in both columns. In a much busier sheet, you’ll not want to depend on sight.
Figure A
First, let’s review the syntax for this task:
=FILTER(column2,COUNTIF(column1,column2)>0)where 1 and 2 denote the column positions from left to right. The first column2 reference identifies the source data for the FILTER() function. COUNTIF() returns TRUE if any value in column1 also occurs in column2.
Now, let’s apply this to the first two quarters by entering the following function in G3:
=FILTER(Table1[Qtr 2],COUNTIF(Table1[Qtr 1],Table1[Qtr 2])>0)
As you can see in Figure B, this expression returns June.
Figure B
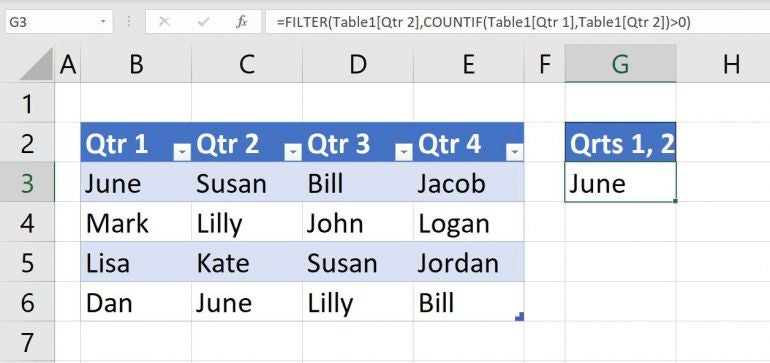
This expression returns any value that’s repeated in Qtr 1 and Qtr 2.
Because the references are relational, you can copy the expression in G3 to H3:I3 to return similar lists, as shown in Figure C. Specifically, the expression in H3 returns duplicates in quarters 2 and 3 and the expression in I3 returns duplicates in quarters 3 and 4.
Figure C
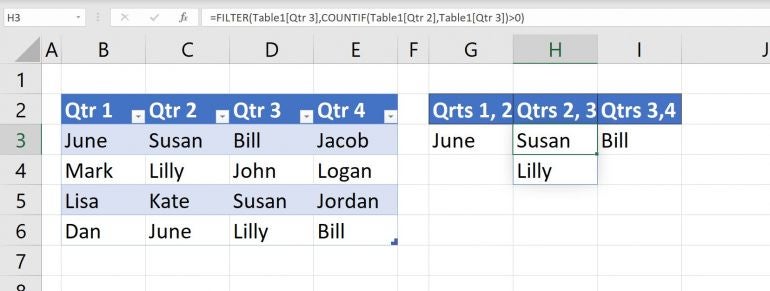
Copy the expression to create similar lists of repeated values.
Notice how the three expressions differ:
G3: =FILTER(Table1[Qtr 2],COUNTIF(Table1[Qtr 1],Table1[Qtr 2])>0)
H3: =FILTER(Table1[Qtr 3],COUNTIF(Table1[Qtr 2],Table1[Qtr 3])>0)
I3: =FILTER(Table1[Qtr 4],COUNTIF(Table1[Qtr 3],Table1[Qtr 4])>0)
Each column reference updates by one column; the expression in H3 evaluates quarters 2 and 3, and the expression in I3 evaluates quarters 3 and 4. Now, let’s break things down so you can see how this all works using the expression in G3:
=FILTER(Table1[Qtr 2],COUNTIF(Table1[Qtr 1],Table1[Qtr 2])>0)
=FILTER(Table1[Qtr 2],{0;0;0;1})>0)
=FILTER(Table1[Qtr 2],{FALSE,FALSE,FALSE,TRUE})
=FILTER({"Susan";"Lilly";"Kate";"June"},{FALSE,FALSE,FALSE,TRUE})
{"June"}
The COUNTIF() first returns an array of 0s and 1, where 1 indicates a repeated value and its position—the fourth value in Qtr 2. By adding the >0 component, this array returns FALSE and TRUE, where TRUE identifies the repeated value in the source data. Technically, >0 isn’t required, but it’s an easy way to document your intent, making later maintenance much easier.
FILTER()’s array reference returns the four values in Qrt 2: Susan, Lilly, Kate, and June. The only value that corresponds to a TRUE value is June, so the expression returns June.
The expression in H3 evaluates to =FILTER({“Bill”;”John”;”Susan”;”Lilly”},{FALSE;FALSE;TRUE;TRUE}), returning Susan and Lilly.
The expression I3 evaluates to =FILTER({“Jacob”;”Logan”;”Jordan”;”Bill”},{FALSE;FALSE;FALSE;TRUE}) returning only Bill.
H3 is the only expression that returns more than one value, and that list isn’t sorted. You can quickly fix this by adding SORT() to the expression in G3 in the form
=SORT(FILTER(Table1[Qtr 2],COUNTIF(Table1[Qtr 1],Table1[Qtr 2])>0))
and then copying it to H3:I3. Figure D shows the sorted list in column H.
Figure D
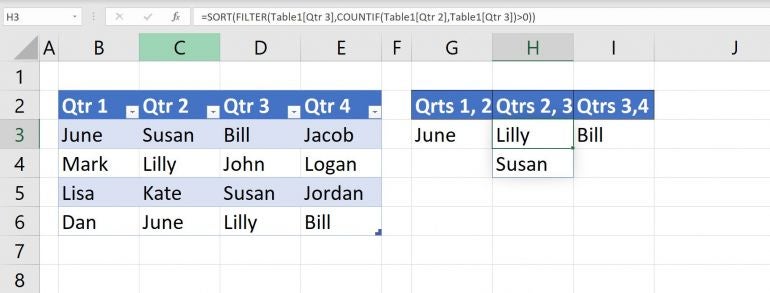
Add SORT() to sort the resulting lists.
As you update the source data, this expression will return sorted lists anytime there’s more than one value. This is possible only because the source data is a Table object. If you’re working with a normal data range, the expressions won’t update.