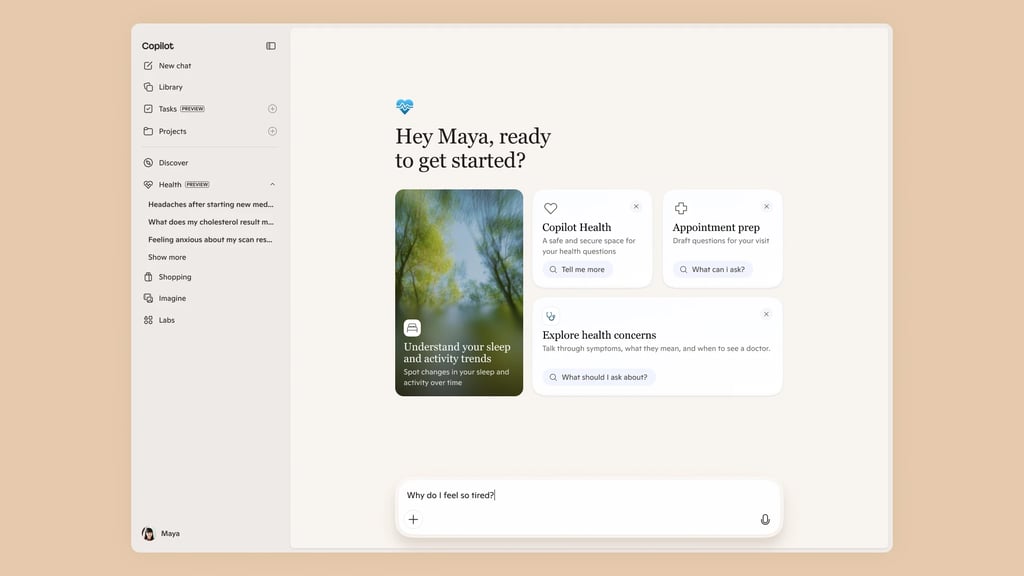
Samsung’s latest Health app update brings a redesigned wellness dashboard and new AI health tools, but current Galaxy Watch owners still need a compatibility list.