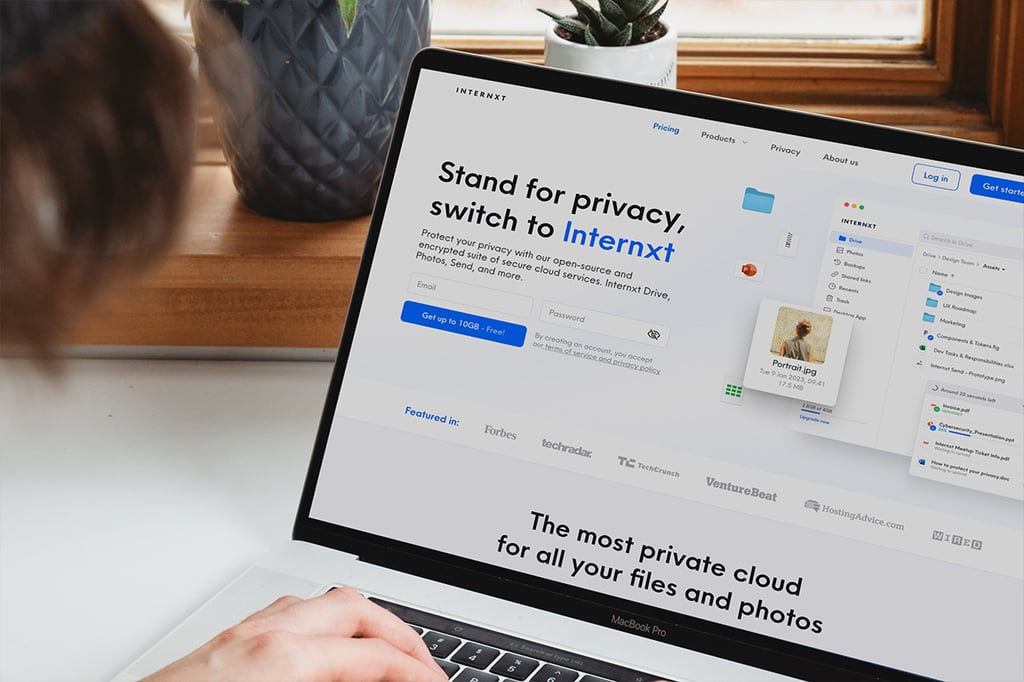
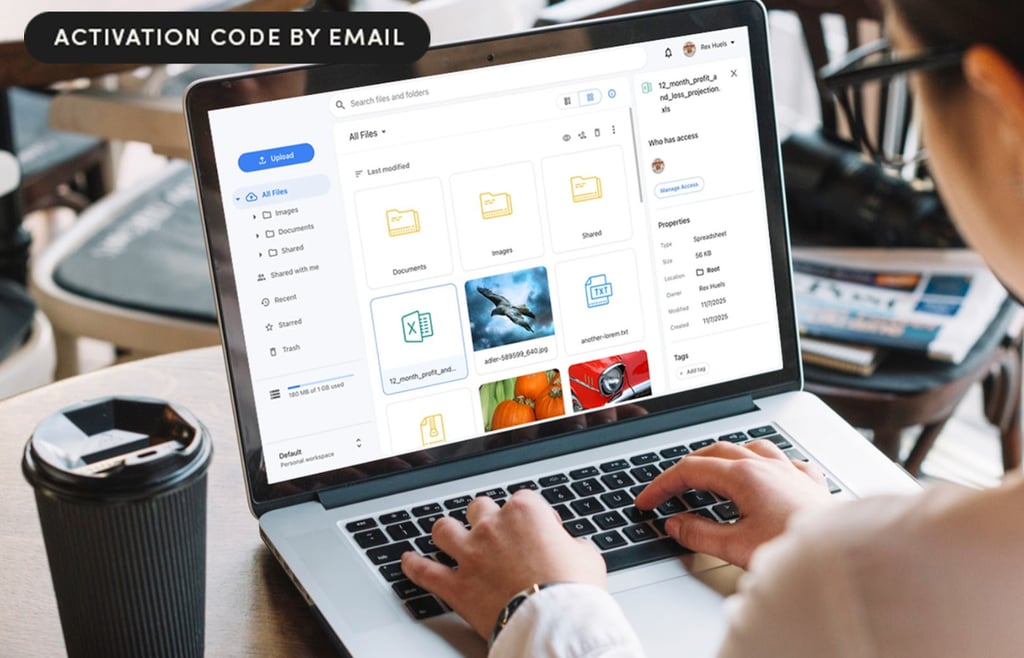
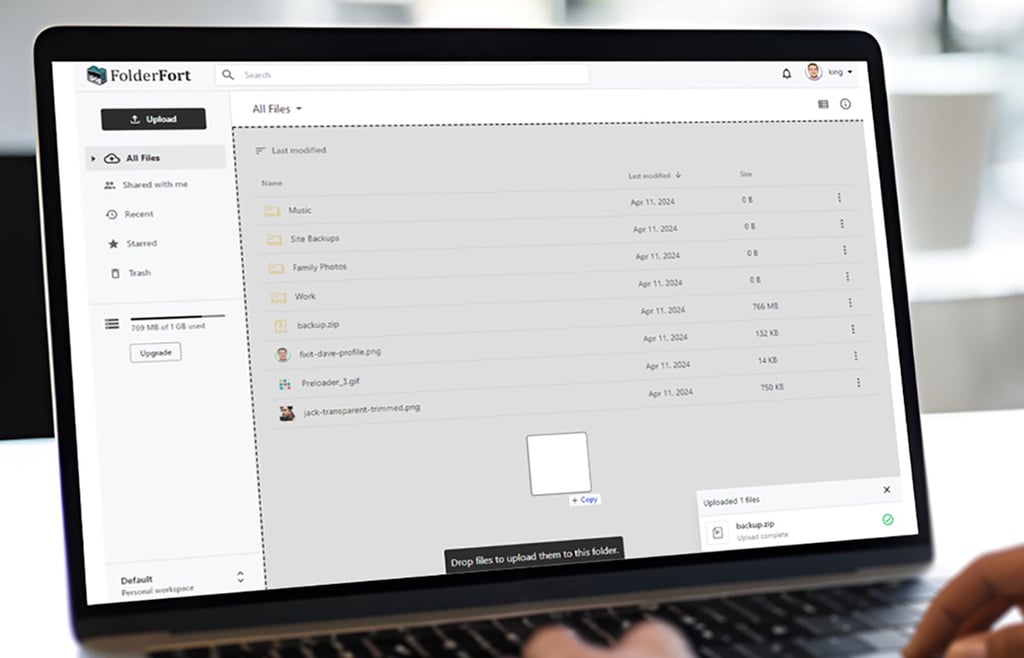
This secure storage platform uses open source code, zero-knowledge file systems, and end-to-end encryption to keep your online data truly private.